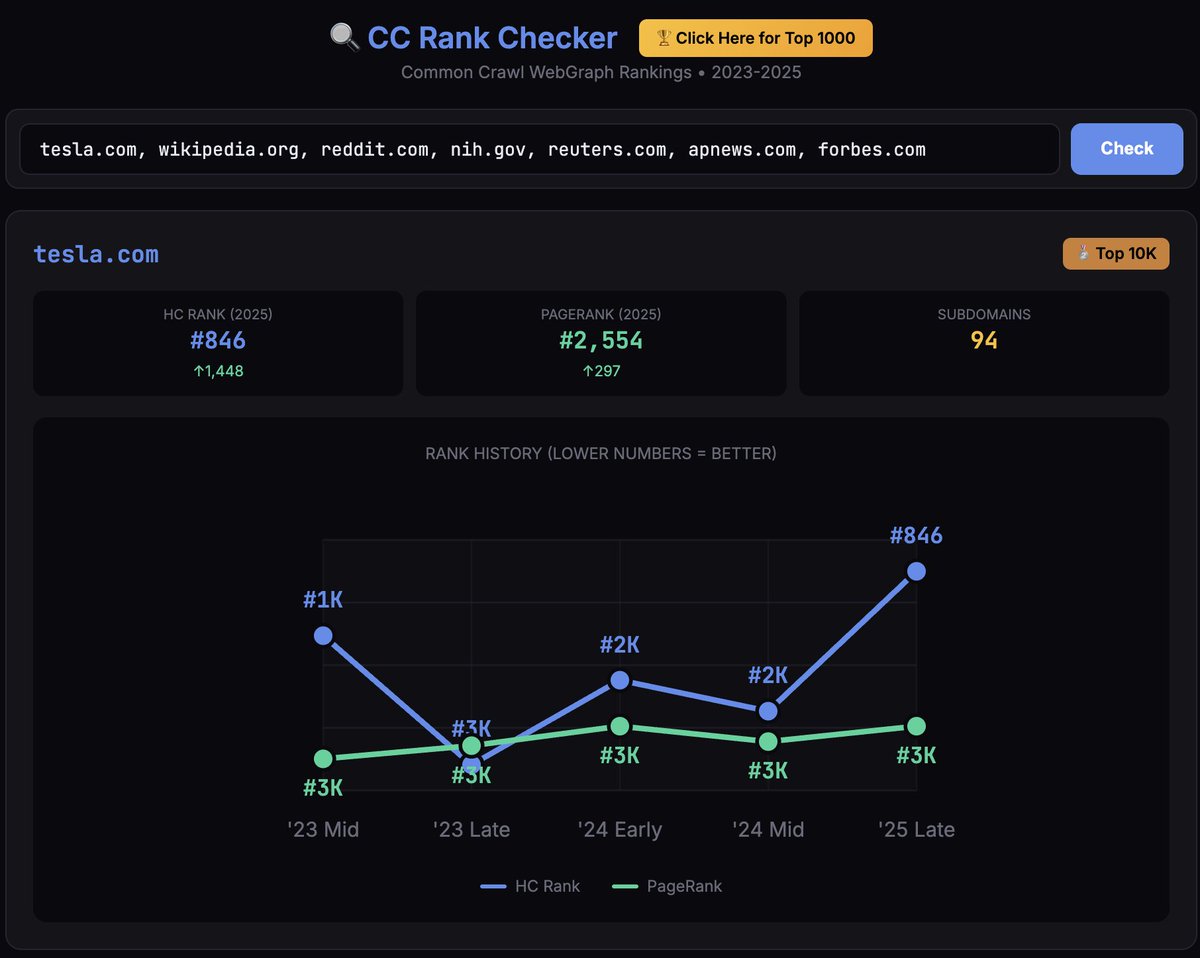
I spent 7 months analyzing 607 million domains. (my Mac is dying)
The question: Why do ChatGPT & LLMs keep citing the same sources?
The answer might be hiding in a dataset most SEOs have never heard of.
I built a free tool with 18M+ domains to expose it. 🧵 (6th tweet)
A THREAD 👇🧵
(1/n)
(2/n)
But there's a layer underneath that nobody talks about:
Common Crawl's WebGraph.
It might be pre-filtering what AI even considers citing.
Nov 27, 2025 • 6 tweets • 2 min read
Google is selling its AI search technology. And it's revealing the infrastructure for AI Mode.
