
AI Safety/Governance/Alignment/National security/Singularity/Superintelligence/AGI/X-Risk/prediction
https://t.co/MuWGjdu5Tg
INODS Research Fellow


 手法は以下の図。例えばタスクが「コーラを引き出しに入れる」だったら、その中からコーラと引き出しをセグメンテーションし、次に画像編集AIでセグメンテーションマスクとプロンプトを入力として、画像全体の一貫性をできるだけ保ちつつ新たな視覚入力を生成する。
手法は以下の図。例えばタスクが「コーラを引き出しに入れる」だったら、その中からコーラと引き出しをセグメンテーションし、次に画像編集AIでセグメンテーションマスクとプロンプトを入力として、画像全体の一貫性をできるだけ保ちつつ新たな視覚入力を生成する。 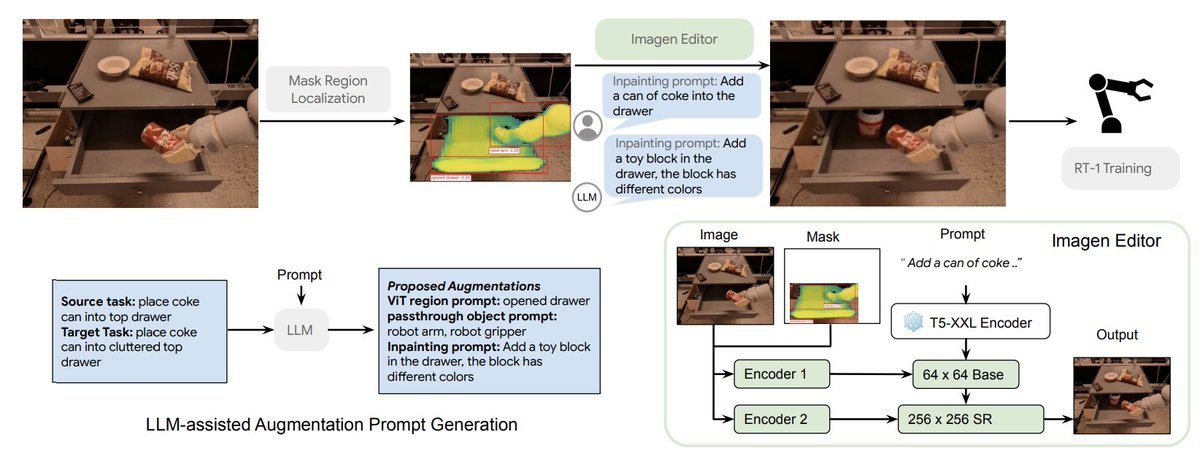
