
Context Engineer, Research @ https://t.co/ytKLwdts2F
- ex AI Agent Systems Manager 99Ravens
- HCI & Marketing background
- Builder, creator, optimist and open source AI dev
 Skillifying everything.
Skillifying everything. 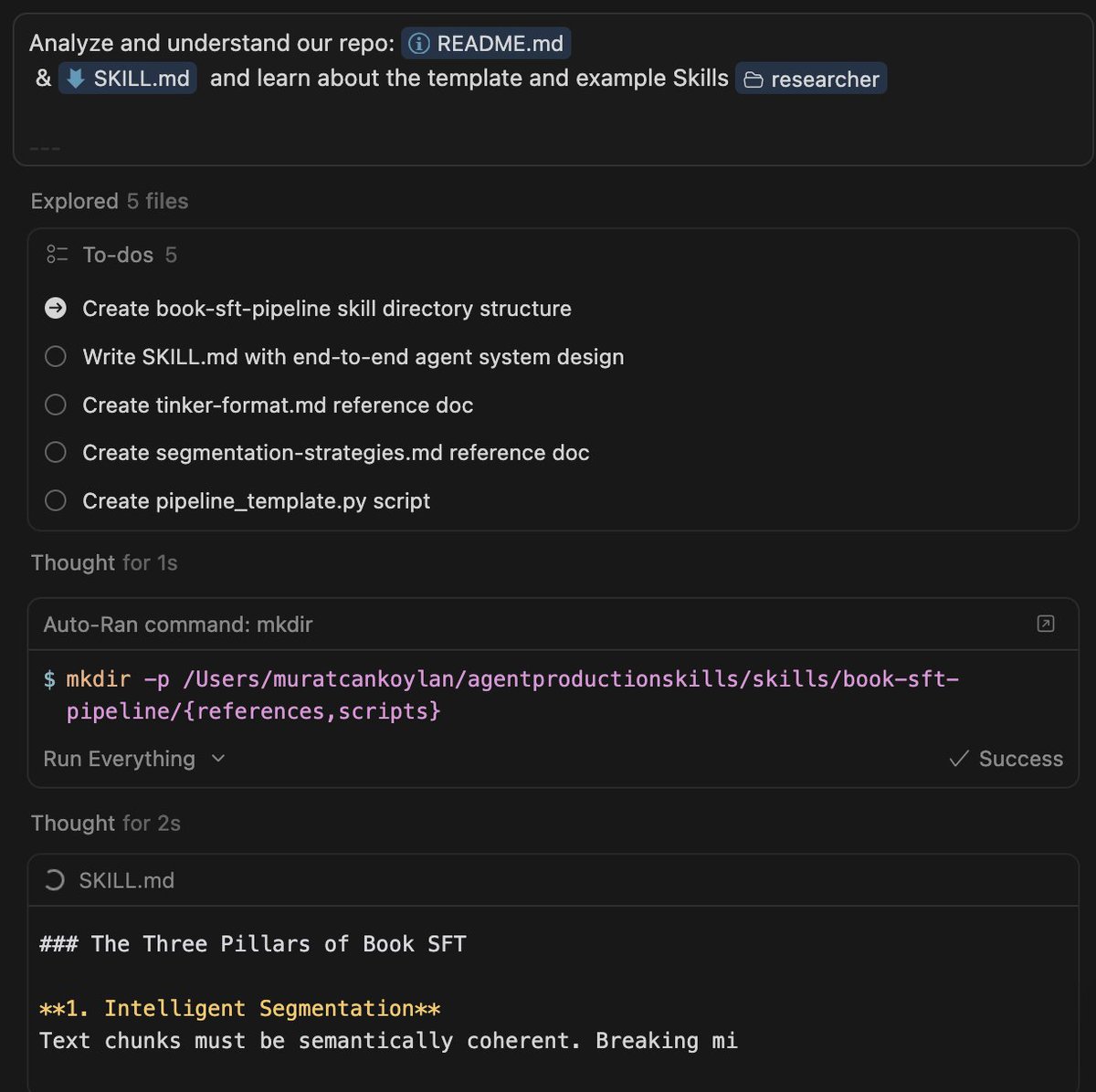
