
@Meta+NYU. NLP from scratch(Pretrain+FT LLM) 2008,MemNet (pre-Transformer) 2015, DrQA(pre-RAG) 2017, BlenderBot(dialog pre-ChatGPT) 2018+, Self-Rewarding+more!
 🤖 Why is RL for language agents still so hard?
🤖 Why is RL for language agents still so hard?
 Recipe 👨🍳:
Recipe 👨🍳:
 Motivation & analysis🎯:
Motivation & analysis🎯:
 - Online DPO results in a 59.4% increase in AlpacaEval LC winrate & 56.2% in ArenaHard score compared to standard DPO. DPO is poor due to its offline nature.
- Online DPO results in a 59.4% increase in AlpacaEval LC winrate & 56.2% in ArenaHard score compared to standard DPO. DPO is poor due to its offline nature.
 Recipe 👩🍳:
Recipe 👩🍳: 
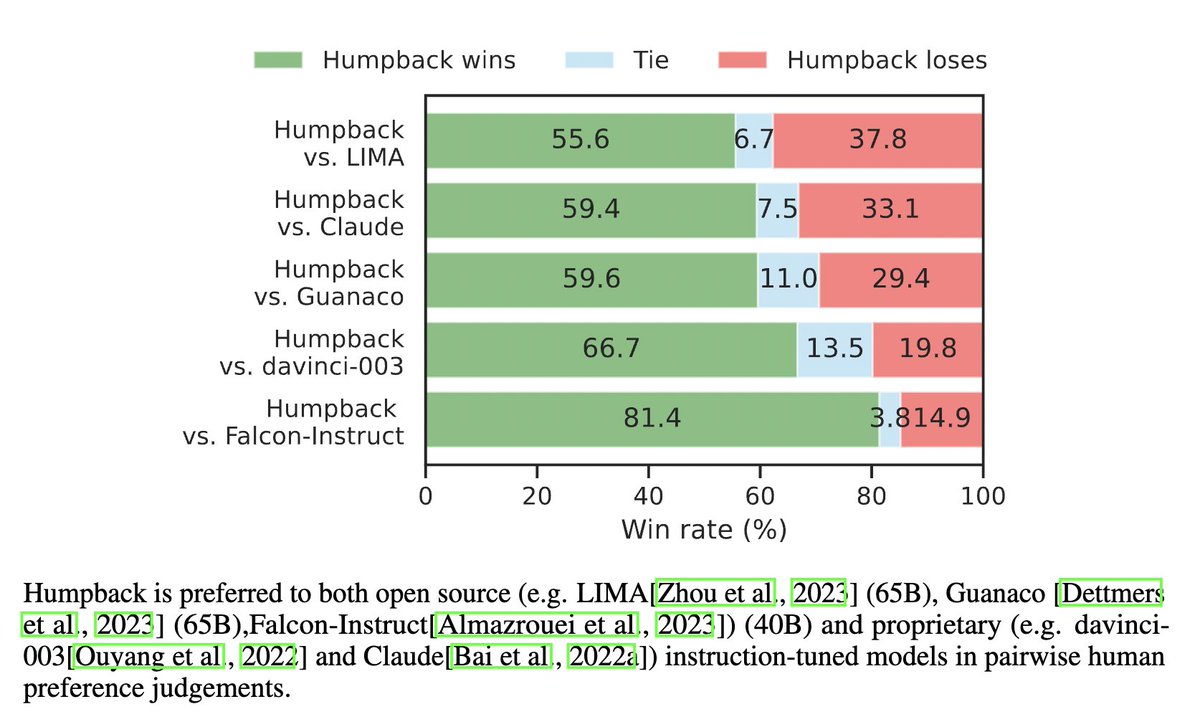 Recipe👩🍳: LLM finetuned on small seed data; access to web docs
Recipe👩🍳: LLM finetuned on small seed data; access to web docs