
I like writing threads! Archive ➙ https://t.co/ry8HHZdaye
Co-founded @LightstepHQ.
Co-created @OpenTelemetry & @OpenTracing.
Co-created Dapper and Monarch at Google.
 1/ All good engineers care about their users. In the olden days of monolithic software apps, engineers even got to deploy software that touched those users directly!
1/ All good engineers care about their users. In the olden days of monolithic software apps, engineers even got to deploy software that touched those users directly!
 1/ So, first things first: the only reason anyone cares about sampling is that distributed tracing can generate a *vast* amount of telemetry, and we need to be thoughtful about how we transmit, store, and analyze it.
1/ So, first things first: the only reason anyone cares about sampling is that distributed tracing can generate a *vast* amount of telemetry, and we need to be thoughtful about how we transmit, store, and analyze it.
 1/ The first “Digital Transformation” is a transformation of Operations. This isn’t just SRE or ITOps, to be clear, it’s much broader – basically “all Opex,” or “everything that employees do.”
1/ The first “Digital Transformation” is a transformation of Operations. This isn’t just SRE or ITOps, to be clear, it’s much broader – basically “all Opex,” or “everything that employees do.” 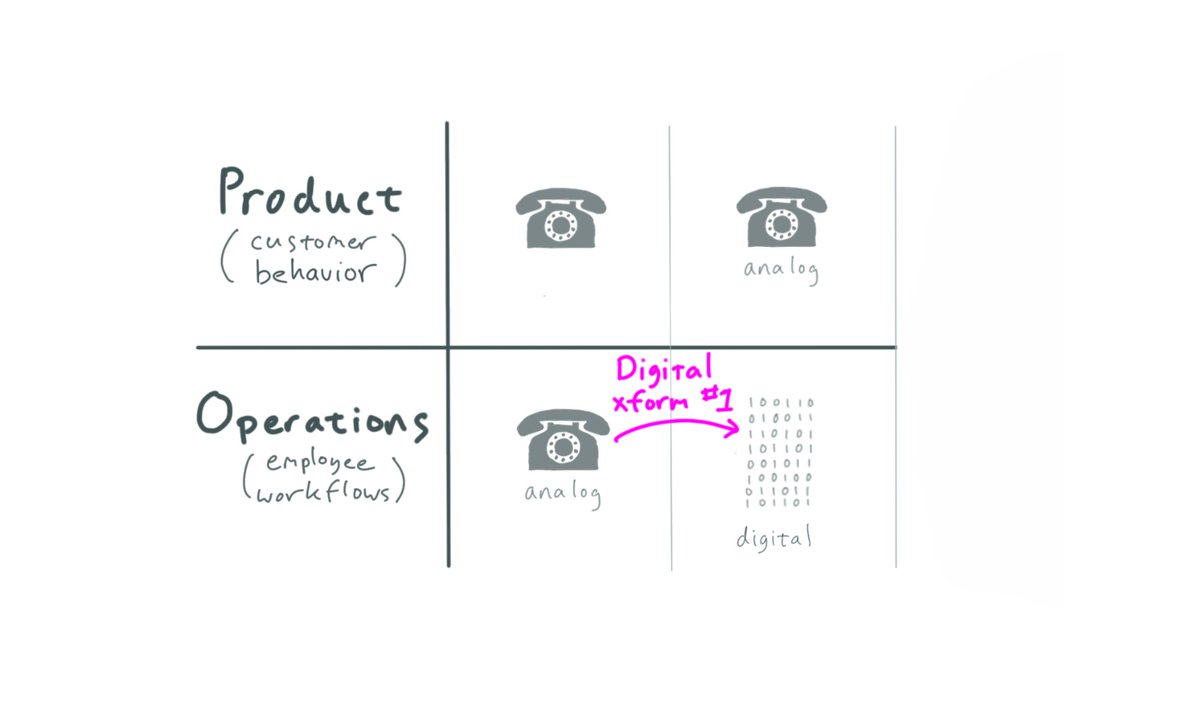
 1/ The best logging is always *structured* logging. That is, logging statements are most useful if they encode key:value pairs which can then be queried and *analyzed* in the aggregate.
1/ The best logging is always *structured* logging. That is, logging statements are most useful if they encode key:value pairs which can then be queried and *analyzed* in the aggregate.
 1/ Let’s begin by restating the conventional wisdom about how to do “Continuous Delivery” for a single (micro)service:
1/ Let’s begin by restating the conventional wisdom about how to do “Continuous Delivery” for a single (micro)service: 1/ But first, some definitions.
1/ But first, some definitions. 1/ At a certain level, Kafka is just like any other resource in your system: e.g., your database’s CPUs, your NICs, or your RAM reservations.
1/ At a certain level, Kafka is just like any other resource in your system: e.g., your database’s CPUs, your NICs, or your RAM reservations. 1/ Okay, first off: “what is cardinality, anyway?” And why is it such a big deal for metrics?
