
 I am somewhat concerned about data leakage, see . This is an AlphaCode2 contributor's response
I am somewhat concerned about data leakage, see . This is an AlphaCode2 contributor's response  It's admittedly a bit difficult to know for sure since DP problems do sometimes tend to have more formulaic solutions.
It's admittedly a bit difficult to know for sure since DP problems do sometimes tend to have more formulaic solutions.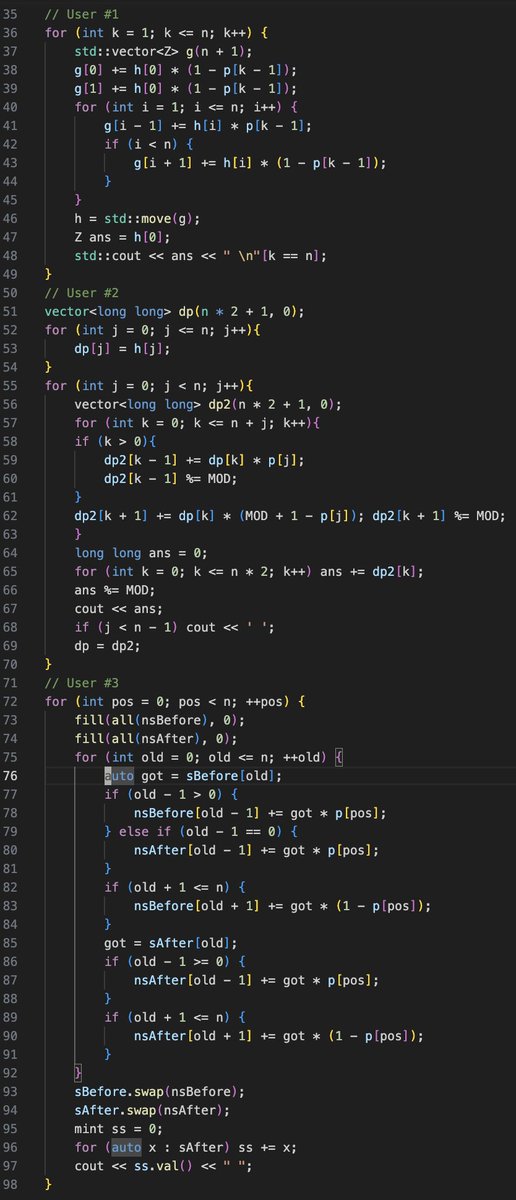


