
 Reasoning models like DeepSeek R1 scale test-time compute solely by generating longer chain-of-thought (CoT)
Reasoning models like DeepSeek R1 scale test-time compute solely by generating longer chain-of-thought (CoT) The recipe:
The recipe:  Progress in SWE agents has been limited by lack of training environments with real-world coverage and execution feedback.
Progress in SWE agents has been limited by lack of training environments with real-world coverage and execution feedback.
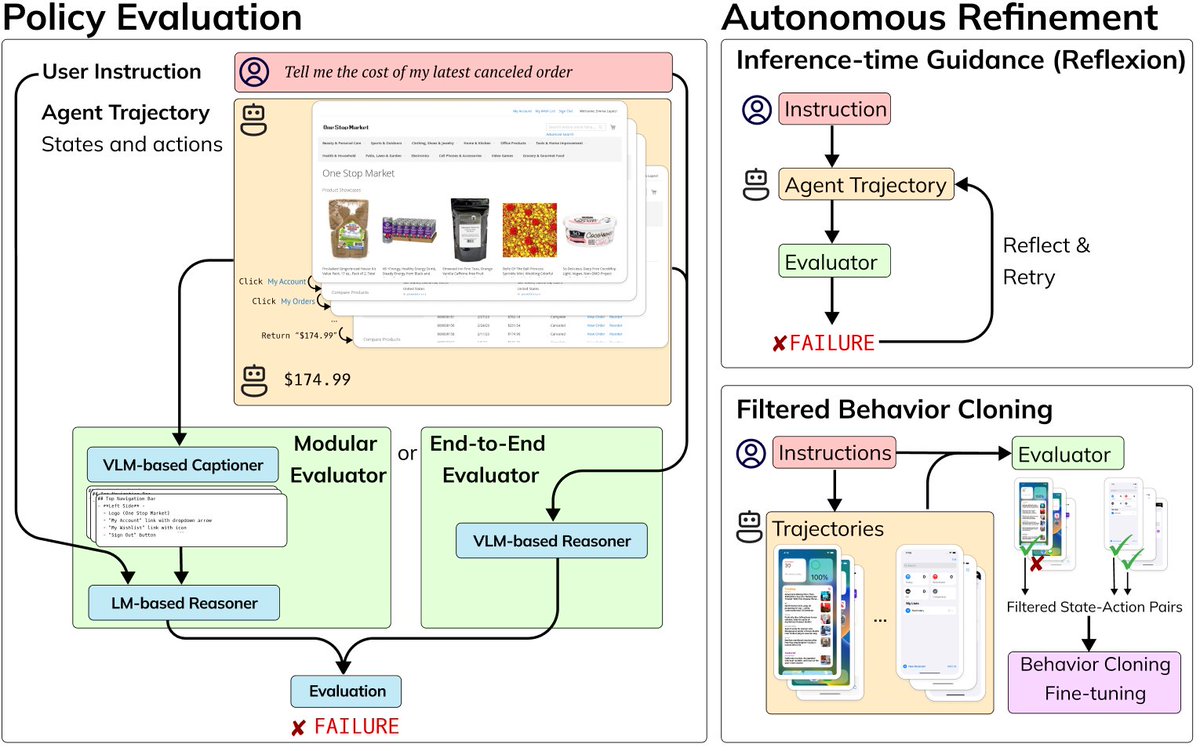 We begin by developing two types of evaluators: one that directly queries GPT-4V and another that employs an open-weight solution. Our best model shows 82% / 93% agreement with oracle evaluations on web browsing and android device control settings respectively.
We begin by developing two types of evaluators: one that directly queries GPT-4V and another that employs an open-weight solution. Our best model shows 82% / 93% agreement with oracle evaluations on web browsing and android device control settings respectively. 