I spent a year inside Google's Discovery Engine. It was also the topic of my BrightonSEO main stage talk in April 2025.
Here's what I found: 7 ranking signals that likely power AI Mode.
*Note: It's the Discovery Engine product and tells about Vertex AI search, not AI mode directly.
A THREAD 👇🧵
(1/n)
(2/n)
And it exposes the exact architecture Google uses for AI-powered search.
The 7 Signals:
→ Base Ranking – core algorithm output
→ Gecko Score – embedding similarity
→ Jetstream – cross-attention model (handles negation better than embeddings)
→ BM25 – yes, keyword matching still matters
→ PCTR – 3-tier engagement system
→ Freshness – time-sensitive query adjustment
→ Boost/Bury – manual business rules
Aug 4, 2025 • 4 tweets • 2 min read
I decoded Perplexity's ranking algorithm through browser requests. 59+ Ranking patterns exposed.
Found a configuration scheme + the near-exact config that controls visibility (tested & succeeded)
These findings might interest you
A THREAD 🧵👇 (1/n)
(2/n)
What I discovered in their config:
📍 new_post_impression_threshold (the magic number)
📍time_decay_rate that KILLS old content for Discover feed.
📍boost_page_with_memory rewards connected articles
📍embedding_similarity_threshold gates everything
📍restricted_topics = entertainment/sports have low multipliers.
Jul 22, 2025 • 6 tweets • 2 min read
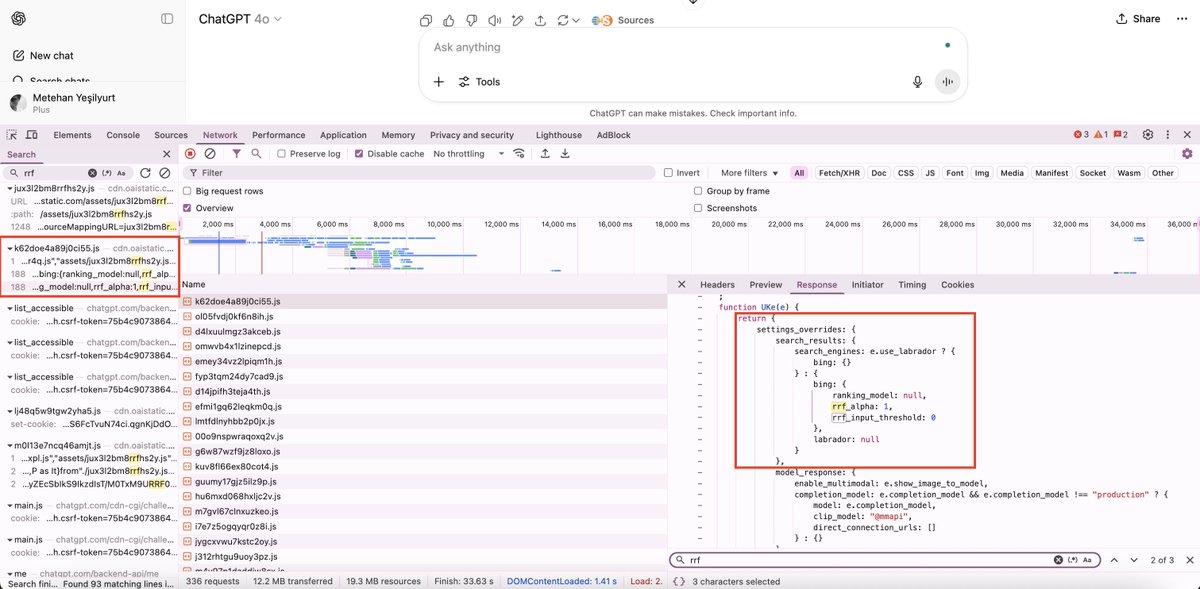
How ChatGPT Ranks Citations (I checked the code) 📊
ChatGPT uses RRF (Reciprocal Rank Fusion): A formula that combines multiple search results. (RRF isn't something new)
Here's what I found in their Chrome DevTools and why it matters for your SEO strategy
A THREAD 👇🧵 (1/n)
(2/n)
First, we know this: AI doesn't search "often" once.
