
Founder of @getoutbox_ai
Learn how to build AI Agents for FREE 👉 https://t.co/q9zPwlldZ4
 1/ The Context Anchor
1/ The Context Anchor Anthropic's engineers built Claude to understand XML tags.
Anthropic's engineers built Claude to understand XML tags. Most AI benchmarks test answers.
Most AI benchmarks test answers.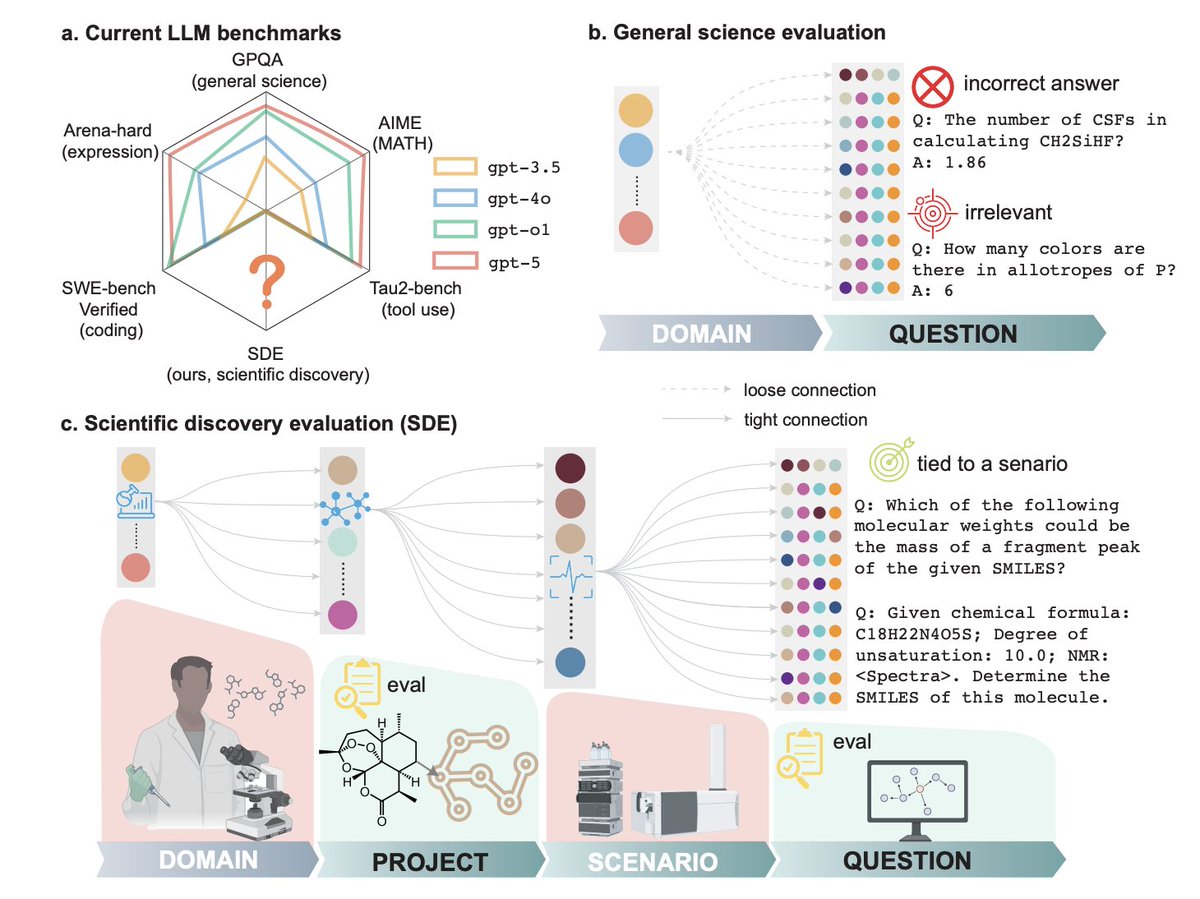
 The paper makes one thing painfully clear:
The paper makes one thing painfully clear: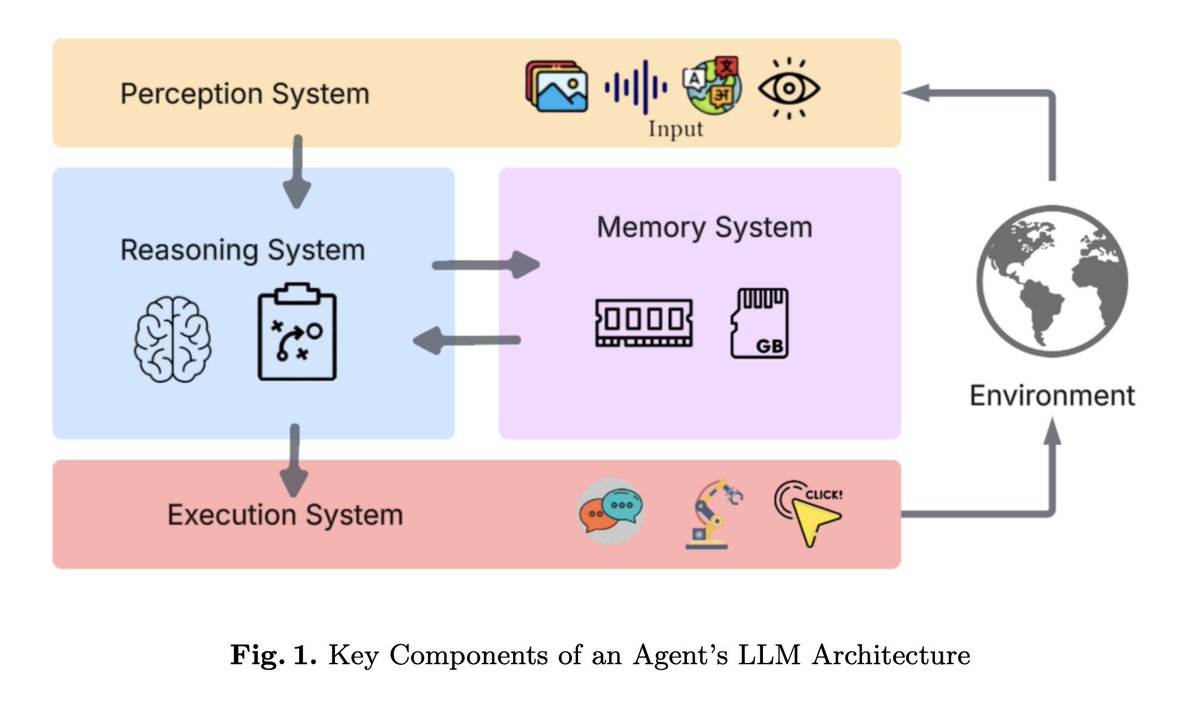
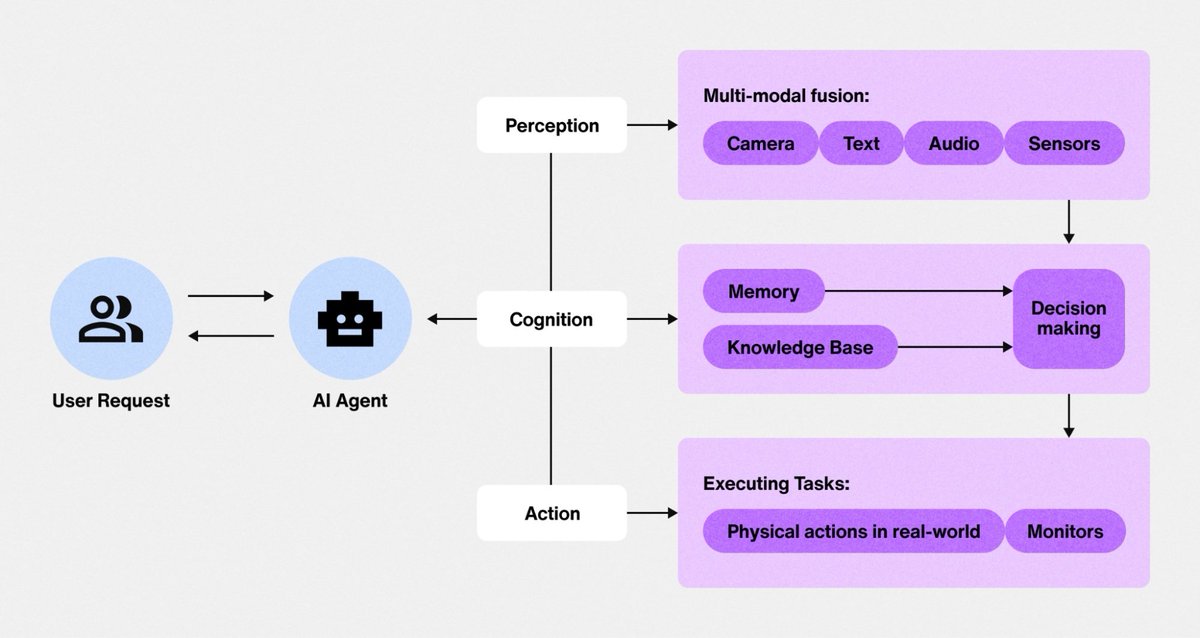 First: most "AI agents" are just glorified chatbots.
