
Training VLMs at @GoogleDeepMind - ex @Amazon @CarnegieMellon @PoliTOnews @IITalk - I post honest non-AI-generated paper reviews
 They argue that compute grows 4x per year, while text grows way slower, just 3% per year
They argue that compute grows 4x per year, while text grows way slower, just 3% per year
 Every 2 layers they add trainable "Value Embeddings" (VEs) to the V tokens. VEs have shape like the token embeddings (D x vocab_size).
Every 2 layers they add trainable "Value Embeddings" (VEs) to the V tokens. VEs have shape like the token embeddings (D x vocab_size).
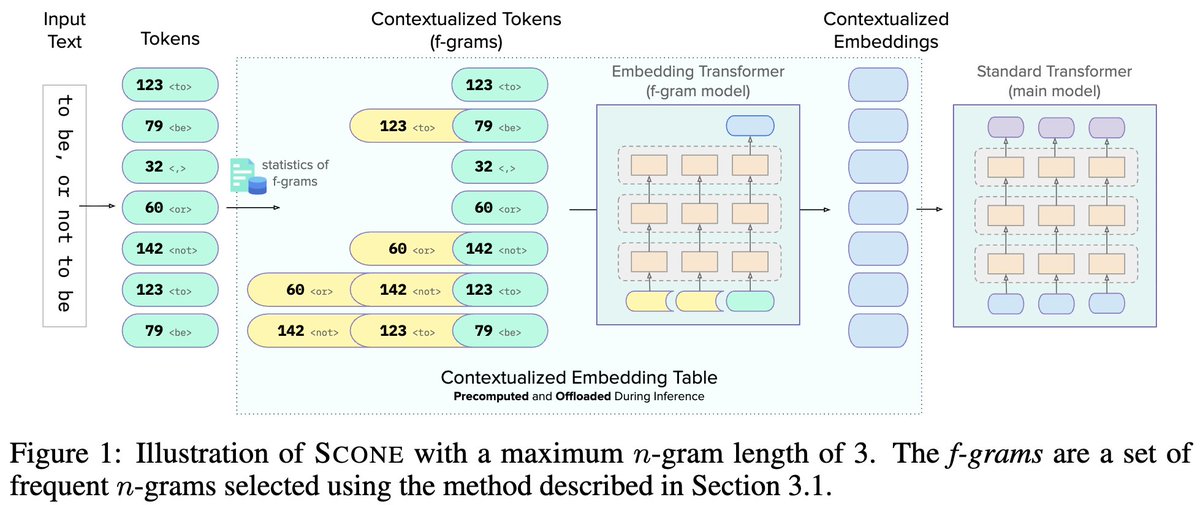 These embeddings do not depend on the context, and this is suboptimal, because tokens with multiple meanings are tied to a single embedding.
These embeddings do not depend on the context, and this is suboptimal, because tokens with multiple meanings are tied to a single embedding. Background:
Background: the LLM, predict the logits for the next token and sort tokens by these logits which in this case would be [" test", " time", " attempt", ...]. Now you can encode the token " attempt" with its position in the ranking, in this case the number 2 [2/6]
the LLM, predict the logits for the next token and sort tokens by these logits which in this case would be [" test", " time", " attempt", ...]. Now you can encode the token " attempt" with its position in the ranking, in this case the number 2 [2/6]
 to the LLM (which would blow up the memory if the sequence is too long) they sequentially compress them (with a factor of M) into smaller representations, in the form of KV-cache [2/4]
to the LLM (which would blow up the memory if the sequence is too long) they sequentially compress them (with a factor of M) into smaller representations, in the form of KV-cache [2/4] 




 1) any-to-any models, with multi-modal input and output. An example is Qwen 2.5 Omni
1) any-to-any models, with multi-modal input and output. An example is Qwen 2.5 Omni


 Results are impressive. In both papers.
Results are impressive. In both papers.
 ViTs benefit from using tokens that encode global information, like the CLS. Having multiple of such "global tokens" helps the transformer, however there is only one CLS: the ViT then "secretly" chooses some low-content patches/tokenes (for example patches of sky) to ... (2/4)
ViTs benefit from using tokens that encode global information, like the CLS. Having multiple of such "global tokens" helps the transformer, however there is only one CLS: the ViT then "secretly" chooses some low-content patches/tokenes (for example patches of sky) to ... (2/4) 

 I do believe the two papers evolved independently, though there's a chance that LayerSkip's authors (October 2024) got the idea from LightGlue (April 2023)
I do believe the two papers evolved independently, though there's a chance that LayerSkip's authors (October 2024) got the idea from LightGlue (April 2023)
 (training a large LLM on many subsets would be unfeasibly expensive).
(training a large LLM on many subsets would be unfeasibly expensive). loguru: a nice logging library. With a few lines of initialization you can call info() and debug() functions that print to stdout and log files without having to pass logger objects around. Also, you can set it to log the error traceback in case your code crashes (last line)
loguru: a nice logging library. With a few lines of initialization you can call info() and debug() functions that print to stdout and log files without having to pass logger objects around. Also, you can set it to log the error traceback in case your code crashes (last line) 