Research Scientist @nvidiaai GEAR Lab, world modeling lead. On leave from PhD at @uwcse
Feb 4 • 11 tweets • 4 min read
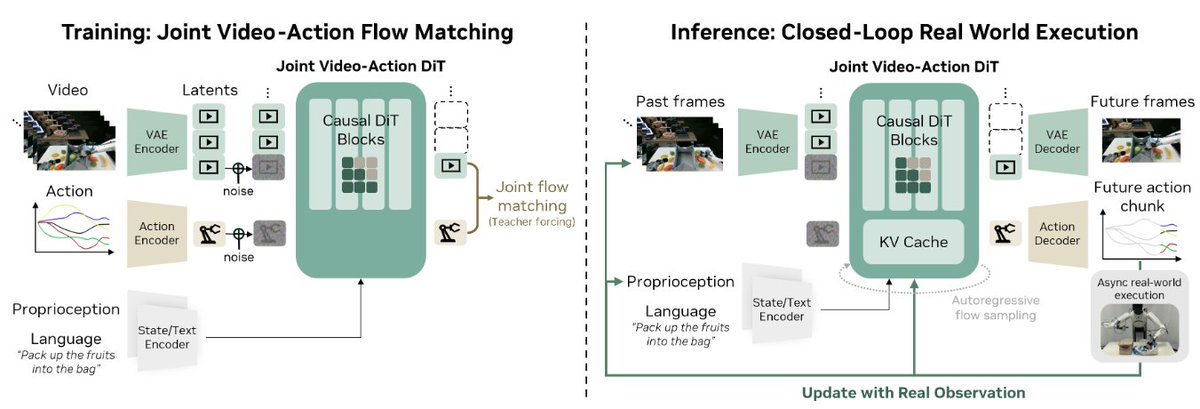
Introducing DreamZero 🤖🌎 from @nvidia
> A 14B “World Action Model” that achieves zero-shot generalization to unseen tasks & few-shot adaptation to new robots
> The key? Jointly predicting video & actions in the same diffusion forward pass
They know WHAT to do (semantics from VLM pretraining) but not HOW to execute with spatial precision (world physics).
"Move coke can to Taylor Swift" ✅
"Untie the shoelace" ❌ (if never trained on it)
(2/10)
May 20, 2025 • 8 tweets • 4 min read
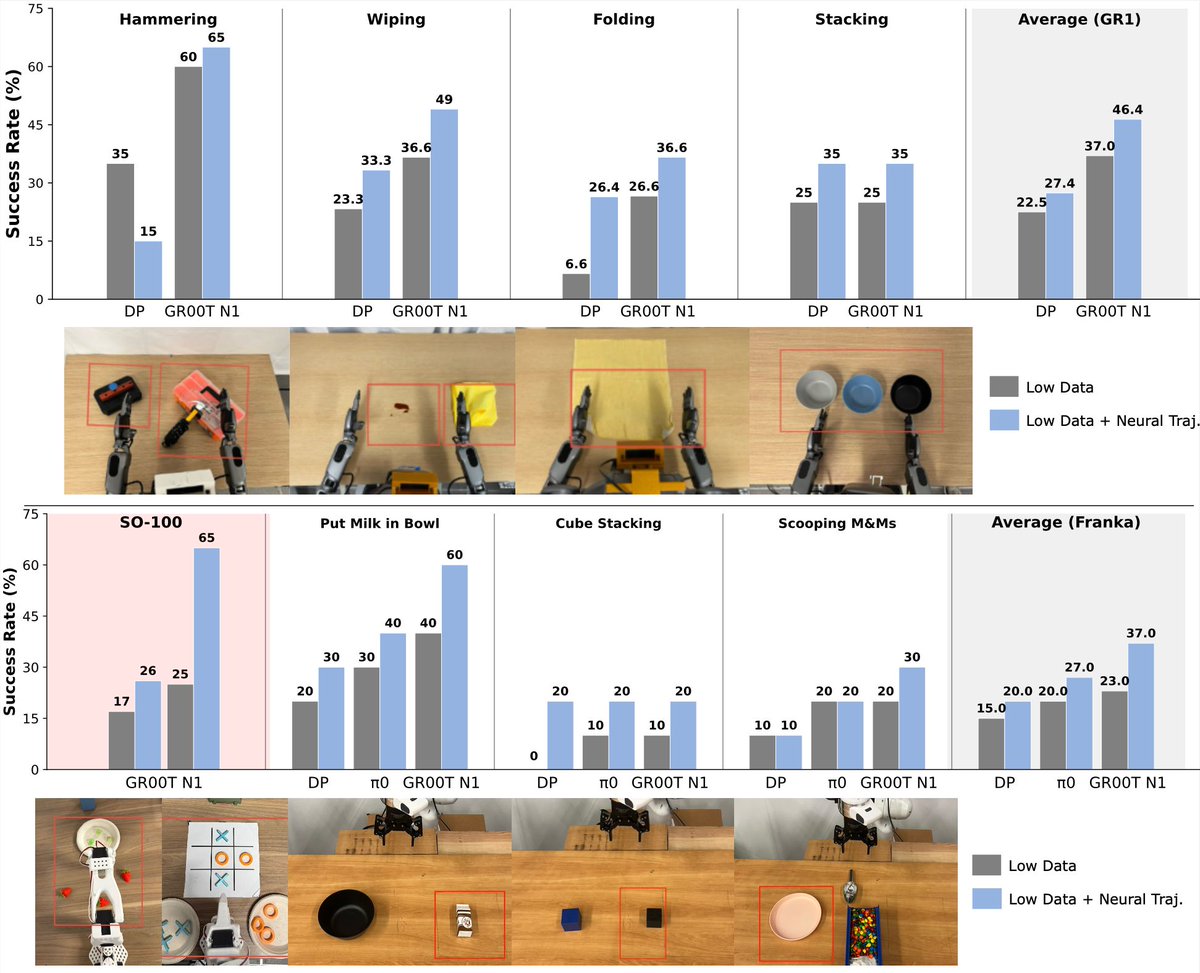
Introducing 𝐃𝐫𝐞𝐚𝐦𝐆𝐞𝐧!
We got humanoid robots to perform totally new 𝑣𝑒𝑟𝑏𝑠 in new environments through video world models.
We believe video world models will solve the data problem in robotics.