1/ Okay, first off: “what is cardinality, anyway?” And why is it such a big deal for metrics? 1/ Dapper certainly did some fancy tricks, and I’m sure it still does. If it’s possible to fall in love with an idea or a piece of technology, that’s what happened with me and Dapper. It wasn’t just new data, it was a new *type* of data – and lots of it. So. Much. Fun. …
1/ Dapper certainly did some fancy tricks, and I’m sure it still does. If it’s possible to fall in love with an idea or a piece of technology, that’s what happened with me and Dapper. It wasn’t just new data, it was a new *type* of data – and lots of it. So. Much. Fun. …
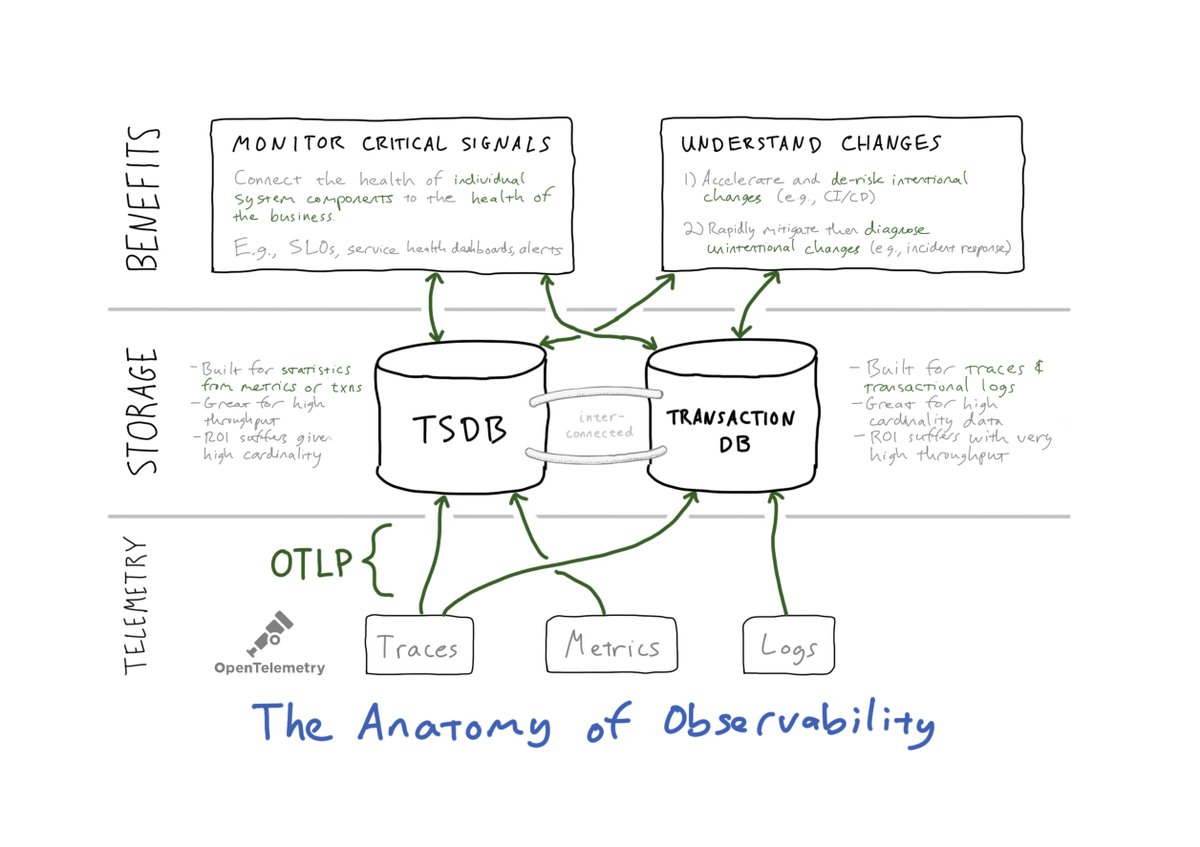 1/ Let’s start with the diagram (above) illustrating the anatomy of observability. There are three layers:
1/ Let’s start with the diagram (above) illustrating the anatomy of observability. There are three layers: 1/ First off, a crucial clarification: I don’t mean that the “loggers” – that is, the human operators – are selfish, of course! The problem has been that their (IMO primitive) toolchain needlessly localizes and *constrains* the value of the logging telemetry data.
1/ First off, a crucial clarification: I don’t mean that the “loggers” – that is, the human operators – are selfish, of course! The problem has been that their (IMO primitive) toolchain needlessly localizes and *constrains* the value of the logging telemetry data.
 1/ In this example, we are contending with a failed deploy within Lightstep’s own (internal, multi-tenant) system. It was easy enough to *detect* the regression and roll back, but in order to fix the underlying issue, of course we had to understand it.
1/ In this example, we are contending with a failed deploy within Lightstep’s own (internal, multi-tenant) system. It was easy enough to *detect* the regression and roll back, but in order to fix the underlying issue, of course we had to understand it.