First: most "AI agents" are just glorified chatbots. The biggest lie: "Be specific and detailed"
The biggest lie: "Be specific and detailed"
 The pipeline is surprisingly simple. Model solves problem → reflects on its own solution → extracts reusable behaviors. No architectural changes needed.
The pipeline is surprisingly simple. Model solves problem → reflects on its own solution → extracts reusable behaviors. No architectural changes needed.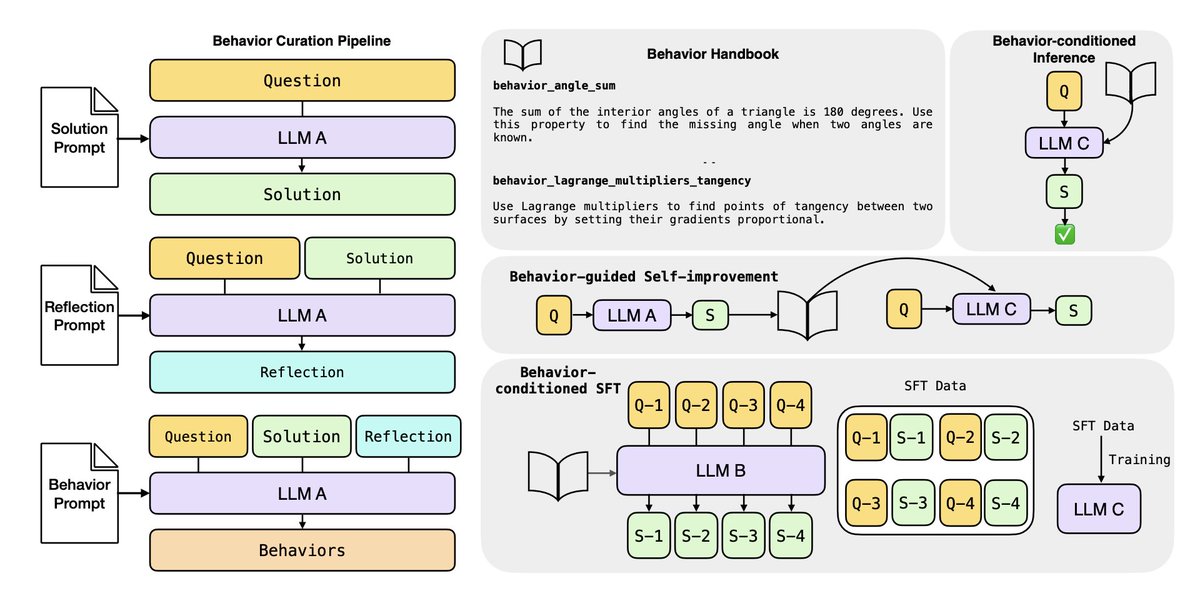

 The traditional research process is painfully slow:
The traditional research process is painfully slow: Most people think hallucinations are random quirks.
