
PhD in AI | GDE in AI/ML | CTO Intento | Author "Deep Learning with JAX"
📝 ML insights: https://t.co/ySSOXJKL7H
🤖 Daily AI paper reviews: https://t.co/yQNYyqTbBR
 2/ Lacuna addresses this by shifting scientific discovery "left"—precomputing a structured database of over 733,000 ML papers.
2/ Lacuna addresses this by shifting scientific discovery "left"—precomputing a structured database of over 733,000 ML papers. 
 2/ In "Pretraining Recurrent Networks without Recurrence", Akarsh Kumar and Phillip Isola bypass BPTT entirely.
2/ In "Pretraining Recurrent Networks without Recurrence", Akarsh Kumar and Phillip Isola bypass BPTT entirely.  2/
2/ 2/ This is the core thesis of "The Topological Trouble With Transformers" by Michael C. Mozer, Shoaib Ahmed Siddiqui, and Rosanne Liu.
2/ This is the core thesis of "The Topological Trouble With Transformers" by Michael C. Mozer, Shoaib Ahmed Siddiqui, and Rosanne Liu. 2/
2/ 2/
2/ 2/
2/ 2/
2/ 2/ Yu et al. just dropped The Latent Space, a massive survey formalizing the shift from discrete token decoding to machine-native continuous computation. It maps the architectures making this possible.
2/ Yu et al. just dropped The Latent Space, a massive survey formalizing the shift from discrete token decoding to machine-native continuous computation. It maps the architectures making this possible. 
 2/ V-JEPA 2.1 by Mur-Labadia, Muckley, and the FAIR team fixes the global-local representation bottleneck. It unifies image and video representation learning into a single encoder. This is a massive step for embodied AI world models.
2/ V-JEPA 2.1 by Mur-Labadia, Muckley, and the FAIR team fixes the global-local representation bottleneck. It unifies image and video representation learning into a single encoder. This is a massive step for embodied AI world models. 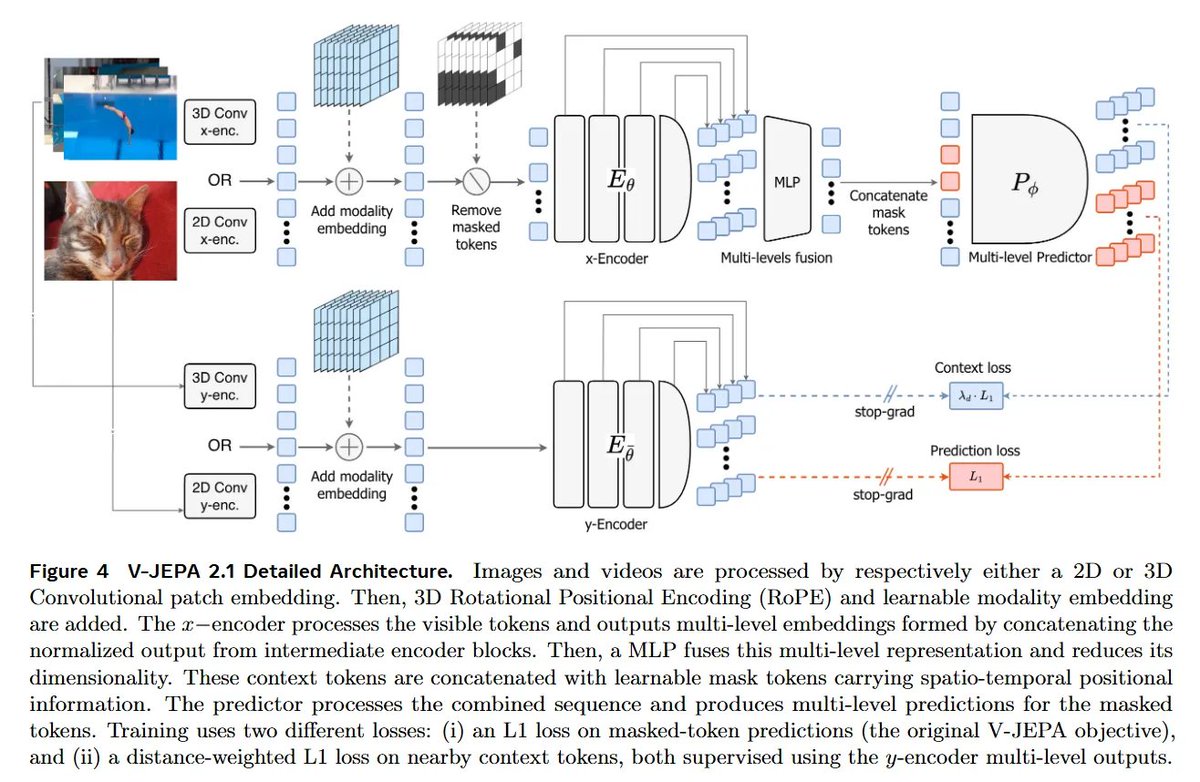
 2/ The paper "Symmetry in language statistics shapes the geometry of model representations" by Karkada et al. solves a major interpretability puzzle. It links the shape of the neural code directly to translation symmetry in the training corpus.
2/ The paper "Symmetry in language statistics shapes the geometry of model representations" by Karkada et al. solves a major interpretability puzzle. It links the shape of the neural code directly to translation symmetry in the training corpus.
 2/
2/ 2/
2/