


 Snippet 2: On even simple benchmarks, neural networks are not only poor at generalizing to OOD but also degrade in their uncertainty estimates.
Snippet 2: On even simple benchmarks, neural networks are not only poor at generalizing to OOD but also degrade in their uncertainty estimates. 

 Cable management is a huge quality of life improvement.
Cable management is a huge quality of life improvement. 

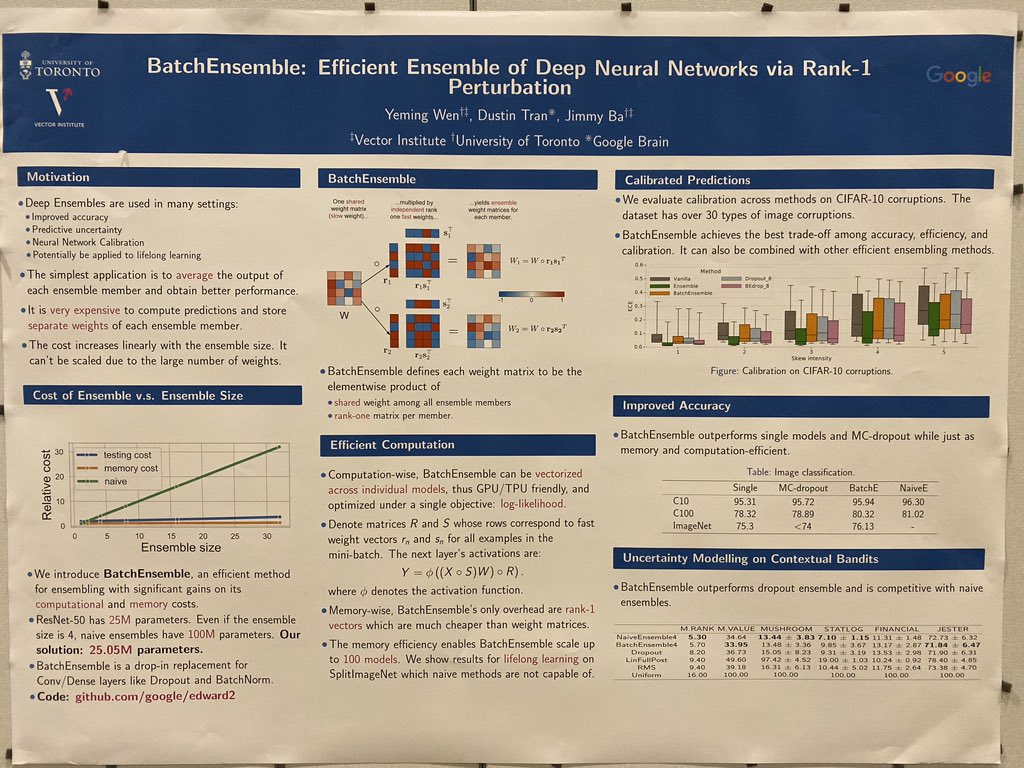 It’s a drop in replacement for individual layers, like dropout, batchnorm, and variational layers and is available with baselines and Bayesian layers at github.com/google/edward2. 2/-
It’s a drop in replacement for individual layers, like dropout, batchnorm, and variational layers and is available with baselines and Bayesian layers at github.com/google/edward2. 2/-