Most people think hallucinations are random quirks.
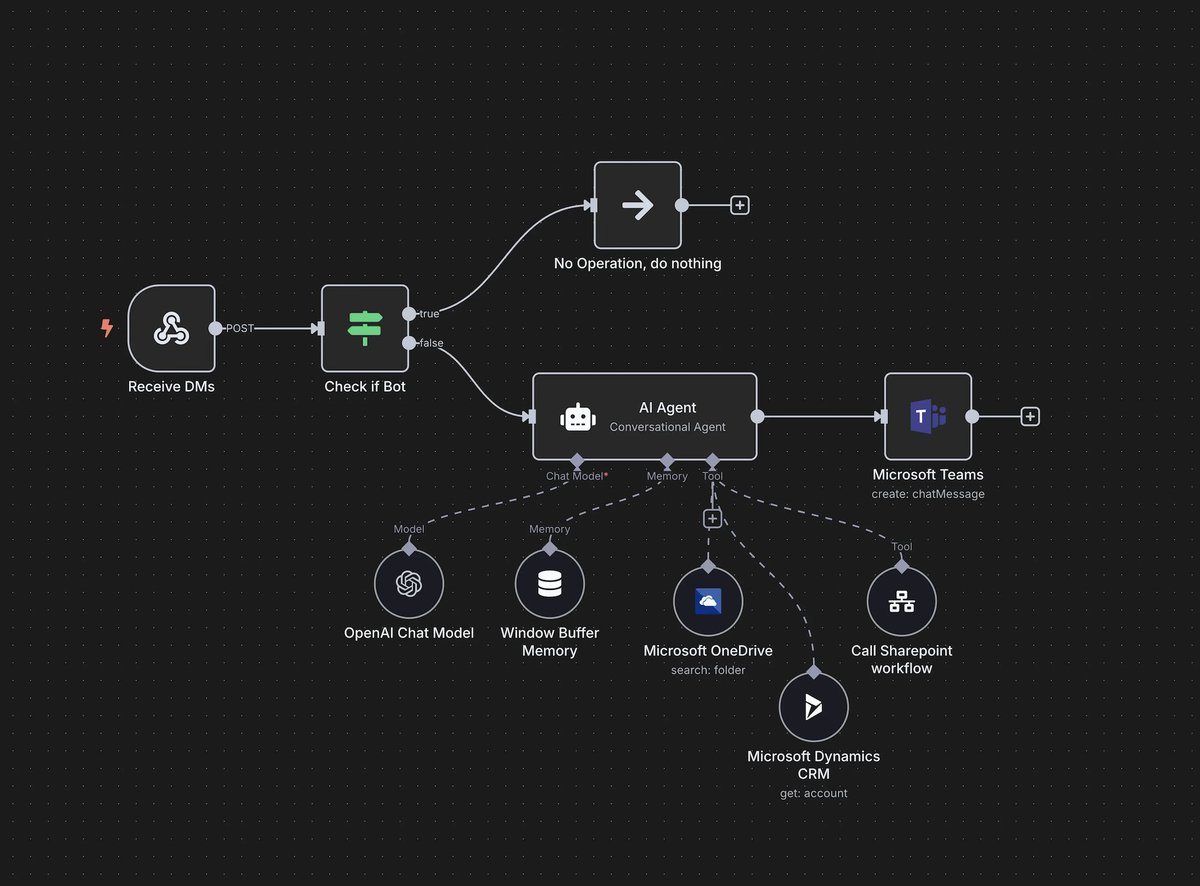 The system:
The system: Today, most AI agents run every task no matter how simple through massive LLMs like GPT-4 or Claude.
Today, most AI agents run every task no matter how simple through massive LLMs like GPT-4 or Claude.
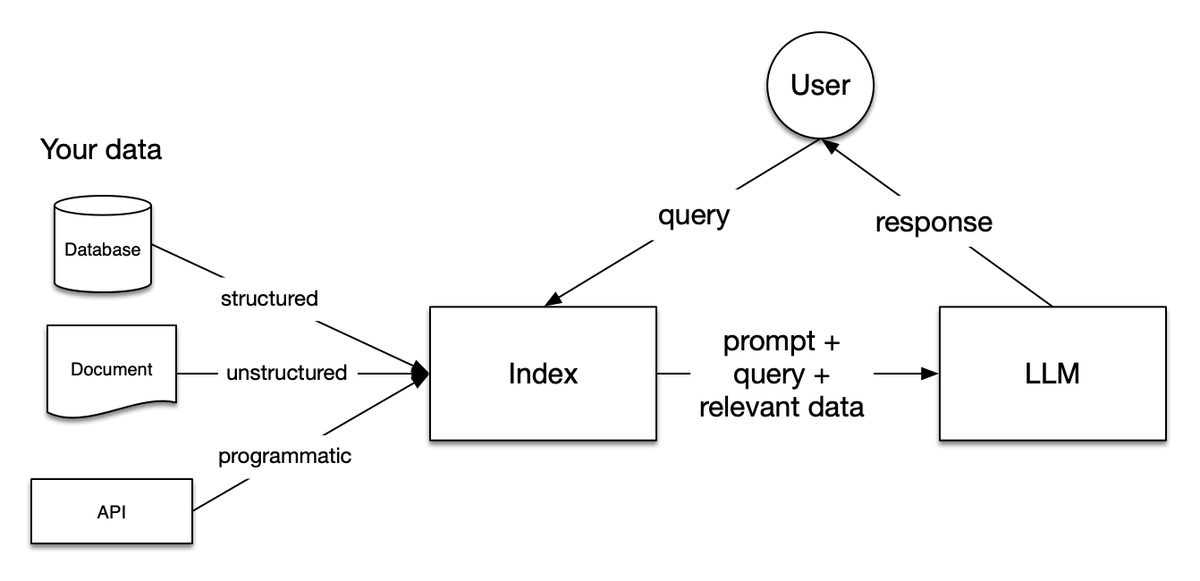
 Let’s get one thing clear:
Let’s get one thing clear:
 When people upgrade to more powerful AI, they expect better results.
When people upgrade to more powerful AI, they expect better results.