Research @ScalingIntelLab @HazyResearch | Incoming Research Engineer @mixedbreadai | Building DSRs | MSCS, ColBERT, DSPy @Stanford
 [1] Faster DataLoaders
[1] Faster DataLoaders
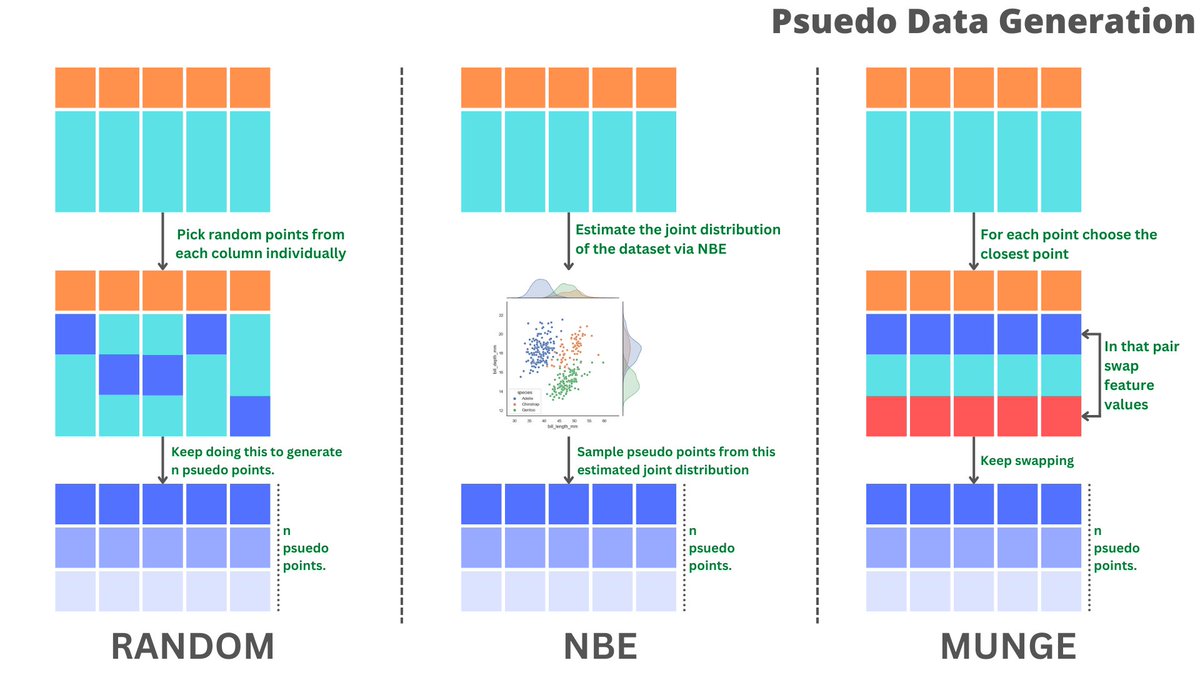
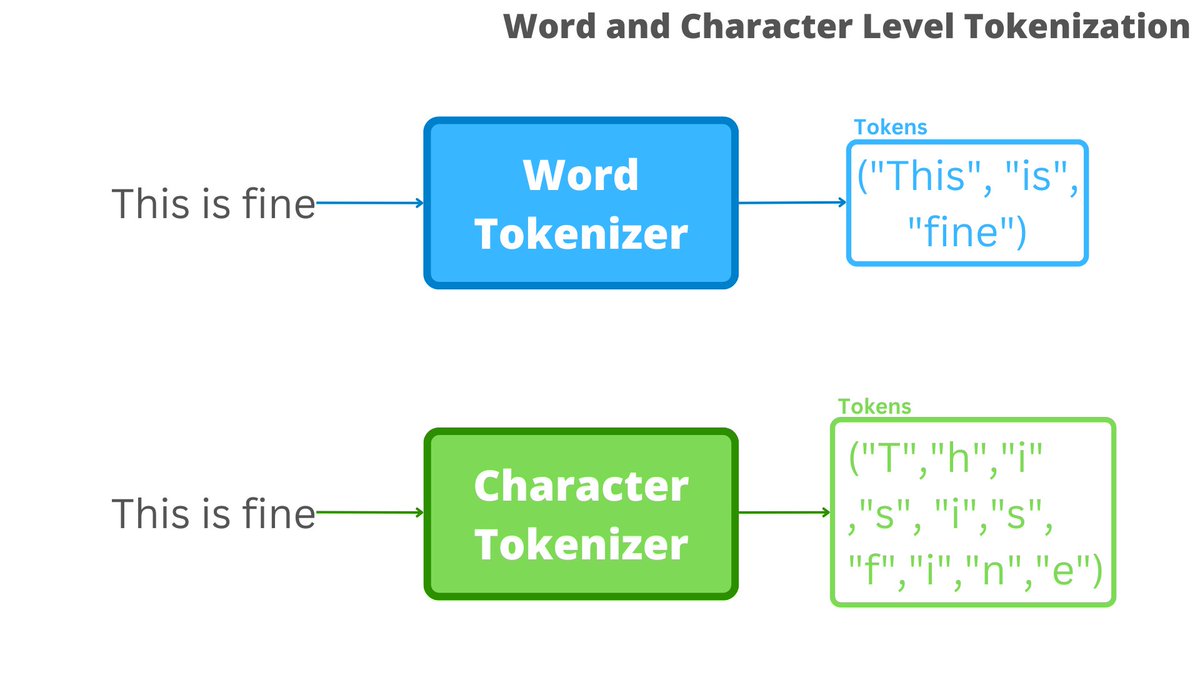
 [1] Motivation
[1] Motivation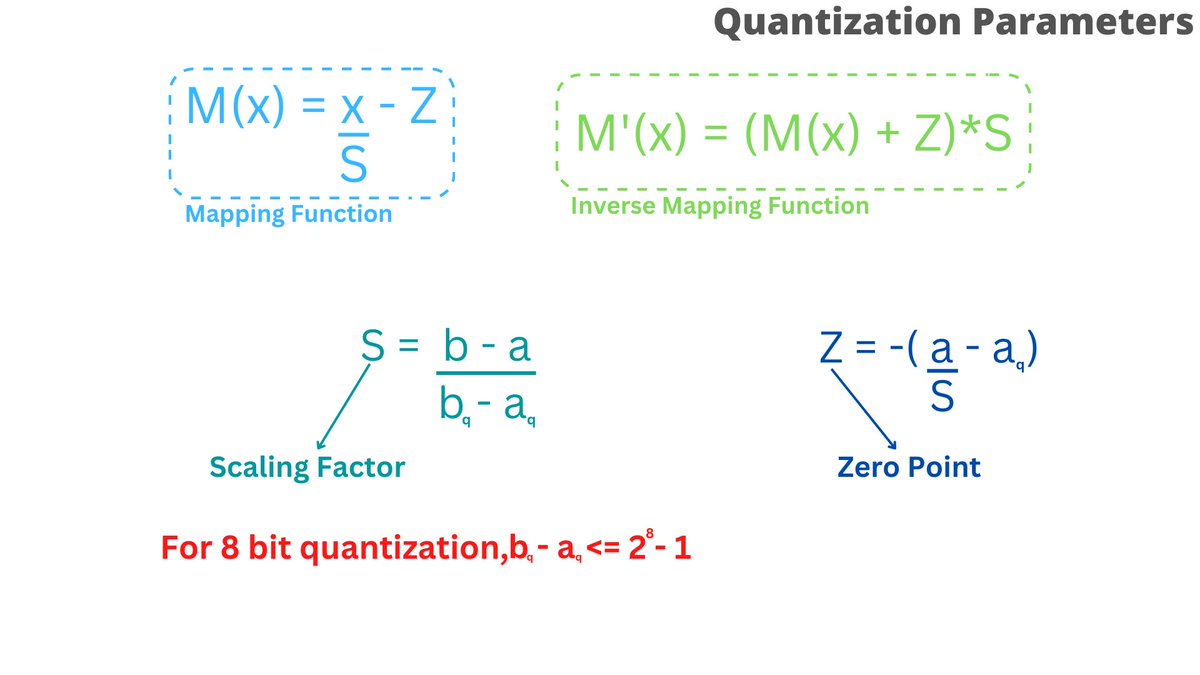
