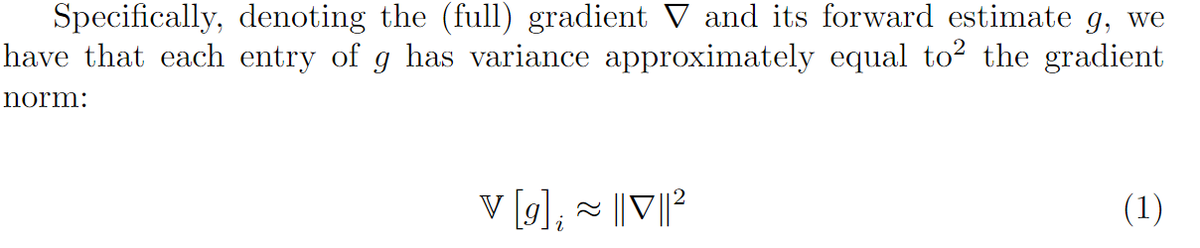gpu enjoyer at @modal. he/him.
ex @full_stack_dl, @weights_biases (acq. @CoreWeave), phd Berkeley @Redwood_Neuro.
try https://t.co/SYWVMCb7OB


 FYI this thread is a summary of a blog post -- head there for a lot more detail!
FYI this thread is a summary of a blog post -- head there for a lot more detail! The heart of the CUDA stack, IMO, is not anything named CUDA: it’s the humble Parallel Thread eXecution instruction set architecture, the compilation target of the CUDA compiler and the only stable interface to GPU hardware.
The heart of the CUDA stack, IMO, is not anything named CUDA: it’s the humble Parallel Thread eXecution instruction set architecture, the compilation target of the CUDA compiler and the only stable interface to GPU hardware.
 Details of our work and repro code on the Modal blog.
Details of our work and repro code on the Modal blog. (please do not park your car on a volcano, even if you have an e-brake)
(please do not park your car on a volcano, even if you have an e-brake)
 context: A100s are beefy GPUs, and they have enough VRAM to comfortably train models, like Stable Diffusion, that generate images from text
