
Machine learning researcher @MetaAI. Previously @Criteo and @Inria. I tweet on math, ML, and lots of random stuff. Tweets are mine. Blog: https://t.co/XAsL4l6Q7


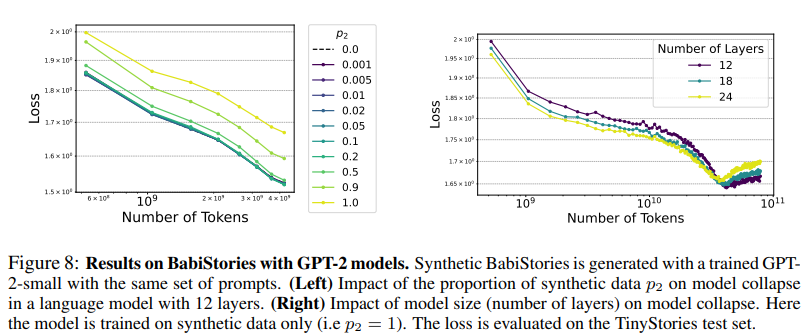 2/n Going further, we ask two important questions.
2/n Going further, we ask two important questions.

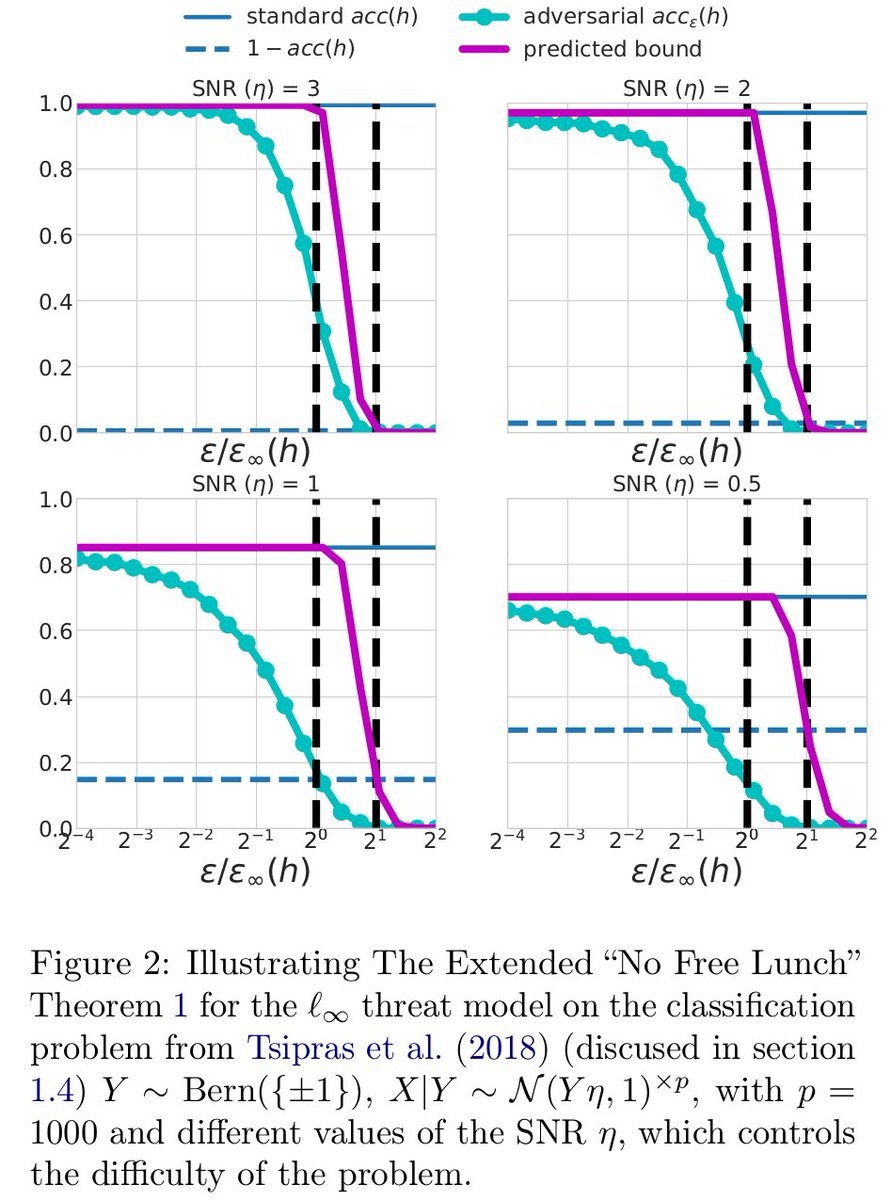
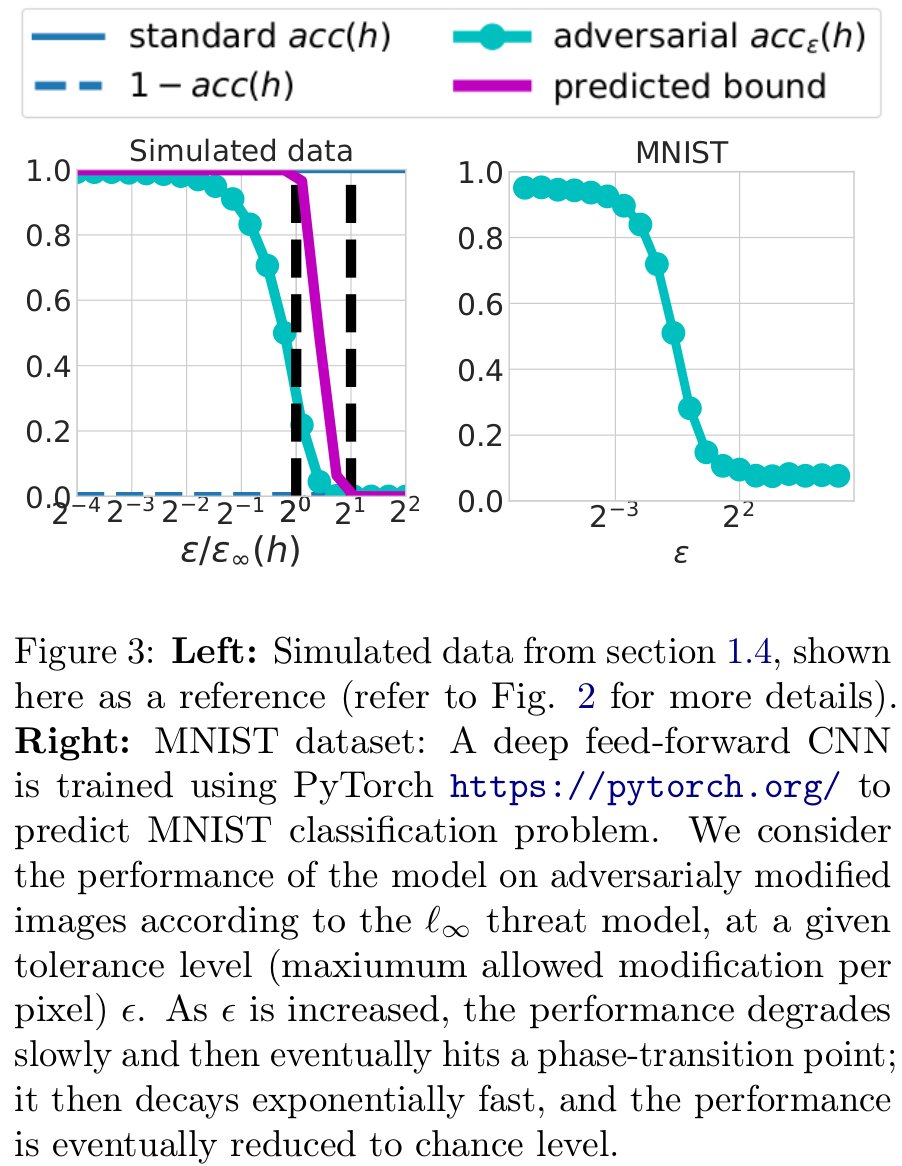 2/ Moreover, eps_* is comparable to the natural noise level on the problem, with a modulation factor which varies only logarithmic as a function of the particular classifier ==> adversarial robustness / non-robustness is more a property of data than of some magical classifier
2/ Moreover, eps_* is comparable to the natural noise level on the problem, with a modulation factor which varies only logarithmic as a function of the particular classifier ==> adversarial robustness / non-robustness is more a property of data than of some magical classifier