When you ask about "coffee makers," it searches:
🎯 coffee makers
🎯 best coffee machines
🎯 coffee brewing devices
🎯 coffee maker reviews
🎯 home coffee makers
Then combines ALL results using: Score = 1/(60 + rank position)
-The searches are just for simulation.-
Jul 10, 2025 • 4 tweets • 2 min read
I built a page-level LLM Optimization scoring script for @screamingfrog
LLMs can rank content differently from Google.
Recent research tested an idea called Batched Pointwise Scoring, where LLMs evaluate multiple passages together instead of one by one.
It led to better ranking decisions in experiments.
I built a Screaming Frog tool that simulates this logic.
How it works + research-backed experiment 👇
A THREAD 🧵 (1/n)
--EXPERIMENTAL & You STILL need SEO--
(2/n)
Based on LLM research (GPT-4o, Claude, Nova Pro), this method helped models rank more accurately, especially when context mattered.
“Batched Self-Consistency Improves LLM Relevance Assessment and Ranking” (arXiv, May 2025)
“C‑SEO Bench: Does Conversational SEO Work?” (arXiv, June 2025)
The tool extracts structured content (titles, headers, lists, etc.), sends it to Gemini with a custom prompt, and returns:
✅ LLMO score
✅ Top queries
✅ Gaps + fixes
(OpenAI API integration is coming)
Jul 1, 2025 • 5 tweets • 2 min read
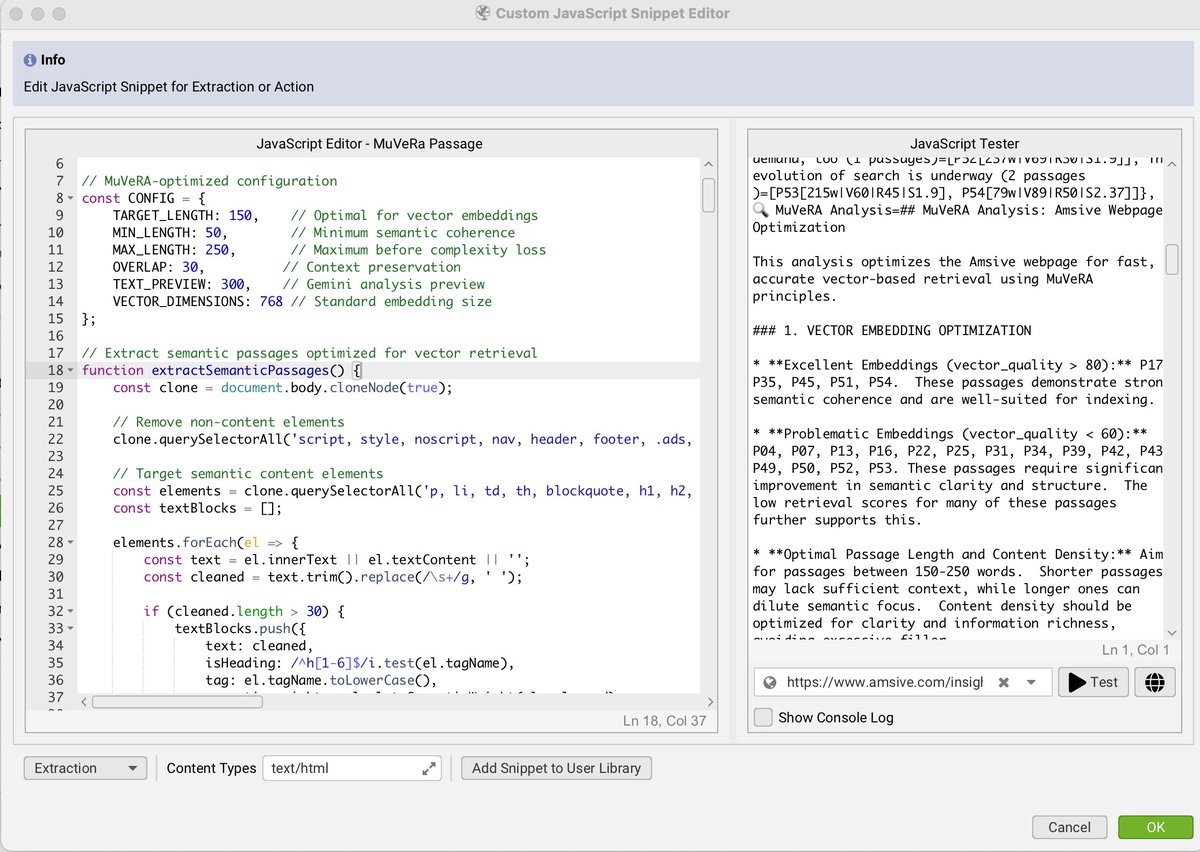
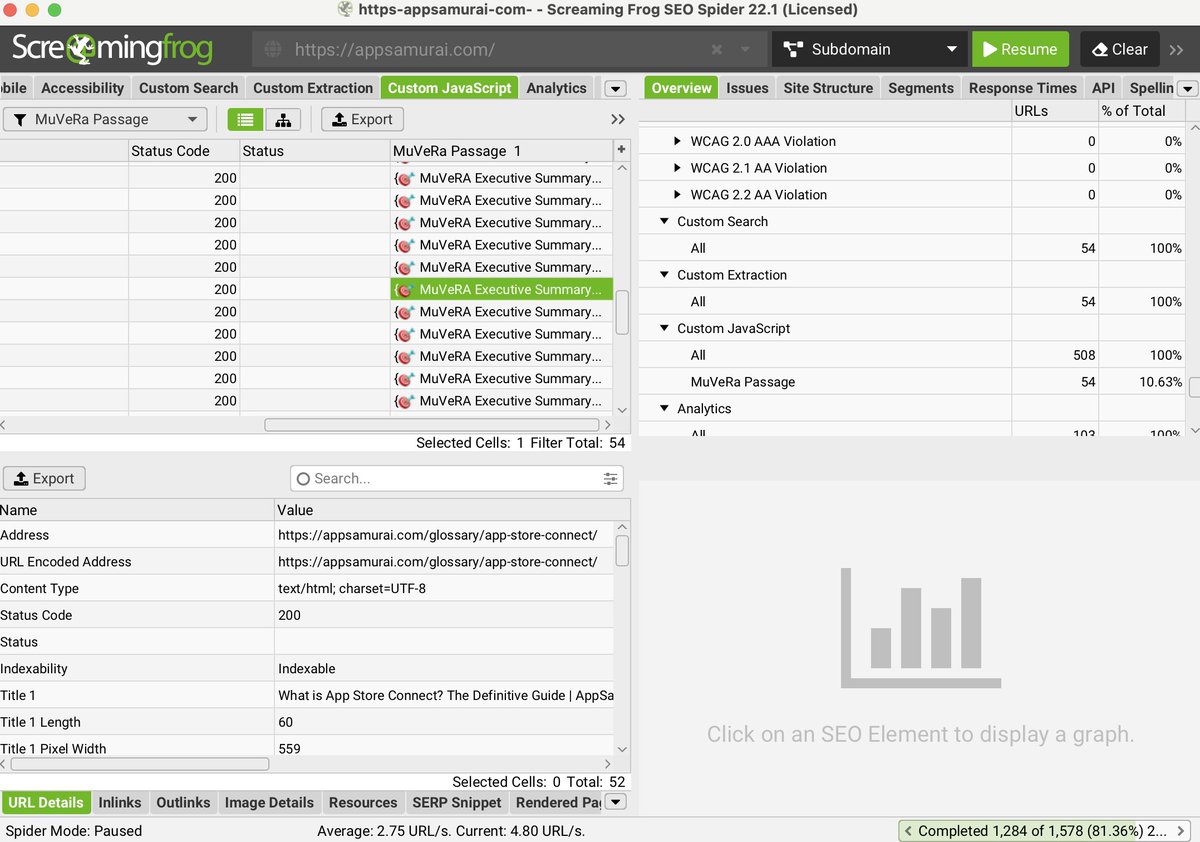
I built a MuVeRA-inspired custom JavaScript snippet for @screamingfrog after reading Google's research on multi-vector retrieval 🚀
Instead of speeding up search (Google's goal), I'm using it to optimize content for better retrieval.
Each passage gets independently analyzed for vector quality. (The full output inside)
Here's how 👇
A THREAD 🧵 (1/n)
--EXPERIMENTAL--
(2/n)
The tool splits content into 150-word passages (optimal for embeddings), assigns quality scores, and identifies which sections would perform best in vector-based search systems.
Think of it as seeing your content through the eyes of modern AI retrieval systems 🔍







 (2/n)
(2/n)