context: A100s are beefy GPUs, and they have enough VRAM to comfortably train models, like Stable Diffusion, that generate images from text
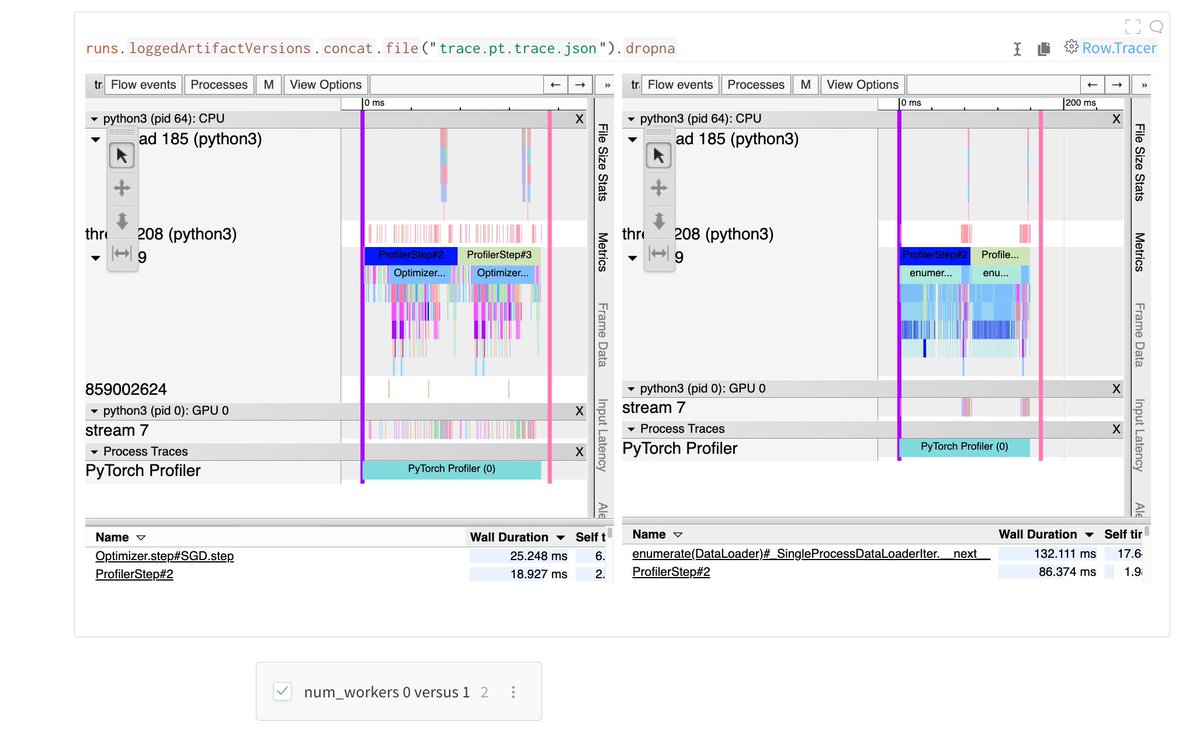
 Each report was a post-hoc meta-analysis of post-mortem analyses: which "root causes" come up most often? Which take the most time to resolve?
Each report was a post-hoc meta-analysis of post-mortem analyses: which "root causes" come up most often? Which take the most time to resolve?




 this follows the format of really successful MLC interest groups in e.g. NLP (notion.so/MLC-NLP-Paper-…) and Computer Vision (notion.so/MLC-Computer-V…)
this follows the format of really successful MLC interest groups in e.g. NLP (notion.so/MLC-NLP-Paper-…) and Computer Vision (notion.so/MLC-Computer-V…)
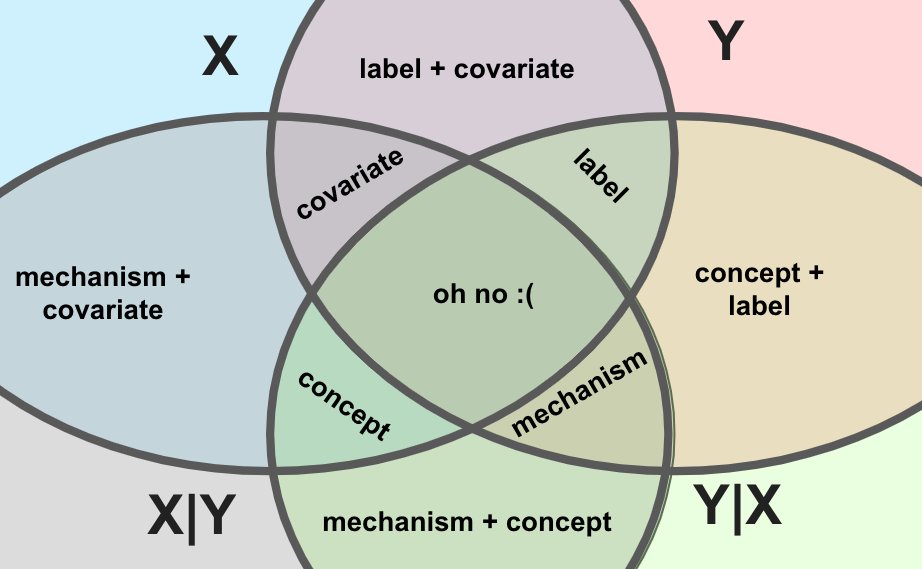 (inb4 pedantry: the above diagram is an Euler diagram, not a Venn diagram, meaning not all possible joins are represented. that is good, actually, for reasons to be revealed!)
(inb4 pedantry: the above diagram is an Euler diagram, not a Venn diagram, meaning not all possible joins are represented. that is good, actually, for reasons to be revealed!)