Some long-horizon examples - cleaning the (previously unseen) bedroom: x.com/17672856620873…
Cleaning the (previously unseen) kitchen:
Mar 12, 2024 • 5 tweets • 2 min read
🚨 Big news 🚨
Together with a set of amazing folks we decided to start a company that tackles one of the hardest and most impactful problems - Physical Intelligence
In fact, we even named our company after that: or Pi (π) for short
🧵physicalintelligence.company
We aim to build foundation models that can control any robot for any application including the ones that don't even exist today. We believe that the way to do it is to focus on the hardest part of the robotics problem - intelligence.
Feb 22, 2023 • 5 tweets • 4 min read
Our most recent work showing bitter lesson 2.0 in action:
using diffusion models to augment robot data.
Our robots can imagine new environments, objects and backgrounds! 🧵
We can automatically segment relevant parts of the image and augment them using text-guided diffusion models so that "picking up a coke in the kitchen" can become "picking up a coke *anywhere*."
The additional benefit is trippy videos like this:
Jan 12, 2023 • 12 tweets • 7 min read
Here are a few examples from our work in robotics that leverage bitter lesson 2.0
This is something that I believe we'll see a lot more of (including our own work in 2023)🧵
In SayCan, we showed how we can connect robot learning pipelines to large language models, bringing a lot of common sense knowledge to robotics.
The hope was that as the LLMs become better (which they seem to be consistently doing), it will have a positive effect on robotics.
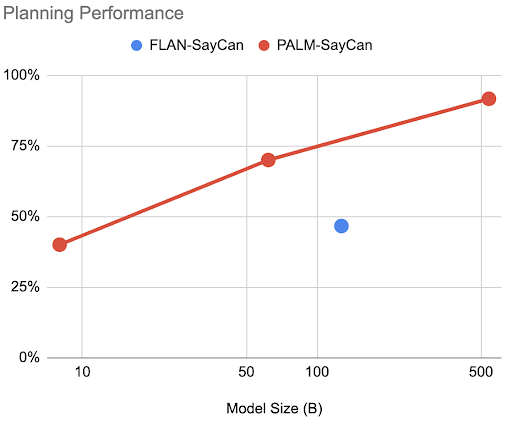
Bitter lesson by @RichardSSutton is one of the most insightful essays on AI development of the last decades.
Recently, given our progress in robotics, I’ve been trying to predict what the next bitter lesson will be in robotics and how can we prevent it today.
Let me explain 🧵
Let's re-visit the original bitter lesson first:
"The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. The ultimate reason for this is Moore's law (...)"
Dec 13, 2022 • 13 tweets • 15 min read
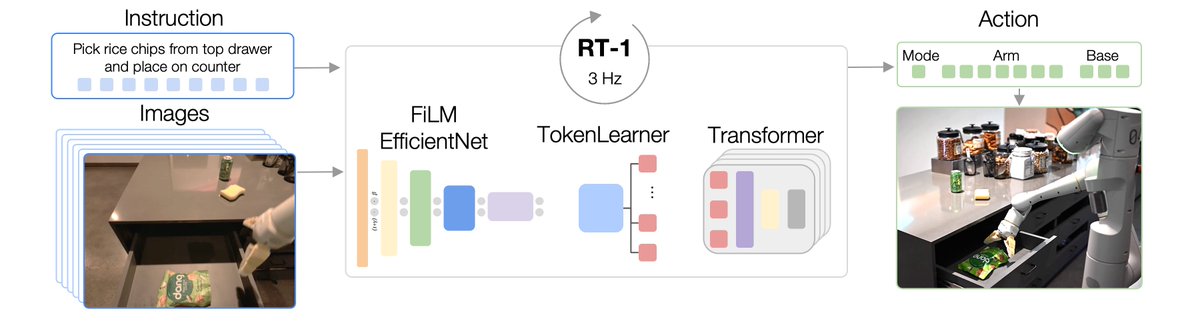
Introducing RT-1, a robotic model that can execute over 700 instructions in the real world at 97% success rate!
Generalizes to new tasks✅
Robust to new environments and objects✅
Fast inference for real time control✅
Can absorb multi-robot data✅
Powers SayCan✅
🧵👇
Based on the success of large models in other fields, our goal was to build a model that acts as an “absorbent data sponge”.
It should get better with diverse, multi-task data. The more data the model can effectively absorb, the better it will be able to generalize.
Apr 6, 2022 • 6 tweets • 4 min read
Training RL from scratch can be very hard, if there is any prior policy you can use to help, you should.
But using prior policies with value-based RL is difficult for various RL reasons.
Introducing Jump-Start RL: a simple, widely applicable method that addresses this problem.
1) use your prior policy (trained from demos, scripted policy or anything else) to guide the agent to get closer to the goal 2) explore with RL from there 3) keep moving backward to let RL explore more
Apr 5, 2022 • 8 tweets • 6 min read
Super excited to introduce SayCan (say-can.github.io): 1st publication of a large effort we've been working on for 1+ years
Robots ground large language models in reality by acting as their eyes and hands while LLMs help robots execute long, abstract language instructions
Basic idea:
With prompt engineering and scoring we can use LLM to break down an instruction into small, actionable steps.
This is not enough though, the LLM doesn't know about the scene, embodiment and the situation it's in. It needs what we call an affordance function!