 1/ You hear so much about observability because it *can* be awesome. :) Benefits roll up into at least one of the following:
1/ You hear so much about observability because it *can* be awesome. :) Benefits roll up into at least one of the following: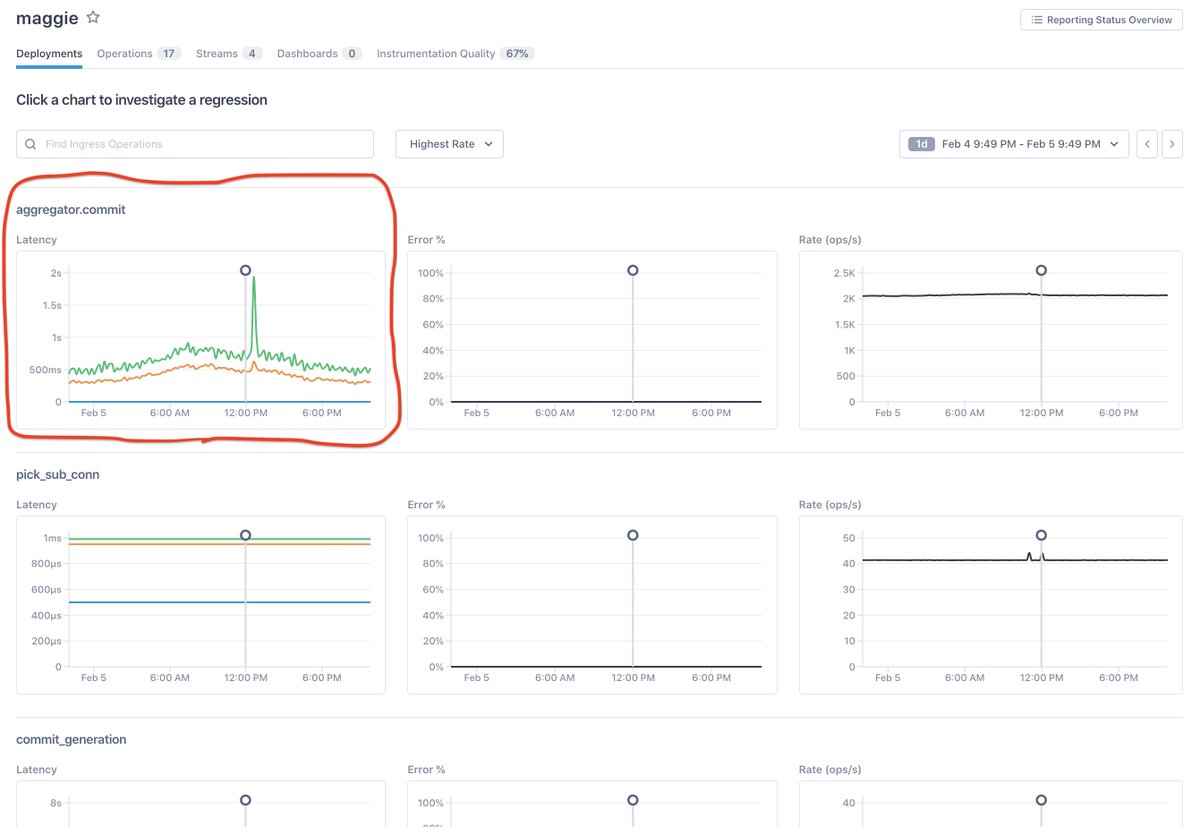 1/ A quick prologue: this real-world example comes from @LightStepHQ’s meta-monitoring (of our own SaaS). This way I can show real data at scale (Lightstep customers generate billions of traces every hour!!) without needing approval from customer eng+PR departments.
1/ A quick prologue: this real-world example comes from @LightStepHQ’s meta-monitoring (of our own SaaS). This way I can show real data at scale (Lightstep customers generate billions of traces every hour!!) without needing approval from customer eng+PR departments.
 1/ First, let's start with monoliths. Of course they've been around for a while, and it’s where most of us started. There is plenty of depth and complexity from a monolithic-codebase standpoint, but operationally it's just one big – and often brittle – binary.
1/ First, let's start with monoliths. Of course they've been around for a while, and it’s where most of us started. There is plenty of depth and complexity from a monolithic-codebase standpoint, but operationally it's just one big – and often brittle – binary. 
 2/ In APM’s heyday (think “New Relic and AppDynamics circa 2015”), the value prop was straightforward: “Just add this one magic agent and you’ll never need to wonder why your monolithic app is broken!”
2/ In APM’s heyday (think “New Relic and AppDynamics circa 2015”), the value prop was straightforward: “Just add this one magic agent and you’ll never need to wonder why your monolithic app is broken!”
 2/ The conventional wisdom looks like this…
2/ The conventional wisdom looks like this…
 First, let’s talk about scale and why it’s the wrong way to think about system complexity.
First, let’s talk about scale and why it’s the wrong way to think about system complexity.