Using statistics and programming to turn data into (maximum) utility. Former neuroscientist. Preaches Bayesianism, utilitarianism, and effective altruism.
Dec 10, 2022 • 11 tweets • 4 min read
I know you've all been wondering: Can ChatGPT build generative models of human behavior?
Wait no more! ChatGPT is off to a great start in this conversation but it slowly deteriorates as we get into the specifics, ending in a meltdown. 1/11
Setup: modeling human reaction times. Sadly, most researchers just use means and SD, so ChatGPT is already off to a splendid start.
PNAS just published a paper titled "Experienced well-being rises with income, even above $75,000 per year". The author did not publish the raw data, but luckily, there's enough info to simulate it. I wrote a blog: lindeloev.net/new-pnas-paper… and this thread, 1/7
The central figure shows an impressive linear relationship between log(income) and two measures of well-being. This is from a huge experience-sampling dataset from 33.391 participants. 2/7
Sep 11, 2019 • 11 tweets • 11 min read
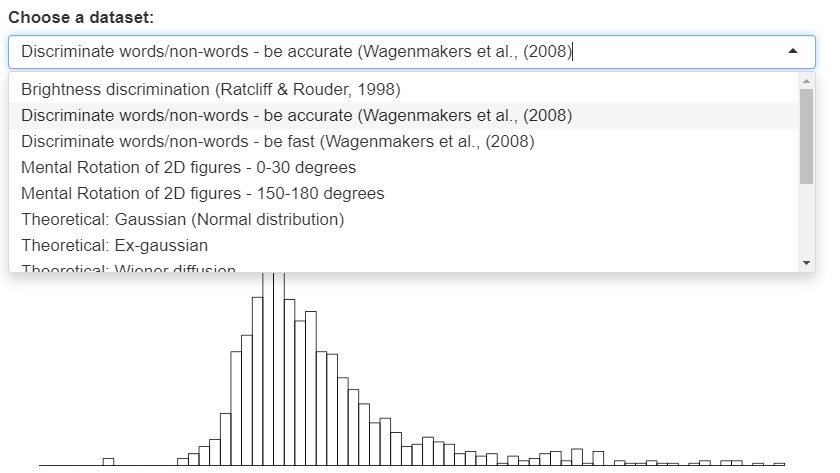
I've made a cheat sheet and a bunch of applets to give you an intuitive feel for various reaction time distributions. You can choose datasets, fiddle with parameters, and see working code examples: lindeloev.net/shiny/rt/ 1/n
You can choose among several pre-existing datasets, e.g., by @EJWagenmakers and @JeffRouder. You can also copy-paste in your own data and try fitting different distributions. 2/n
Apr 15, 2019 • 5 tweets • 5 min read
The R syntax for mixed models, "y ~ 1 + a*b + (1|id)", has two origins. The fixed part is Wilkinson notation from 1973: jstor.org/stable/2346786. The random part was introduced in the nlme package in the late 90s: stats.stackexchange.com/a/285026. It doesn't have a name. 1/5
History confirmed by nlme- and lmer-author Douglas Bates (@BatesDmbates):
. So we may call it *Wilkinson-Bates notation* 2/5
Mar 27, 2019 • 22 tweets • 8 min read
I've made this cheat sheet and I think it's important. Most stats 101 tests are simple linear models - including "non-parametric" tests. It's so simple we should only teach regression. Avoid confusing students with a zoo of named tests. lindeloev.github.io/tests-as-linea… 1/n
For example, how about we say a "one mean model" instead of a "parametric one-sample t-test"? Or a "one mean signed-rank model" instead of a "non-parametric Wilcoxon signed rank test"? This re-wording exposes the models and their similarities. No need for rote learning. 2/n