
📈 I summarise Machine Learning, AI and Time Series concepts in an easy and visual way • 💊Follow me in https://t.co/oYXkuSoo4b
👉 Inquiries by PM
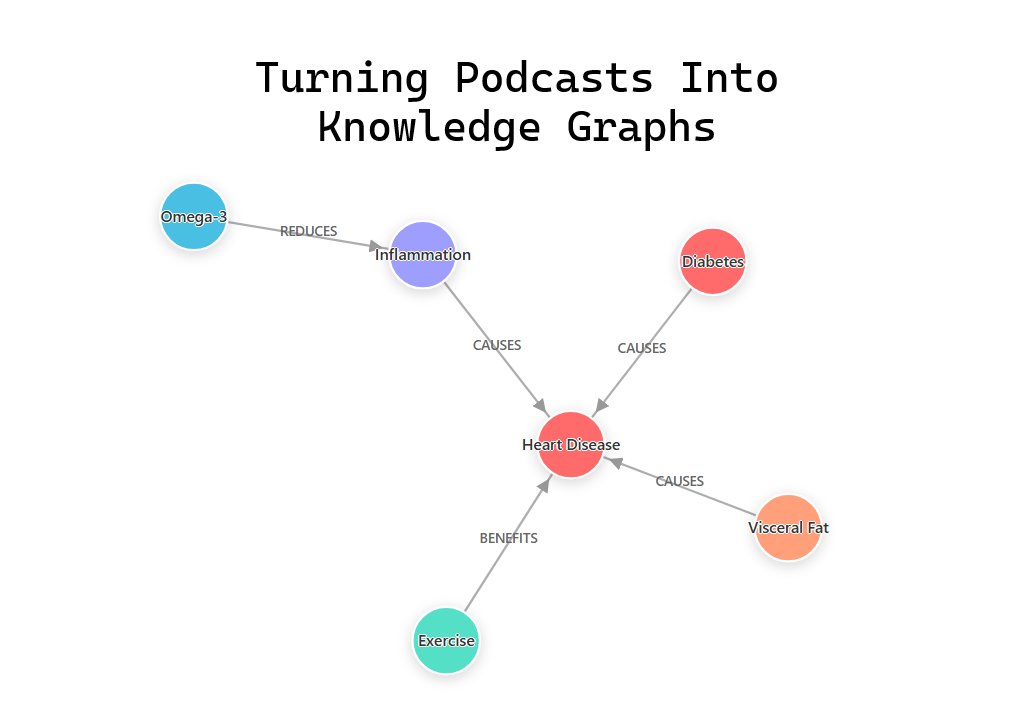 The core is knowledge extraction using LangChain's LLMGraphTransformer with gpt-4o.
The core is knowledge extraction using LangChain's LLMGraphTransformer with gpt-4o. 🟢 Early layers focus on low-level features extracted directly from pixel intensities.
🟢 Early layers focus on low-level features extracted directly from pixel intensities.
 1️⃣ Dimensionality Reduction
1️⃣ Dimensionality Reduction Exploratory Data Analysis (EDA) is a process used for investigating your data to discover patterns, anomalies, relationships, or trends using statistical summaries and visual methods.
Exploratory Data Analysis (EDA) is a process used for investigating your data to discover patterns, anomalies, relationships, or trends using statistical summaries and visual methods.
 Multi Query is a powerful Query Translation technique to enhance information retrieval in AI systems.
Multi Query is a powerful Query Translation technique to enhance information retrieval in AI systems. DBSCAN, or Density-Based Spatial Clustering of Applications with Noise, is a powerful clustering algorithm.
DBSCAN, or Density-Based Spatial Clustering of Applications with Noise, is a powerful clustering algorithm. What is it?
What is it? RAG helps bridge the gap between large language models and external data sources, allowing AI systems to generate relevant and informed responses by leveraging knowledge from existing documents and databases.
RAG helps bridge the gap between large language models and external data sources, allowing AI systems to generate relevant and informed responses by leveraging knowledge from existing documents and databases. Support Vector Machine is a useful Machine Learning algorithm frequently used for both classification and regression problems.
Support Vector Machine is a useful Machine Learning algorithm frequently used for both classification and regression problems. KNN is a versatile supervised learning algorithm widely employed in both classification and regression tasks.
KNN is a versatile supervised learning algorithm widely employed in both classification and regression tasks. A normal distribution, also known as a Gaussian distribution, is the most typical distribution you'll find in your days features.
A normal distribution, also known as a Gaussian distribution, is the most typical distribution you'll find in your days features. 5️⃣ Exponential Distribution:
5️⃣ Exponential Distribution: 1️⃣ Normal Distribution:
1️⃣ Normal Distribution: RAG helps bridge the gap between large language models and external data sources, allowing AI systems to generate relevant and informed responses by leveraging knowledge from existing documents and databases.
RAG helps bridge the gap between large language models and external data sources, allowing AI systems to generate relevant and informed responses by leveraging knowledge from existing documents and databases. ✦ They empower similarity searches vital for LLMs in tasks like semantic search and recommendation systems.
✦ They empower similarity searches vital for LLMs in tasks like semantic search and recommendation systems. LangChain offers different modules tailored for language model applications.
LangChain offers different modules tailored for language model applications.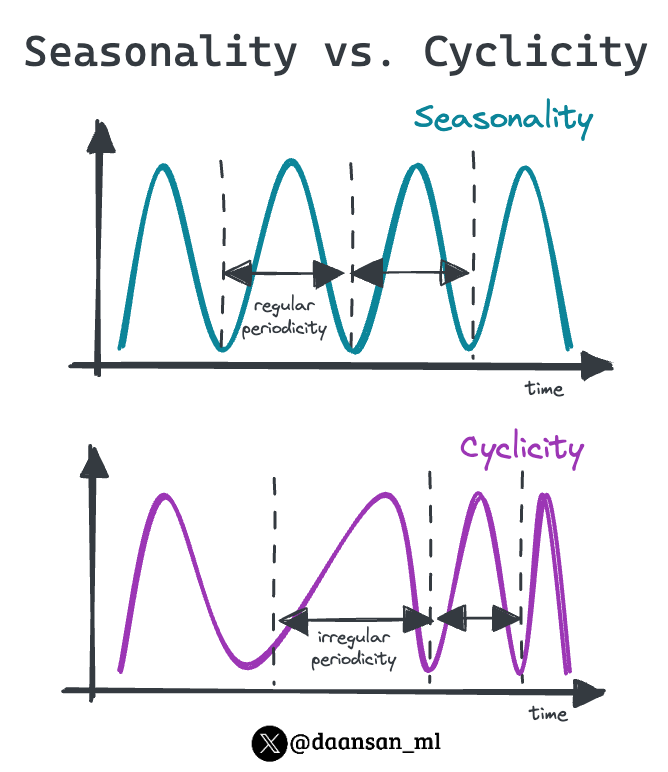 Seasonality and cyclicality are two essential concepts that play a crucial role in understanding patterns within time series data.
Seasonality and cyclicality are two essential concepts that play a crucial role in understanding patterns within time series data. In SVM, the kernel trick is a clever way to perform complex calculations in a higher-dimensional feature space without explicitly transforming the original data into that space.
In SVM, the kernel trick is a clever way to perform complex calculations in a higher-dimensional feature space without explicitly transforming the original data into that space. The trend component represents the overall direction data moves over an extended period.
The trend component represents the overall direction data moves over an extended period. Steps:
Steps: 1️⃣ Model Interpretability
1️⃣ Model Interpretability