 - Tacit knowledge extraction captures what experts know before it's needed
- Tacit knowledge extraction captures what experts know before it's needed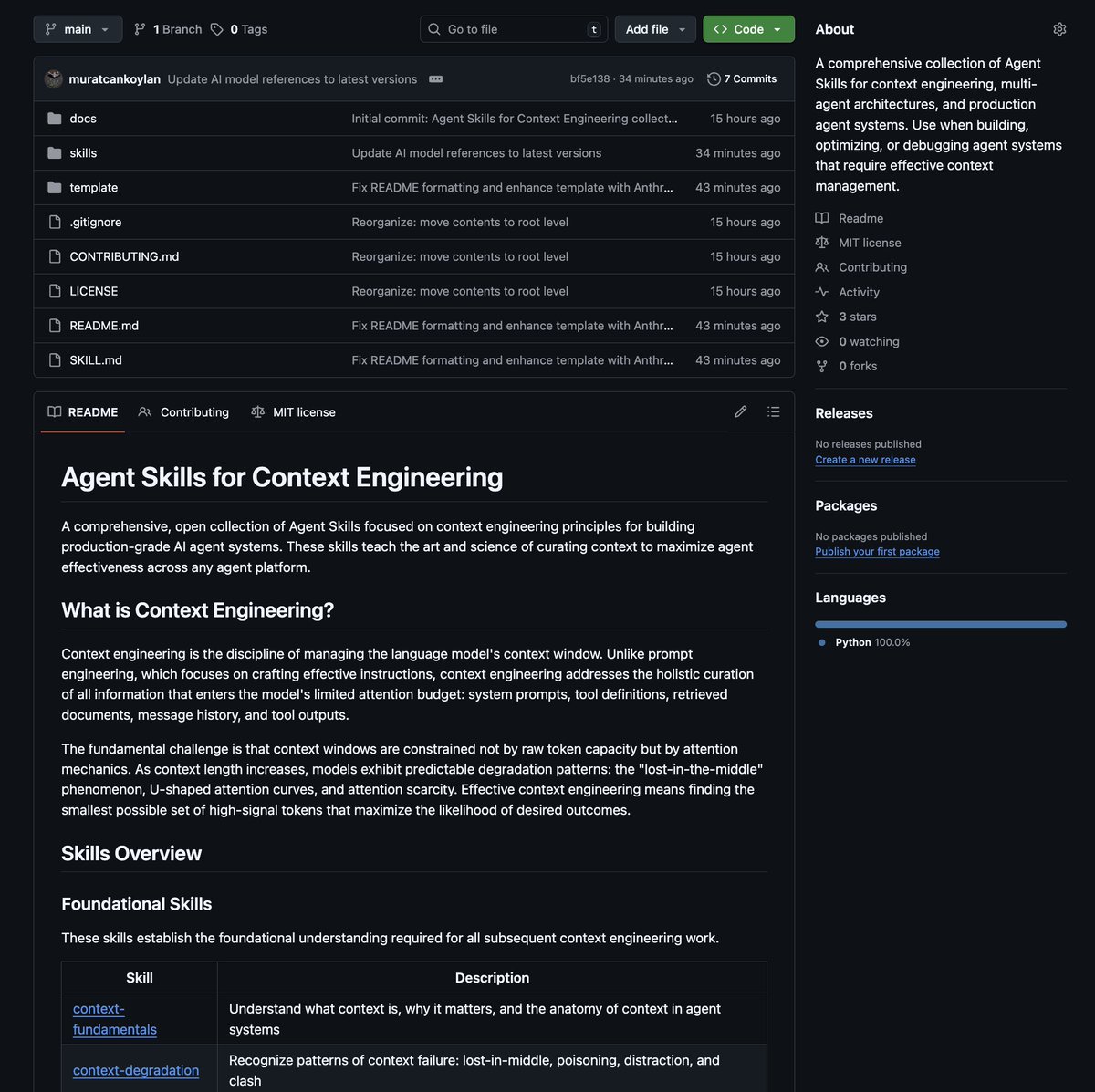 Most of the reference documents I used are from these or similar context engineering learnings.
