


 Relative Baseline in Bar Plots
Relative Baseline in Bar Plots


 For reference purposes, here are Tabula transforms:
For reference purposes, here are Tabula transforms: 

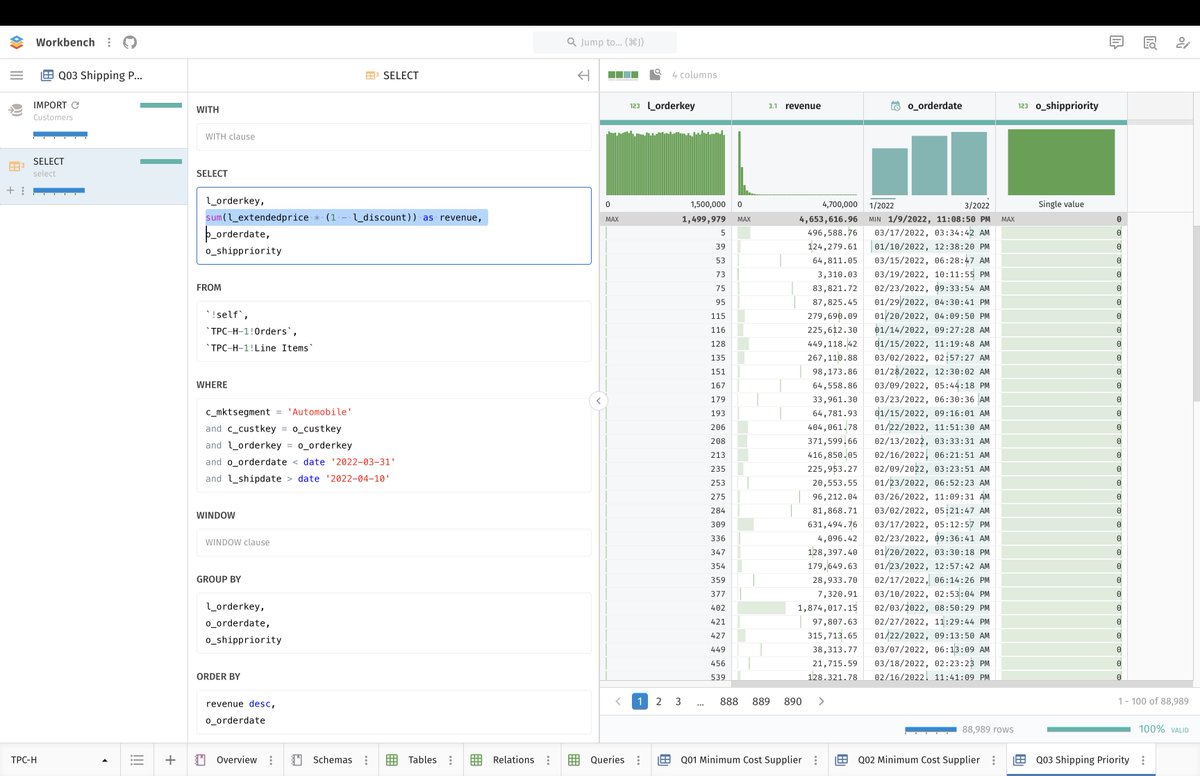
 One of the most critical design elements that make #STOIC work the way it does is its rich data typing system (Principia Data): each and every column is defined with a precise datatype, which conditions how it is serialized, processed, and analyzed.
One of the most critical design elements that make #STOIC work the way it does is its rich data typing system (Principia Data): each and every column is defined with a precise datatype, which conditions how it is serialized, processed, and analyzed.
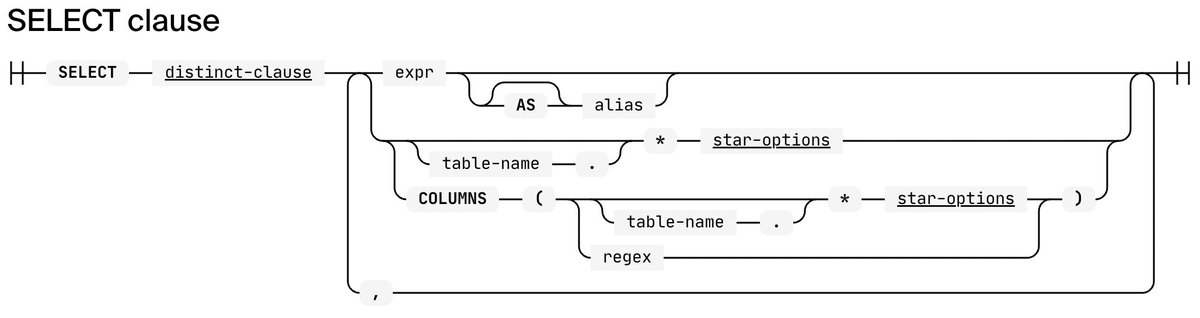
 To be clear, we need a solution that would be compatible with @duckdb's SQL parser and would be as idiomatic as possible. Otherwise, we'll have to invent our own syntax and do some pre-processing. That's always an option, but I'd like to avoid it if possible.
To be clear, we need a solution that would be compatible with @duckdb's SQL parser and would be as idiomatic as possible. Otherwise, we'll have to invent our own syntax and do some pre-processing. That's always an option, but I'd like to avoid it if possible.
 Q2
Q2

