
phd student @CMU_Robotics working on efficient algorithms for interactive learning (e.g., imitation, RL, RLHF). prefers email. on the job market!
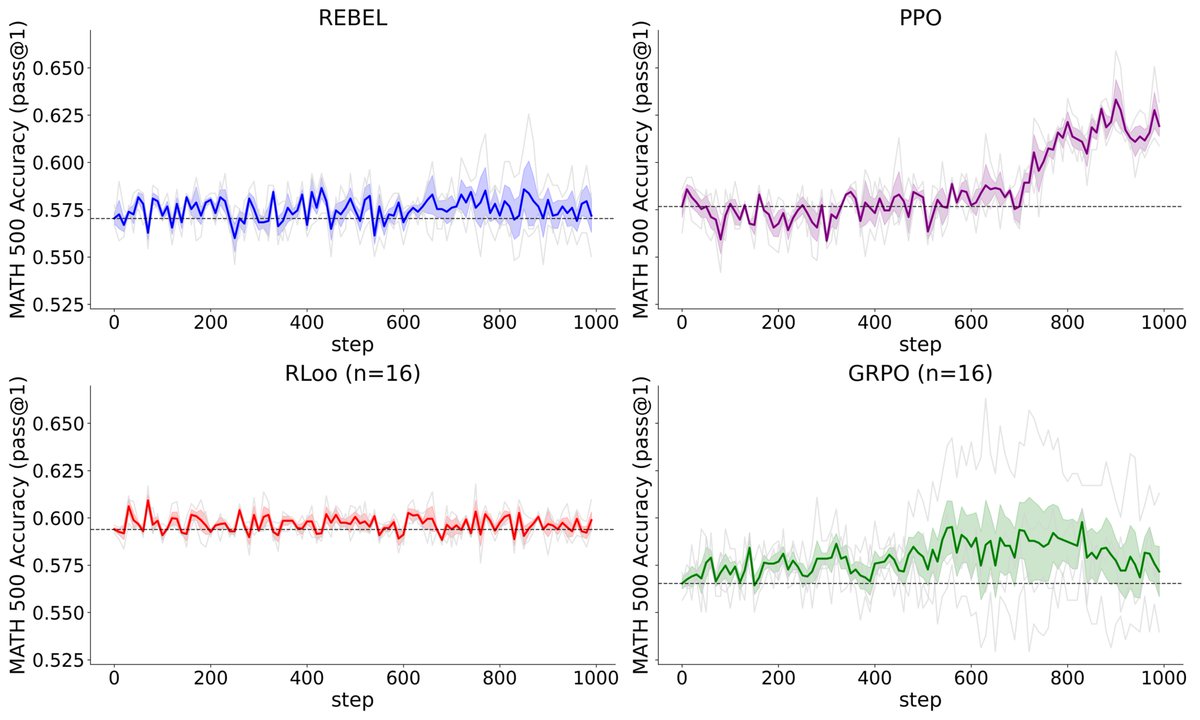 Lead by @owenoertell & @zhan_wenhao, joint w/ @zstevenwu, @xkianteb, @WenSun1, @jasondeanlee.
Lead by @owenoertell & @zhan_wenhao, joint w/ @zstevenwu, @xkianteb, @WenSun1, @jasondeanlee.  You can access all the content here:
You can access all the content here: If you'd like to avoid the bends, the TL;DR is that RL lets us filter down our search space to only those policies that are optimal for relatively simple verifiers.
If you'd like to avoid the bends, the TL;DR is that RL lets us filter down our search space to only those policies that are optimal for relatively simple verifiers. Check out for a video summary and https://t.co/VcriYEnN2u for the paper, code and key insights. [2/n]
Check out for a video summary and https://t.co/VcriYEnN2u for the paper, code and key insights. [2/n]