
Faculty @UCSanDiego @InnovationUCSDH. Chief Health AI Officer @UCSDHealth. Creator of @Tidierjl #JuliaLang. #GoBlue. Views own.

 TidierPlots.jl is getting to be crazily feature-complete, even supporting `geom_text()`, `geom_label()`, and faceting.
TidierPlots.jl is getting to be crazily feature-complete, even supporting `geom_text()`, `geom_label()`, and faceting. 


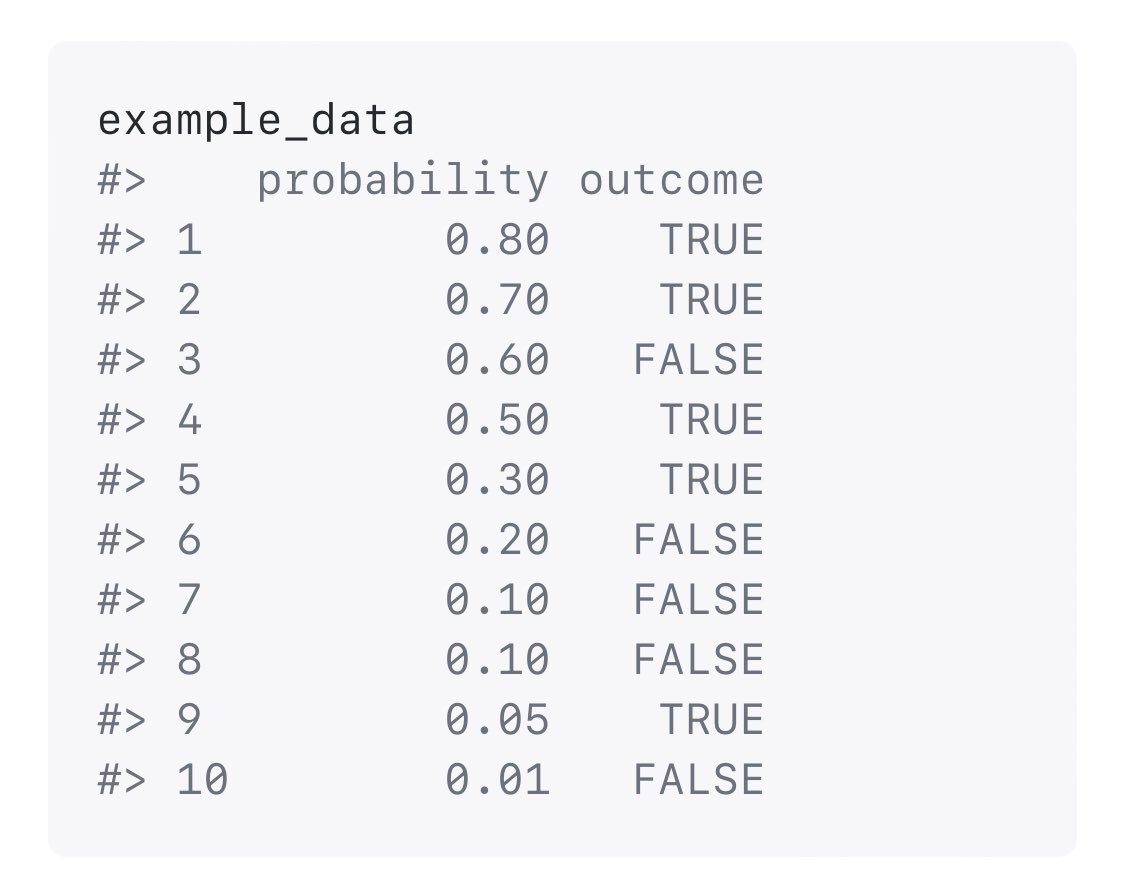
 One interesting thing is that lag() and lead() take in a vector and return a vector (similar to ntile).
One interesting thing is that lag() and lead() take in a vector and return a vector (similar to ntile). If you use distinct() without any arguments, it behaves just like the #rstats {tidyverse} distinct().
If you use distinct() without any arguments, it behaves just like the #rstats {tidyverse} distinct().


 We use 4 case studies to show how a resource constraint diminishes the usefulness of a model and changes the optimal resource allocation strategy.
We use 4 case studies to show how a resource constraint diminishes the usefulness of a model and changes the optimal resource allocation strategy.


