
AI @amazon Multimodal, Robotics, Semiconductors, Chinese AI, Aging society & Asian Century Strictly my views.
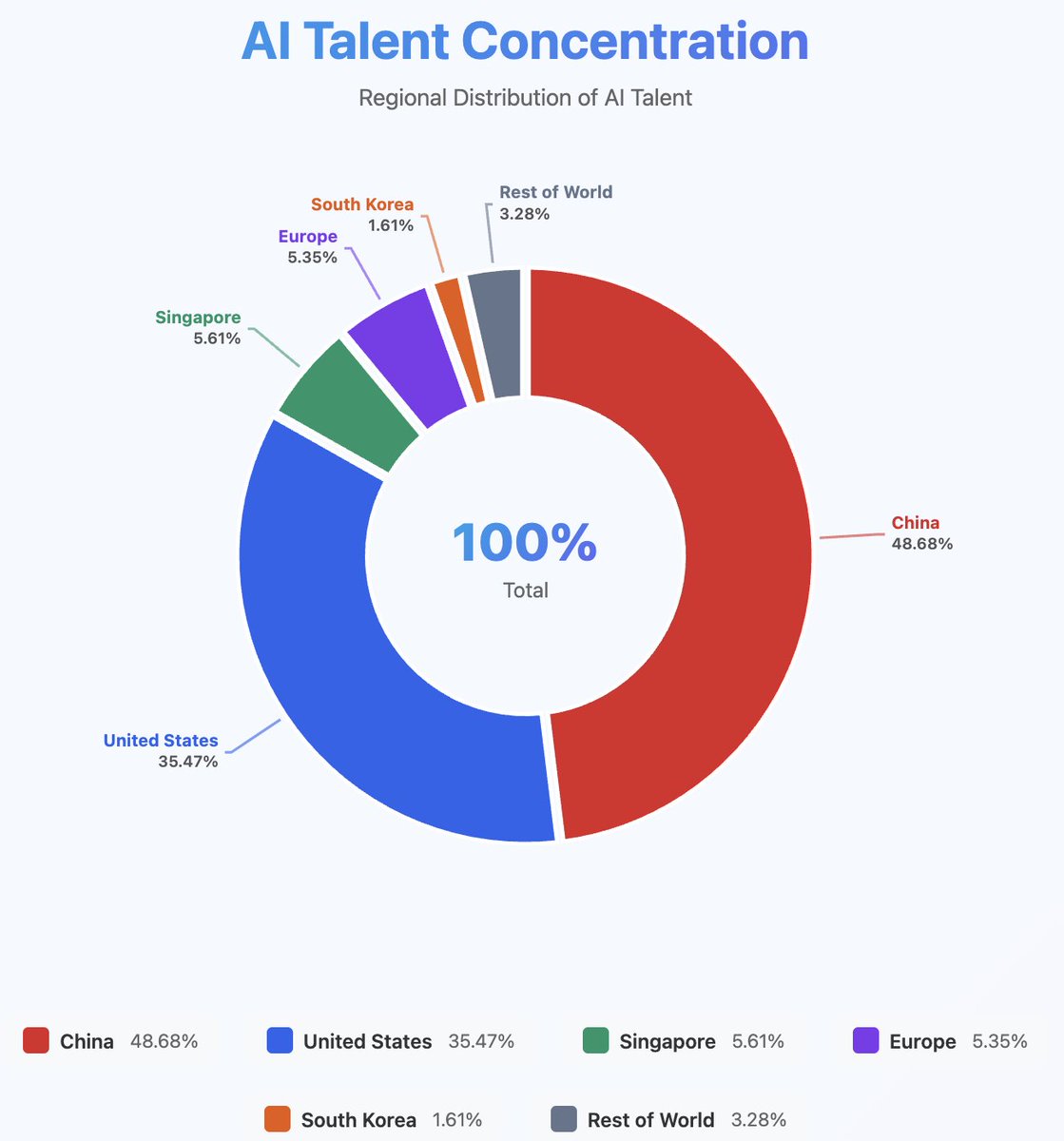 China AI talent density as fraction of global by metro regions:
China AI talent density as fraction of global by metro regions: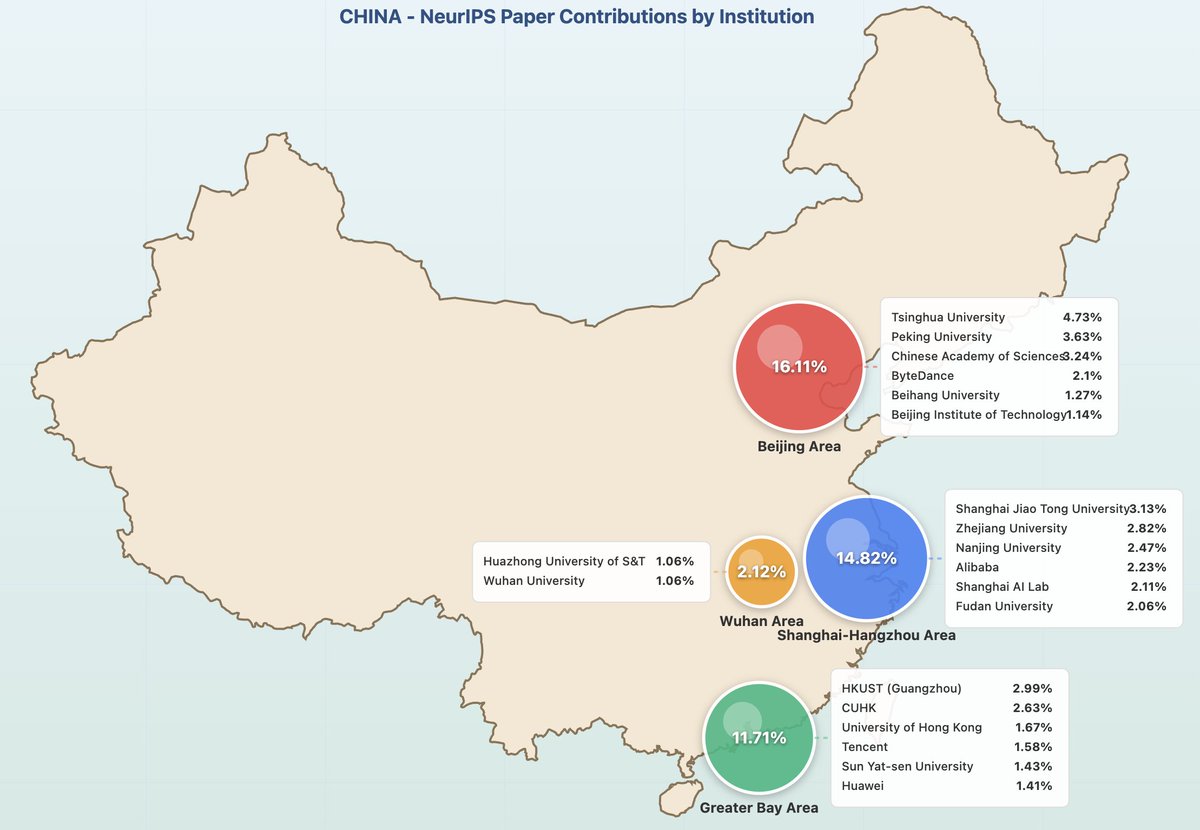
 Mind blow with Perplexity Pro Lab 🧵
Mind blow with Perplexity Pro Lab 🧵