Bringing the paradigm of scaling human hours to GPU hours.
Quick 🧵
Currently, robot data scaling is done through human labor. Recent work showed some potential signs of robots doing useful things in unseen homes (i.e., open-world generalization), but this required taking the physical robots and collecting data in 100+ homes.
Oct 16, 2024 • 10 tweets • 4 min read
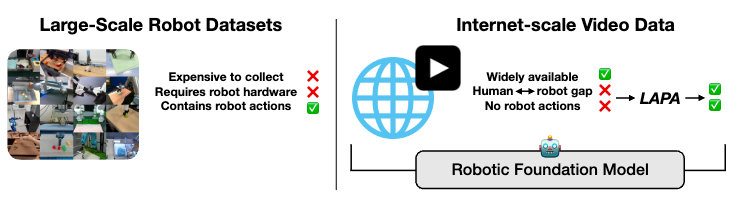
Excited to introduce 𝐋𝐀𝐏𝐀: the first unsupervised pretraining method for Vision-Language-Action models.
Outperforms SOTA models trained with ground-truth actions
30x more efficient than conventional VLA pretraining
📝:
🧵 1/9 arxiv.org/abs/2410.11758
Vision-Language-Action (VLA) models, LLMs aligned with vision encoders, show strong generalization when pretrained on robot datasets, enabling strong generalization capabilities. However, they remain limited by the scope of existing robot datasets.
2/9