 We fully swept hyperparameters for both methods and plotted the Pareto Frontier.
We fully swept hyperparameters for both methods and plotted the Pareto Frontier.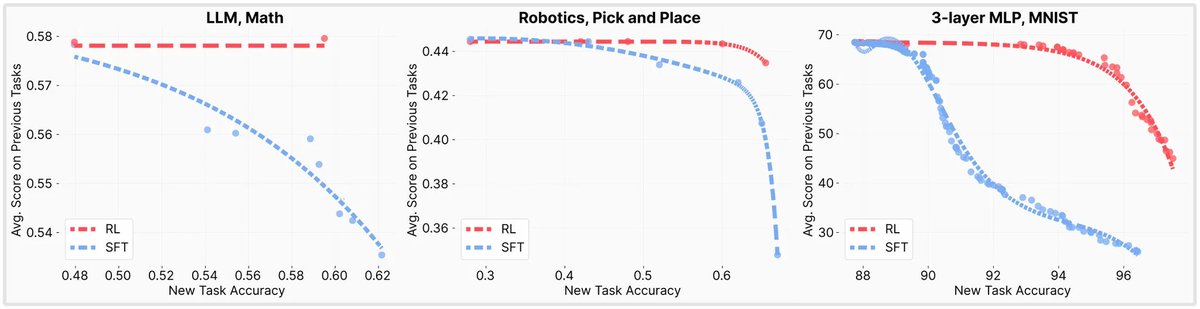
 Self-edits (SE) are generated in token space and consist of training data and optionally optimization parameters. This is trained with RL, where the actions are the self-edit generations, and the reward is the updated model's performance on a task relevant to the input context.
Self-edits (SE) are generated in token space and consist of training data and optionally optimization parameters. This is trained with RL, where the actions are the self-edit generations, and the reward is the updated model's performance on a task relevant to the input context. 
