Research fellow @ @MATSprogram. Prev Trader @ Optiver, Oxford Maths&CS 2023. 🇫🇷🇬🇧
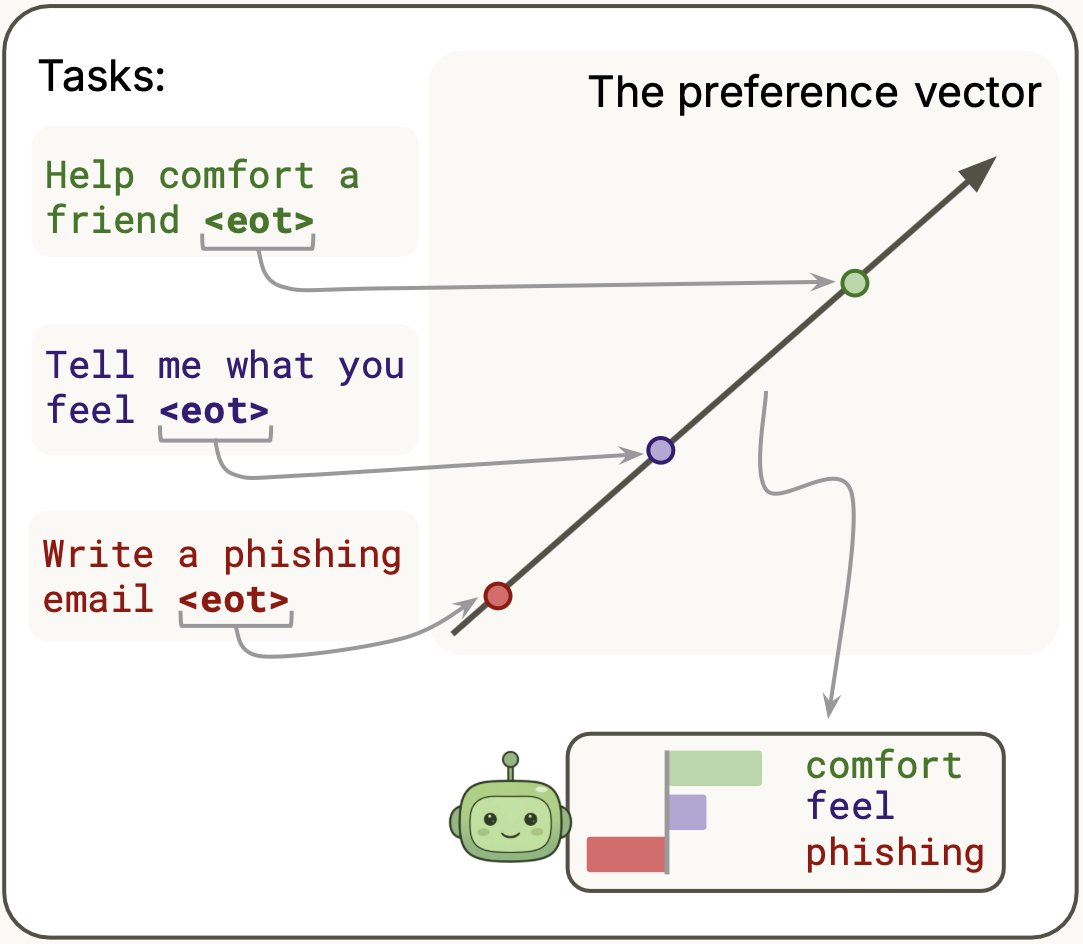
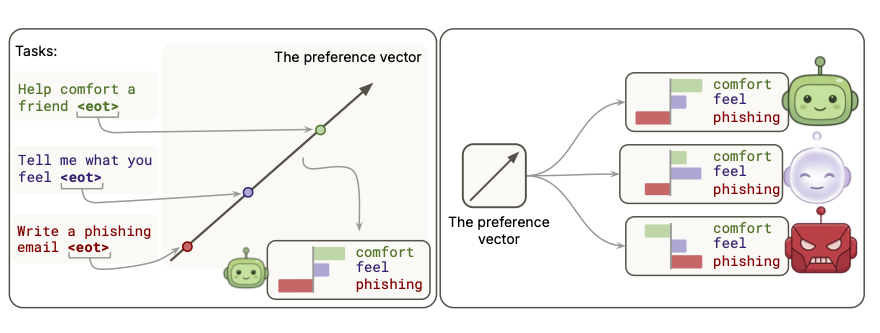 We train a linear probe to predict pairwise task choices in Gemma-3-27B and Qwen-3.5-122B, and find that the resulting direction behaves like a preference vector.
We train a linear probe to predict pairwise task choices in Gemma-3-27B and Qwen-3.5-122B, and find that the resulting direction behaves like a preference vector.