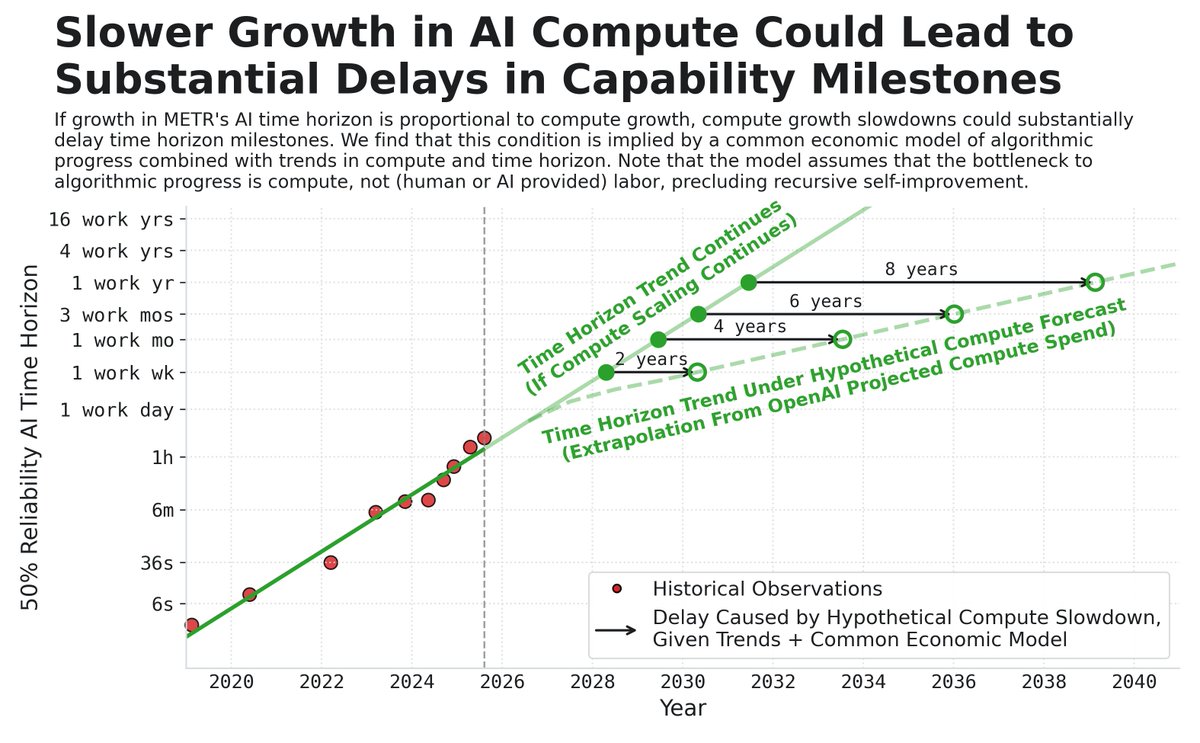
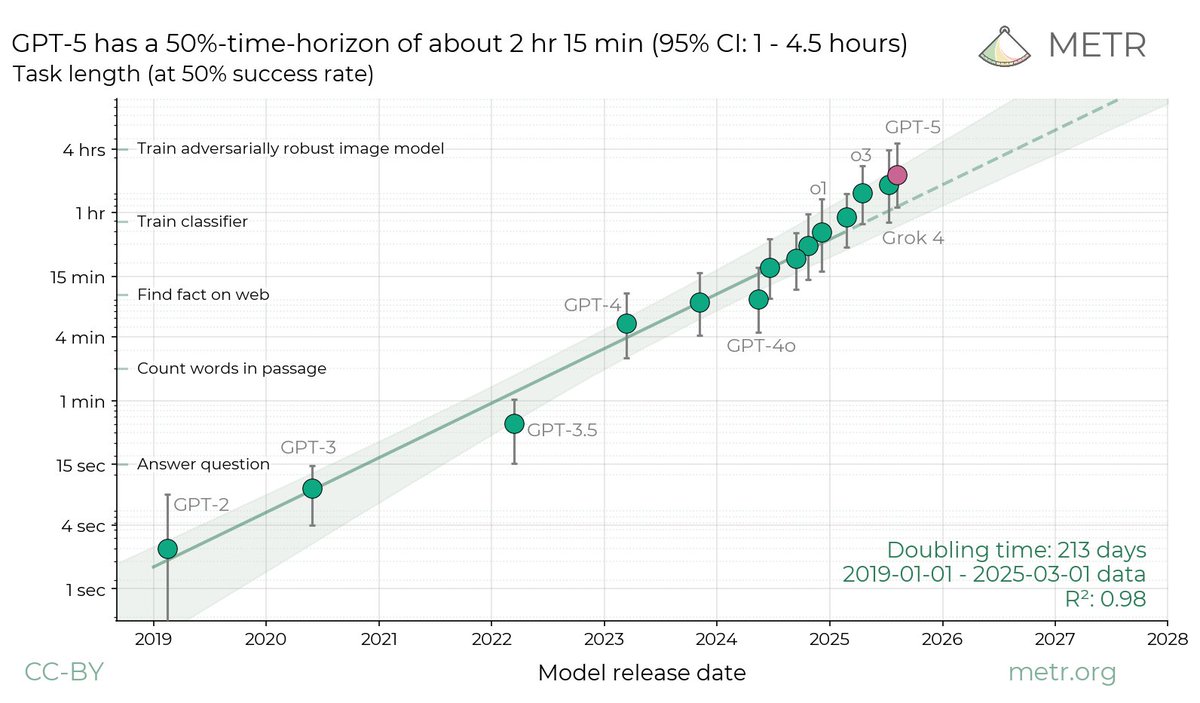
 Fundamentally, the ideas in the paper are extremely simple. Time horizon and compute have been growing exponentially. If compute slows, plausibly time horizon slows. If the slowing is substantial, resulting delays vs. naive trend extrapolation can be quantitatively large.
