
nonbayesian parameterics, sweet lessons, and random birds.
Friend of @srush_nlp
 Few-shot in-context learning induces a language model to perform a task by feeding in a few labeled examples along with a task description and then generating a prediction for an unlabeled example. Processing these “in-context” examples can incur a huge computational cost. (2/9)
Few-shot in-context learning induces a language model to perform a task by feeding in a few labeled examples along with a task description and then generating a prediction for an unlabeled example. Processing these “in-context” examples can incur a huge computational cost. (2/9) 
 We study the attack from Carlini et. al. (arxiv.org/abs/2012.07805) that
We study the attack from Carlini et. al. (arxiv.org/abs/2012.07805) that  Pre-trained models are a vital part of the model ML ecosystem. But large-scale pre-training is expensive, so most popular pre-trained models were developed by small isolated teams within large resource-rich companies. (2/11)
Pre-trained models are a vital part of the model ML ecosystem. But large-scale pre-training is expensive, so most popular pre-trained models were developed by small isolated teams within large resource-rich companies. (2/11) 
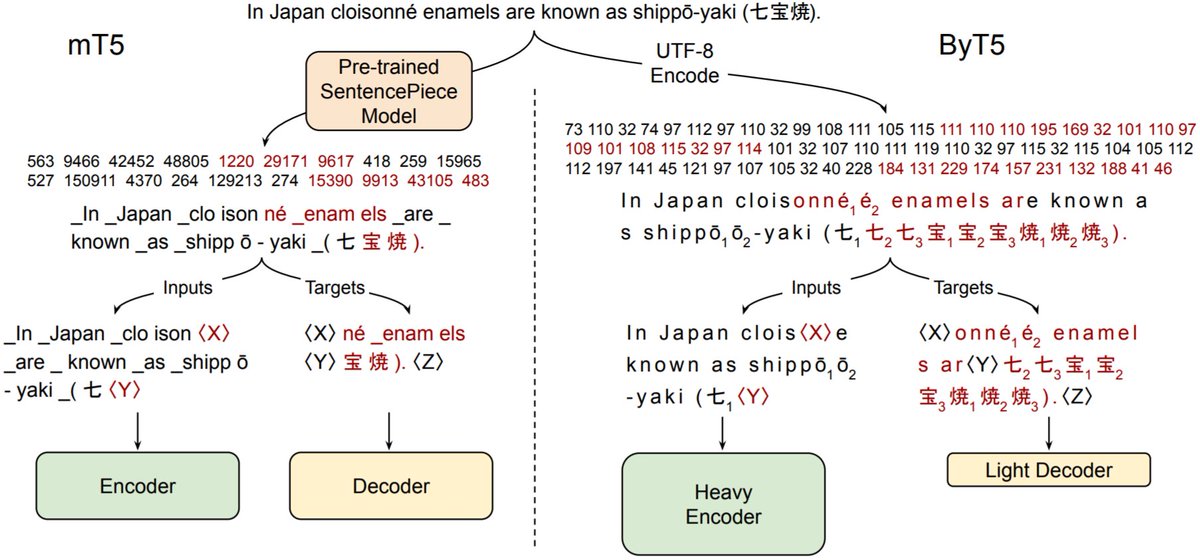 Tokenizers have many drawbacks:
Tokenizers have many drawbacks:
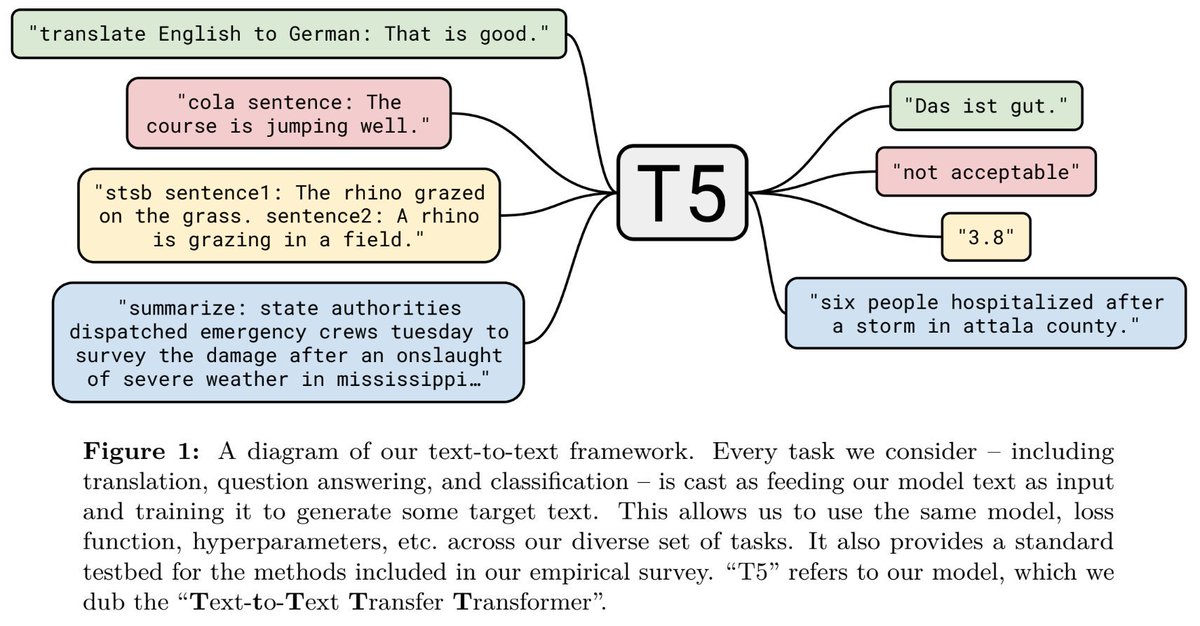 Our approach casts *every* language problem as a text-to-text task. For example, English-to-German translation -- input: "translate English to German: That is good." target: "Das ist gut." or sentiment ID -- input: "sentiment: This movie is terrible!", target: "negative" (2/14)
Our approach casts *every* language problem as a text-to-text task. For example, English-to-German translation -- input: "translate English to German: That is good." target: "Das ist gut." or sentiment ID -- input: "sentiment: This movie is terrible!", target: "negative" (2/14)