 While the FDA was established formally by the FD&C Act in 1938, it didn't gain the authority to regulate medical devices until 1976 when the FD&C Act was amended.
While the FDA was established formally by the FD&C Act in 1938, it didn't gain the authority to regulate medical devices until 1976 when the FD&C Act was amended.
 When people talk about risk stratifying cancer outcomes, there’s an implicit assumption that’s what being modeled is biology.
When people talk about risk stratifying cancer outcomes, there’s an implicit assumption that’s what being modeled is biology.


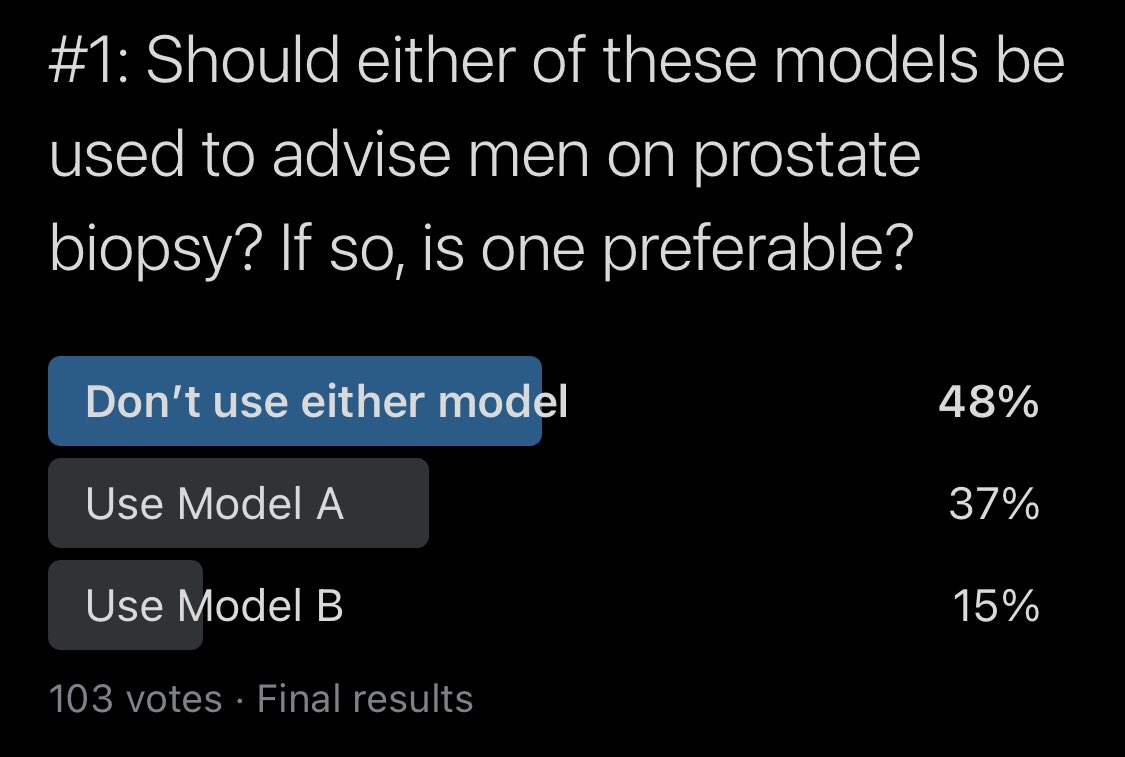
 First, let’s poll folks who felt the model shouldn’t be used. What aspect of the model were you dissatisfied with?
First, let’s poll folks who felt the model shouldn’t be used. What aspect of the model were you dissatisfied with?

 I’ll get to why I voted for Model B but I’ll start in order and share everything I looked at to arrive at that opinion.
I’ll get to why I voted for Model B but I’ll start in order and share everything I looked at to arrive at that opinion.
 One issue that touched a nerve was that in my example, I calculated a post-hoc threshold based on sensitivity. Was I wrong to do this? Let me give an example as to why this happened in this situation, why it *might've* been our only option, and how I would do it differently.
One issue that touched a nerve was that in my example, I calculated a post-hoc threshold based on sensitivity. Was I wrong to do this? Let me give an example as to why this happened in this situation, why it *might've* been our only option, and how I would do it differently.
 Lack of understanding isn't for a lack of trying on the part of its authors. There are dozens of papers w/ thousands of citations!
Lack of understanding isn't for a lack of trying on the part of its authors. There are dozens of papers w/ thousands of citations!