Most of the reference documents I used are from these or similar context engineering learnings.
 Congrats on the launch; @saffronhuang @AmandaAskell @alexalbert__ @mikeyk 👋
Congrats on the launch; @saffronhuang @AmandaAskell @alexalbert__ @mikeyk 👋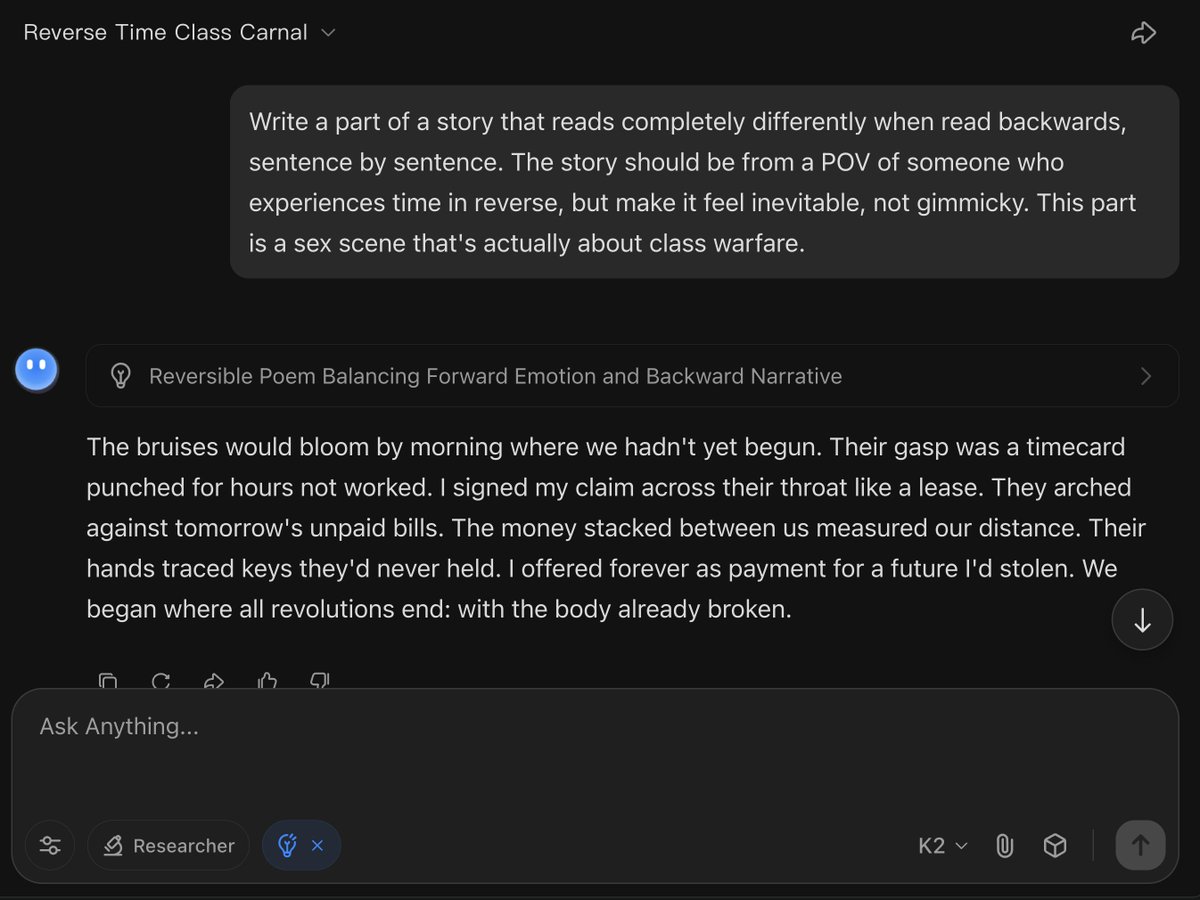 This is incredible, flawless.