Fundamentally, the ideas in the paper are extremely simple. Time horizon and compute have been growing exponentially. If compute slows, plausibly time horizon slows. If the slowing is substantial, resulting delays vs. naive trend extrapolation can be quantitatively large. 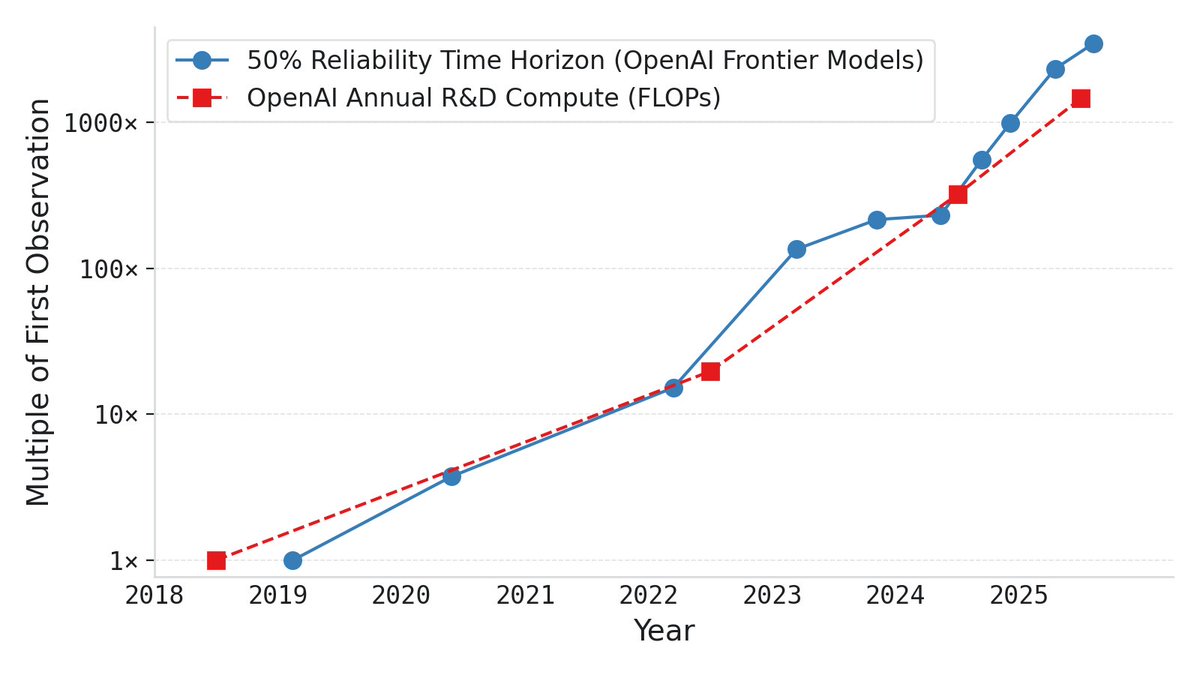
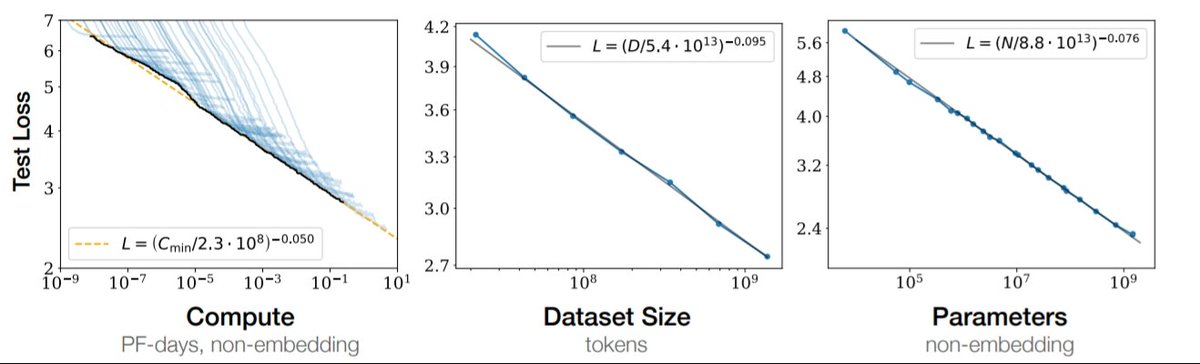
 first part is task-agnostic returns to scale. this is a standard AI story: just add compute. not strictly pre-training compute; any innovation that turned resources into general capabilities (better data filtering, optimizer, instruction following, tool use) would count.
first part is task-agnostic returns to scale. this is a standard AI story: just add compute. not strictly pre-training compute; any innovation that turned resources into general capabilities (better data filtering, optimizer, instruction following, tool use) would count.