Assistant Professor at Harvard @KempnerInst + CS. PhD @MIT_CSAIL, BS MIT. Generative Models, Compositionality, Embodied Agents, Robot Learning.
Sep 18, 2023 • 4 tweets • 3 min read
A major challenge to constructing foundation models for decision making is data scarcity.
We present a “compositional foundation model”, which addresses this by composing existing foundation models, each capturing a sub-part of decision making.
(1/4) …l-planning-foundation-model.github.io
We use LLMs to synthesize task plans, text-to-video models to synthesize motion plans, and large scale action models to jointly construct hierarchical plans.
Consistency in making decisions is ensured across different models through iterative refinement.
(2/4)
May 24, 2023 • 5 tweets • 3 min read
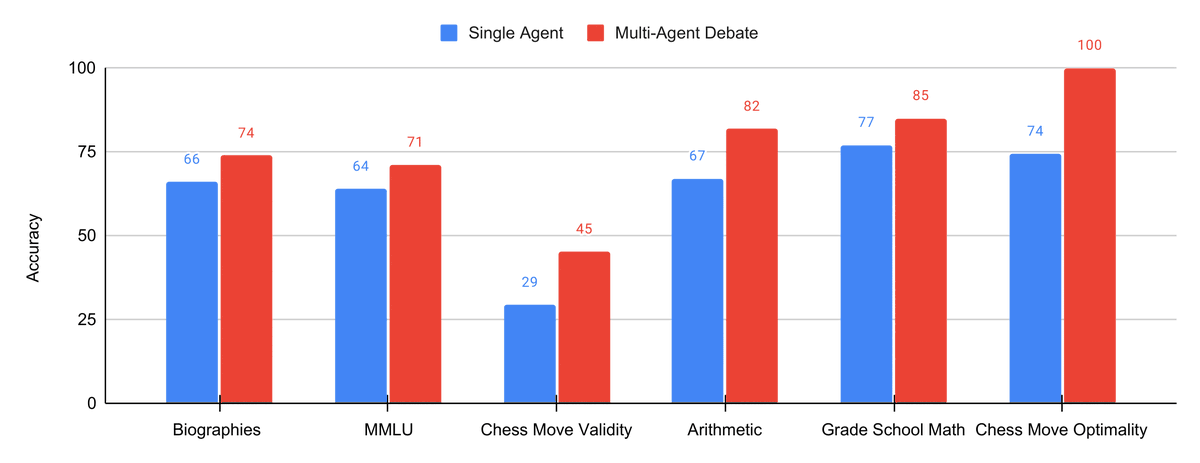
Our new paper on introducing multi-agent debate as means improve the reasoning and factual accuracy of large language models!
Multiple instances of a language model debate with each other over multiple rounds to reach an improved shared answer.
(1/5)
We prompt each model/agent with the same initial question, and ask each agent to iteratively critique and update their responses given the responses of other agents. We find this improves performance across a set of different reasoning and factuality benchmarks.
(2/5)
Feb 3, 2023 • 6 tweets • 3 min read
Can text-to-video generation help decision making?
Introducing UniPi, which acts by synthesizing a video of what it will do:
UniPi can generate diverse videos/actions across many environments (and combinatorially generalize!):
(1/6)
Similar to existing text-to-image models, UniPi can synthesize videos of actions executing unseen combination of goals:
(2/6)
Nov 29, 2022 • 5 tweets • 3 min read
Introducing Decision Diffuser, a conditional diffusion model that outperforms offline RL across standard benchmarks – using only generative modeling training! Decision Diffusers can also combine multiple constraints and skills at test-time.
1/5
By modeling a policy as a return conditional diffusion model, we illustrate how we may circumvent the need for dynamic programming and subsequently eliminate many of the complexities that come with traditional offline RL.
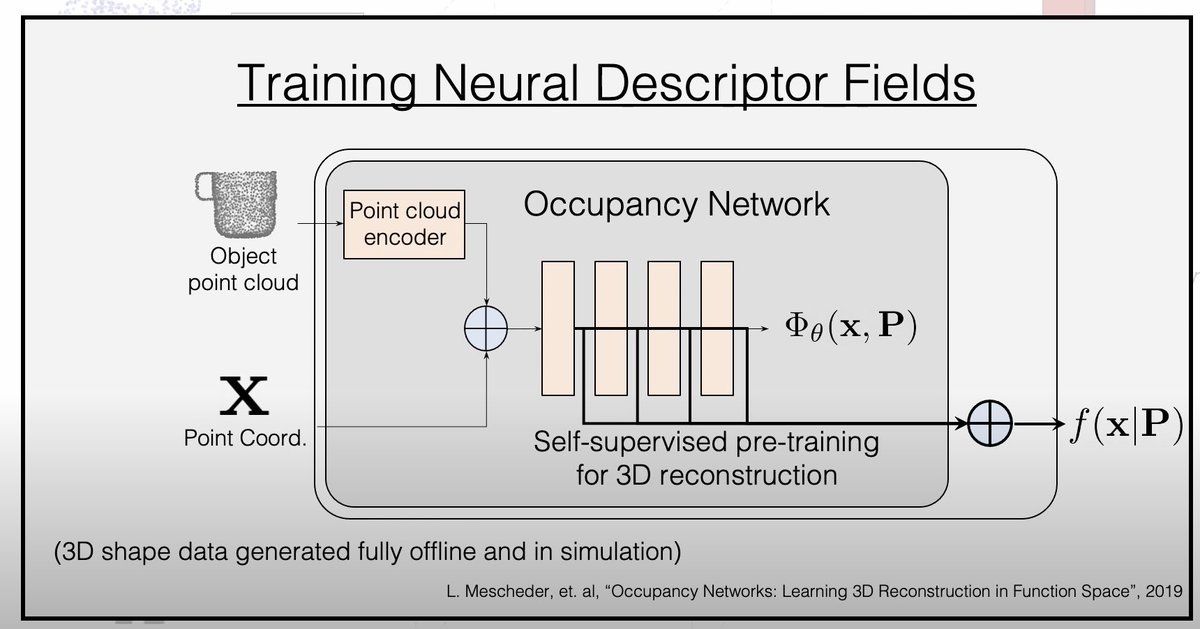
We present a self-supervised method to obtain SE(3) equivariant descriptors of 3D shapes. These descriptors enable us generalize pick and place demonstrations to arbitrary novel SE(3) poses and objects instances