 theverge.com/2023/2/7/23587…
theverge.com/2023/2/7/23587…
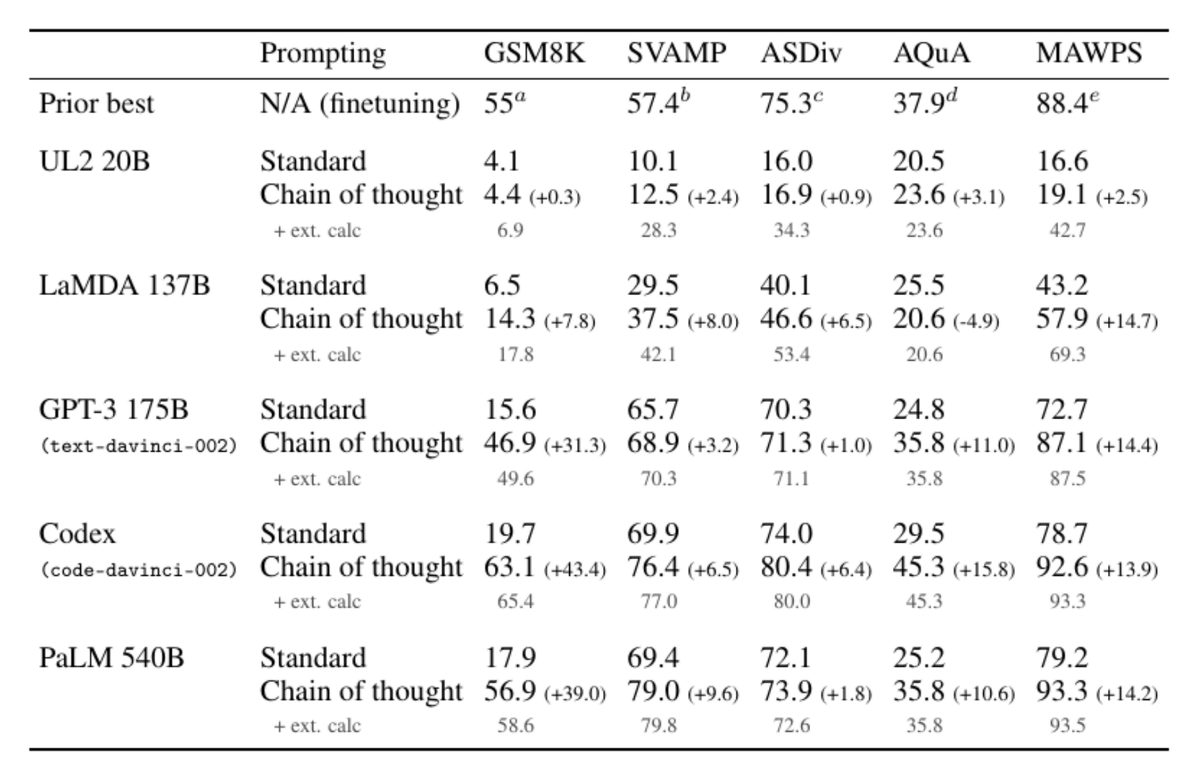
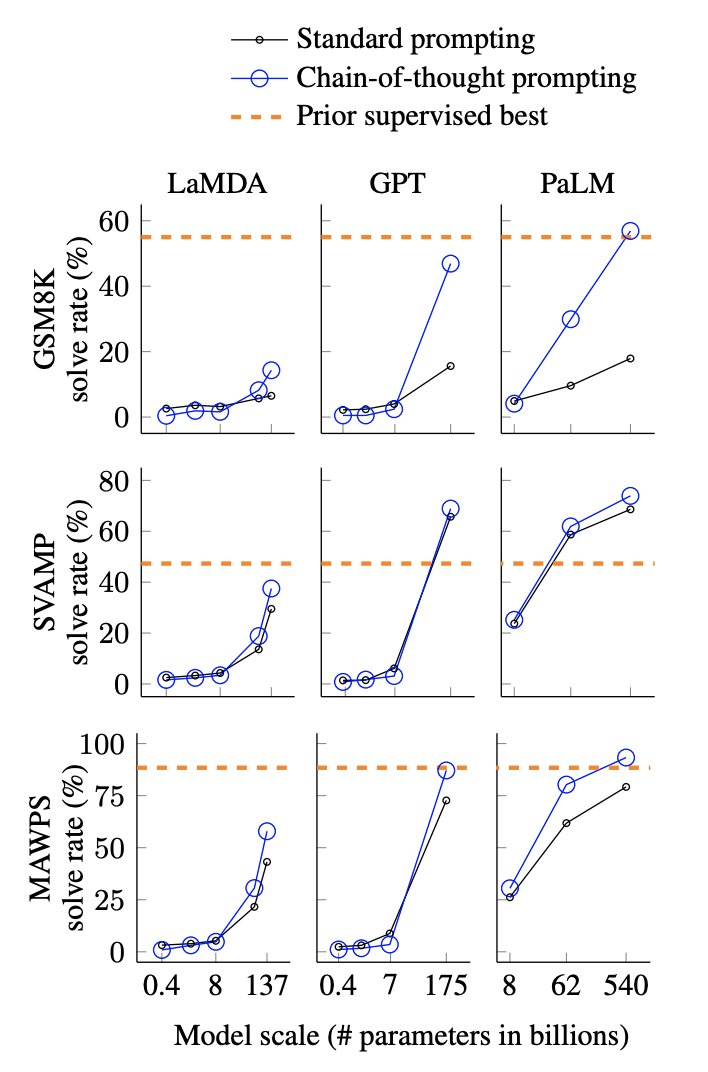 googleはLaMDAベースのBARDを数週間以内に出そうとしているけど、それだとMicrosoftのBing搭載されるCodexベースのGPT3.5以降の推論能力に負ける可能性があると思う。
googleはLaMDAベースのBARDを数週間以内に出そうとしているけど、それだとMicrosoftのBing搭載されるCodexベースのGPT3.5以降の推論能力に負ける可能性があると思う。