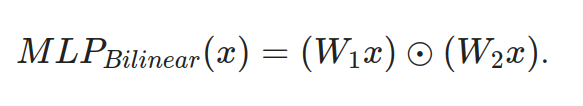Scruting matrices @ Goodfire | Previously: cofounded Apollo Research
May 5 • 9 tweets • 3 min read
My team at @GoodfireAI has been cooking up a new way to do interpretability: decompose a language model’s weights, not its activations.
Our decomposition natively handles attention (!) and behaves less like a lookup table and more like a generalizing algorithm. (1/6)
Networks don’t use all their parameters on a given input. Using causal ablations, we learn to identify the parts of their params that they *are* using.
This lets us find parameter components that play individual computational roles, like emoticon prediction or gender ID. (2/6)
Jan 27, 2025 • 11 tweets • 4 min read
New interpretability paper from Apollo Research!
🟢Attribution-based Parameter Decomposition 🟢
It's a new way to decompose neural network parameters directly into mechanistic components.
It overcomes many of the issues with SAEs! 🧵
A neural network's weights can be thought of as a big vector in 'parameter space'.
During training, gradient descent etches a network's 'mechanisms' into its parameter vector.
We look for those mechanisms by decomposing that parameter vector into 'parameter components'.
May 8, 2023 • 8 tweets • 2 min read
Interpretability is hard. Can we find architectures that are easier to interpret but don't sacrifice too much performance?
Bilinear layers *might* be one such architecture.
As a side project, I took a brief theoretical look at them recently. arxiv.org/abs/2305.03452
1 /🧵
Bilinear layers take the form 2/