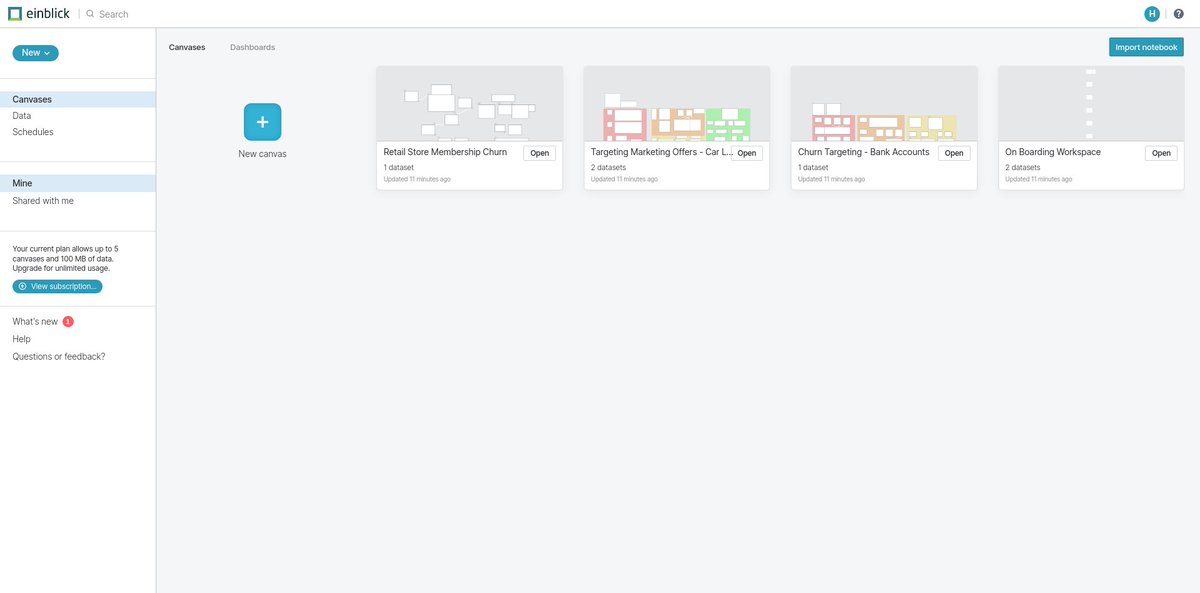 You start by creating a new Canvas. Canvas is to @EinblickAI as Notebook is to Jupyter. Once you create Canvas you'll see the following interface:-
You start by creating a new Canvas. Canvas is to @EinblickAI as Notebook is to Jupyter. Once you create Canvas you'll see the following interface:-