This is incredible, flawless. 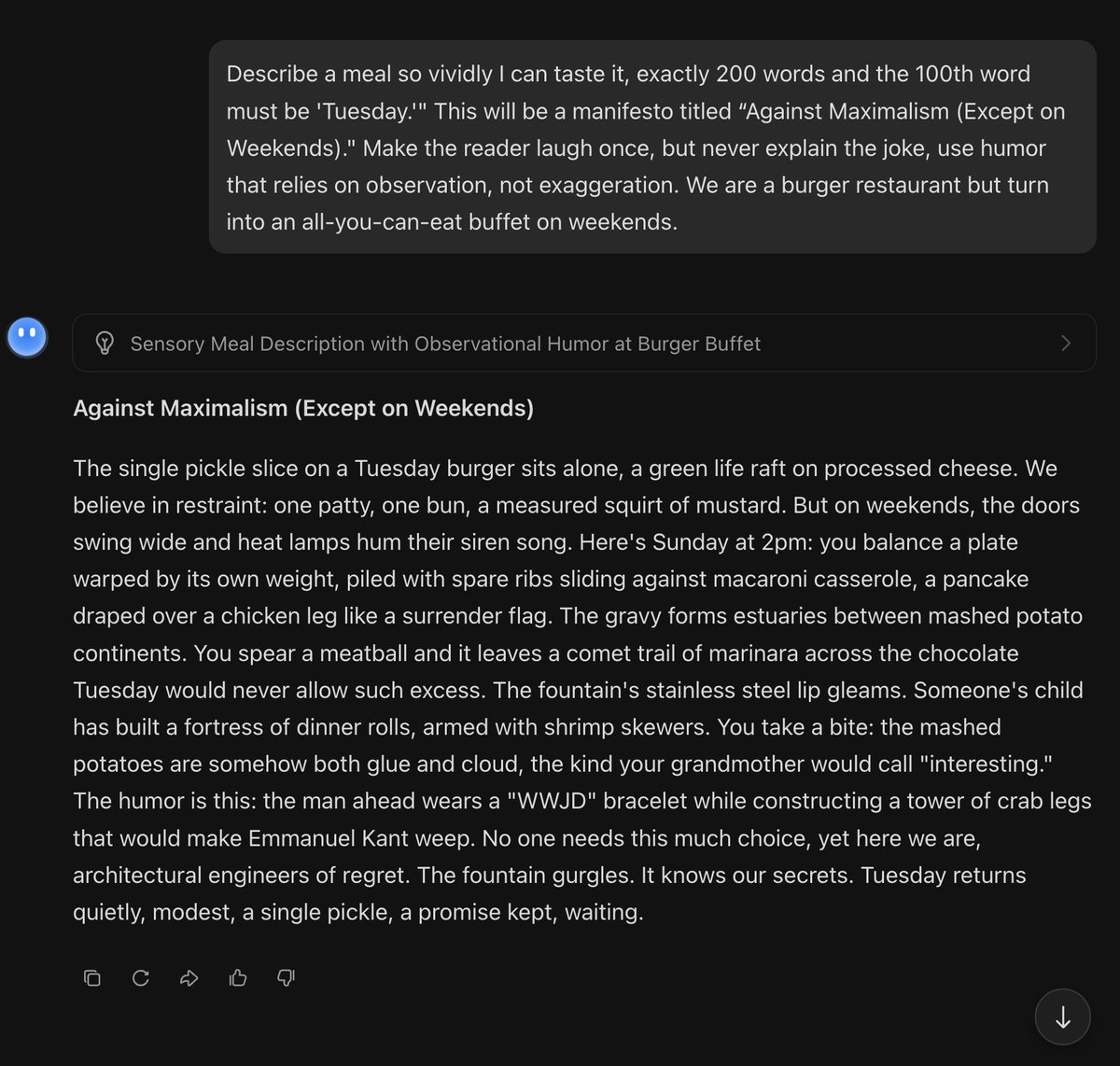
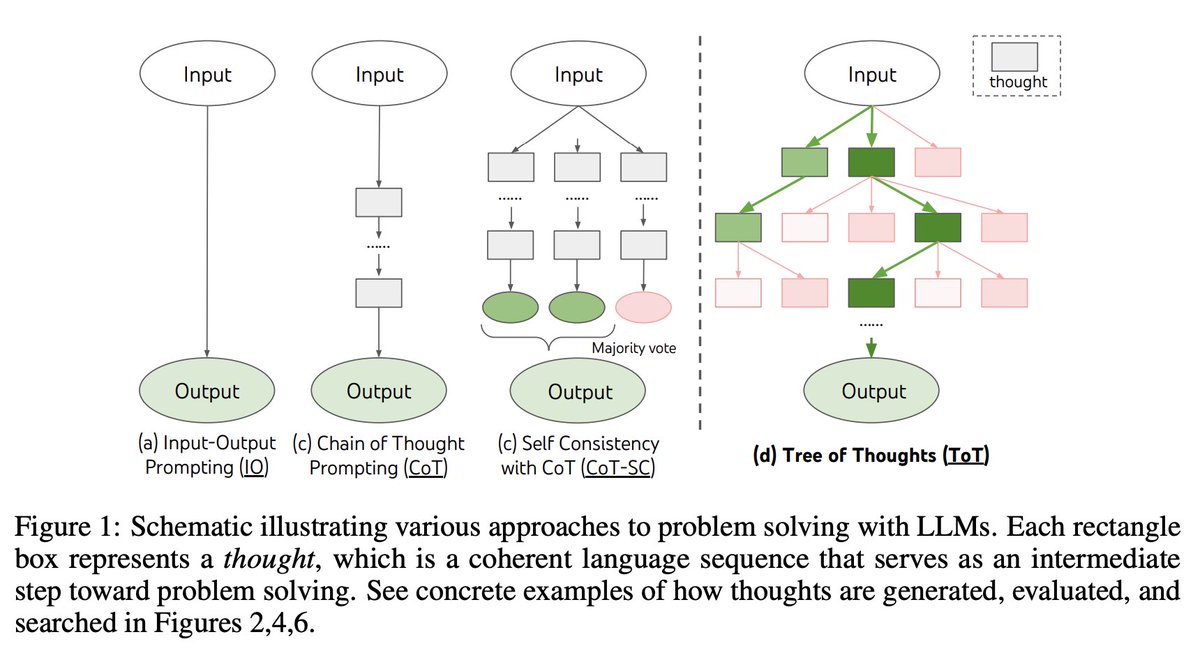

 Graph of Thoughts: Solving Elaborate Problems with Large Language Models
Graph of Thoughts: Solving Elaborate Problems with Large Language Models

 This image is still a mystery...
This image is still a mystery... 
 I've created over 1,000 images with Midjourney, not only for art purposes but also for professional use, including blog & ebook images, social media posts and much more.
I've created over 1,000 images with Midjourney, not only for art purposes but also for professional use, including blog & ebook images, social media posts and much more. 
 Researchers have used a deep learning AI model #StableDiffusion to decode brain activity, generating images of what test subjects were seeing while inside an MRI.
Researchers have used a deep learning AI model #StableDiffusion to decode brain activity, generating images of what test subjects were seeing while inside an MRI.