 800-rated problems are the easiest problems on Codeforces, and are determined automatically based off of the ratings of the people solving them during the contest. Thus, I would expect that these problems are roughly of "equal" difficulty, and my spot check would agree.
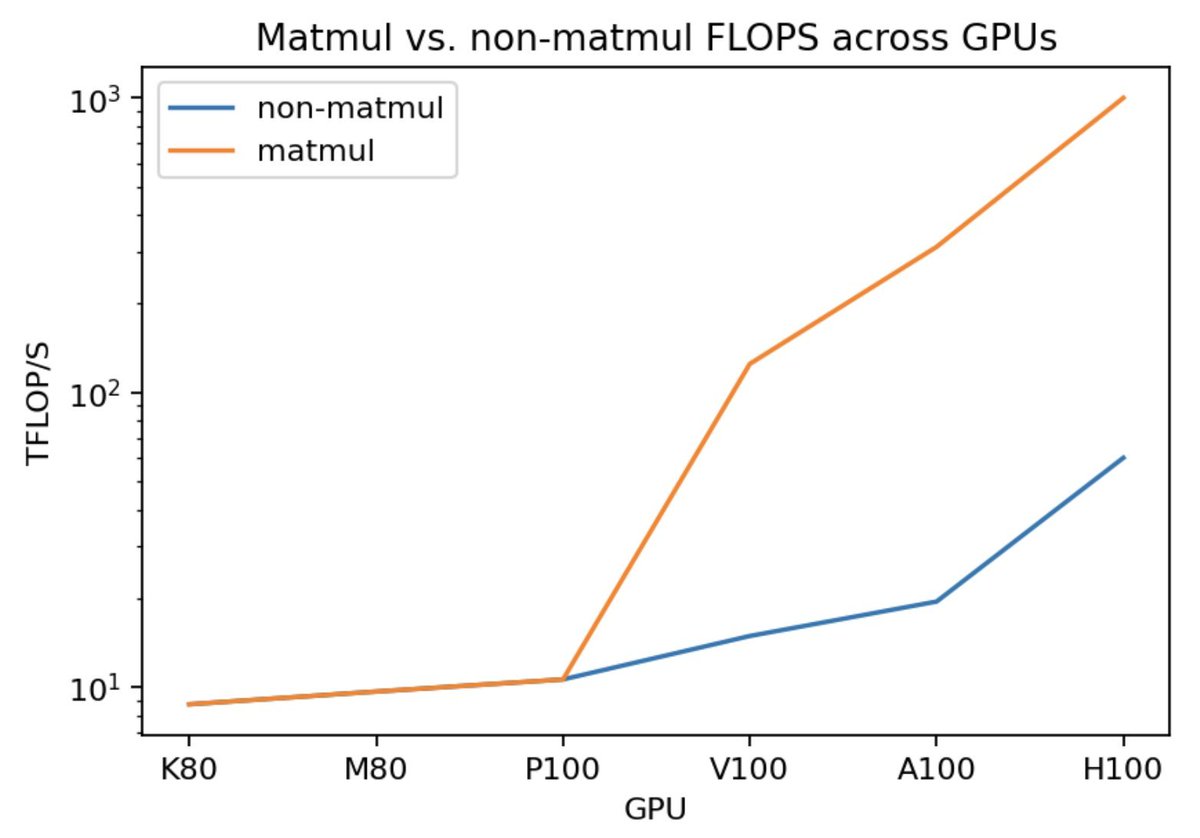
800-rated problems are the easiest problems on Codeforces, and are determined automatically based off of the ratings of the people solving them during the contest. Thus, I would expect that these problems are roughly of "equal" difficulty, and my spot check would agree.  There are 3 concepts needed to explain the above graph - compute intensity, tiling, and wave quantization.
There are 3 concepts needed to explain the above graph - compute intensity, tiling, and wave quantization. To explain tiling, we first need to understand hardware memory accesses. Memory doesn't transfer elements one at a time - it transfers large "chunks". That is, even if you only only need one element, the GPU will load that element... and the 31 elements next to it.
To explain tiling, we first need to understand hardware memory accesses. Memory doesn't transfer elements one at a time - it transfers large "chunks". That is, even if you only only need one element, the GPU will load that element... and the 31 elements next to it. 
 Let's look at a simple example - resnet18 inference with a single image. We see that we achieve about 2ms latency - not great for this model.
Let's look at a simple example - resnet18 inference with a single image. We see that we achieve about 2ms latency - not great for this model.

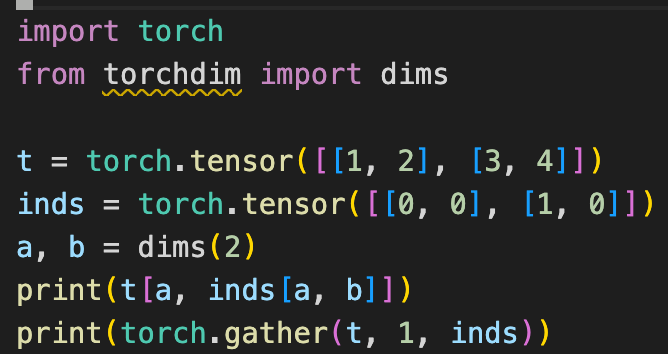
 Tensor cores, put simply, are "hardware hard-coded for matrix multiplication".
Tensor cores, put simply, are "hardware hard-coded for matrix multiplication". 
 In neural networks, matmuls usually take up >99% of the computational cost. Everything else is a rounding error.
In neural networks, matmuls usually take up >99% of the computational cost. Everything else is a rounding error.



 @iclr_conf For experience:
@iclr_conf For experience: