
Ed.D. | Founder @networkdefense @RuralTechFund | Former @Mandiant, DoD | Author: Intrusion Detection Honeypots, Practical Packet Analysis, Applied NSM
 In the course, you’ll learn how to use YARA to detect malware, triage compromised systems, and collect threat intelligence. No prior YARA experience is required.
In the course, you’ll learn how to use YARA to detect malware, triage compromised systems, and collect threat intelligence. No prior YARA experience is required.


 Even when a workplace is accessible to someone with a disability (and despite the ADA, many are not), the commute there may not be. Eliminating. that commute opens up a lot of possibilities.
Even when a workplace is accessible to someone with a disability (and despite the ADA, many are not), the commute there may not be. Eliminating. that commute opens up a lot of possibilities.
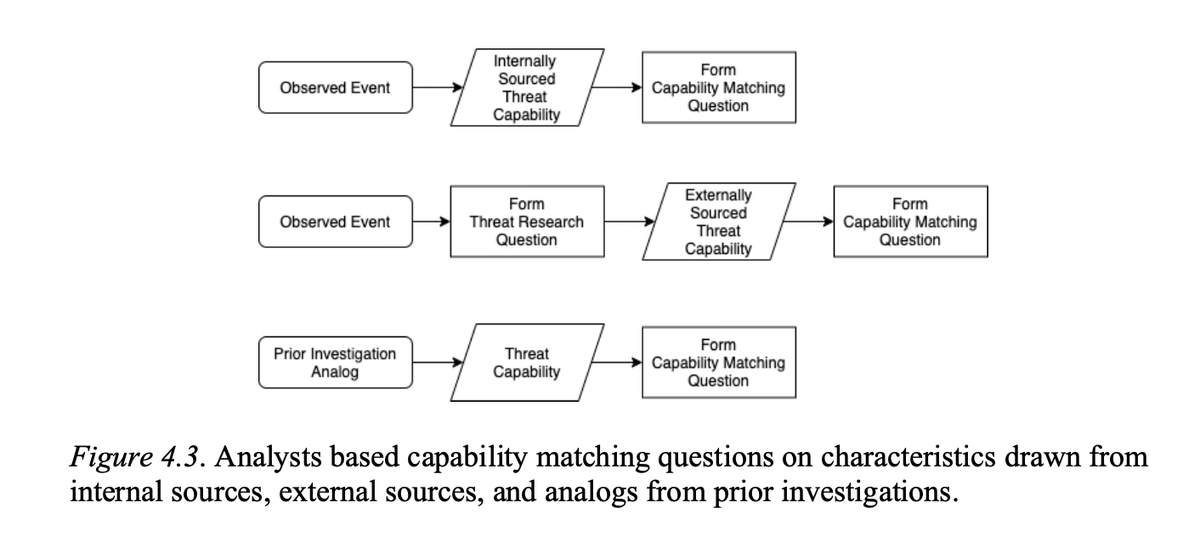




 Breaking that down further, you're asking:
Breaking that down further, you're asking:


 My research in security analysis has shown how decisions reached from deliberate thought are typically higher quality than those reached intuitively, even by experts. But, why do we often rely on intuition so much? 2/
My research in security analysis has shown how decisions reached from deliberate thought are typically higher quality than those reached intuitively, even by experts. But, why do we often rely on intuition so much? 2/
 I think most all perspectives are useful, but few conclusions are. I like qualitative studies that include the voice of participants because you get more of that perspective, and there's a lot of it to be found here. 2/
I think most all perspectives are useful, but few conclusions are. I like qualitative studies that include the voice of participants because you get more of that perspective, and there's a lot of it to be found here. 2/ 