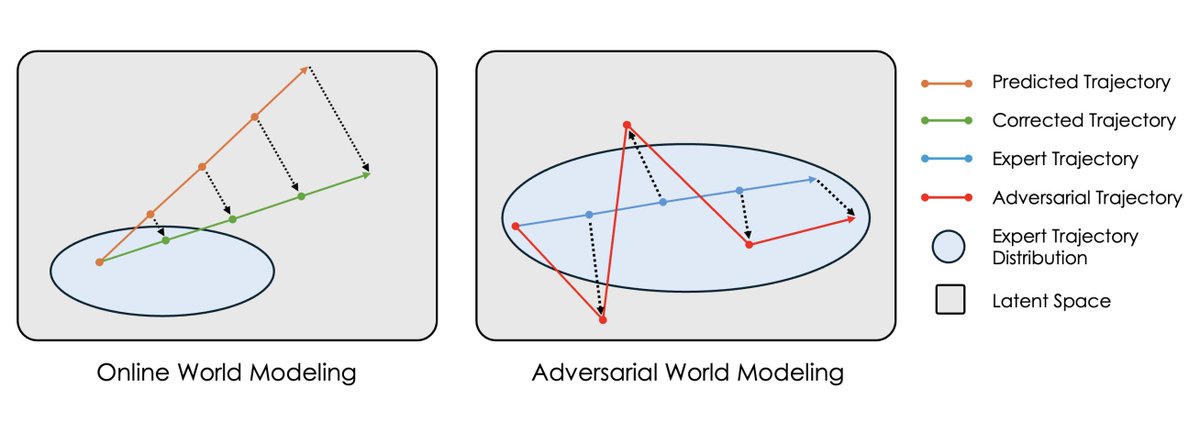
 Gradient-based planning starts with a world model that takes in the current state (e.g. an image) and an action, and predicts the next state. We can stack this world model on top of itself again and again, turning it into a differentiable simulator of the environment. 2/11
Gradient-based planning starts with a world model that takes in the current state (e.g. an image) and an action, and predicts the next state. We can stack this world model on top of itself again and again, turning it into a differentiable simulator of the environment. 2/11 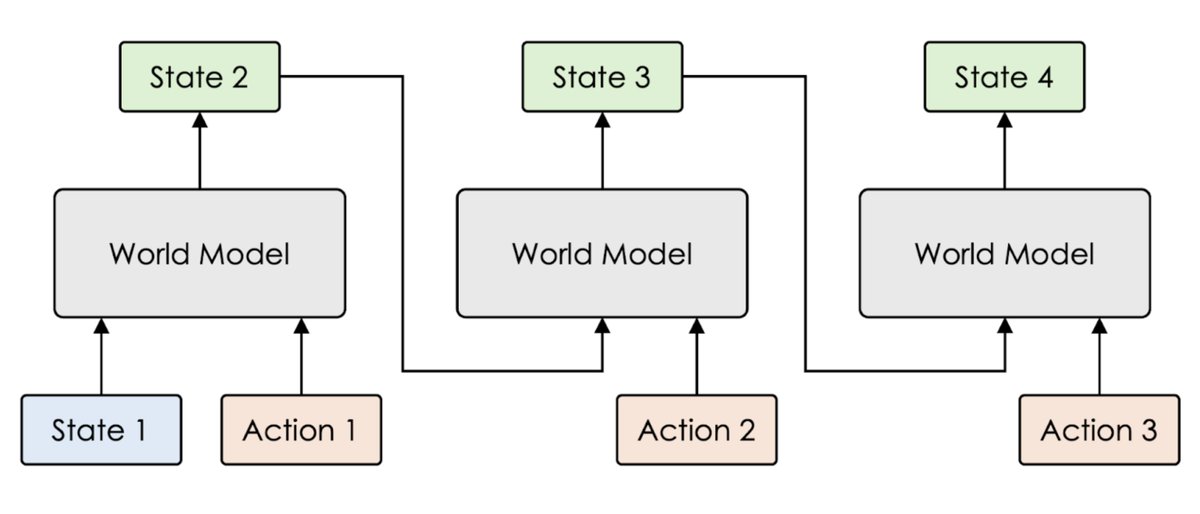
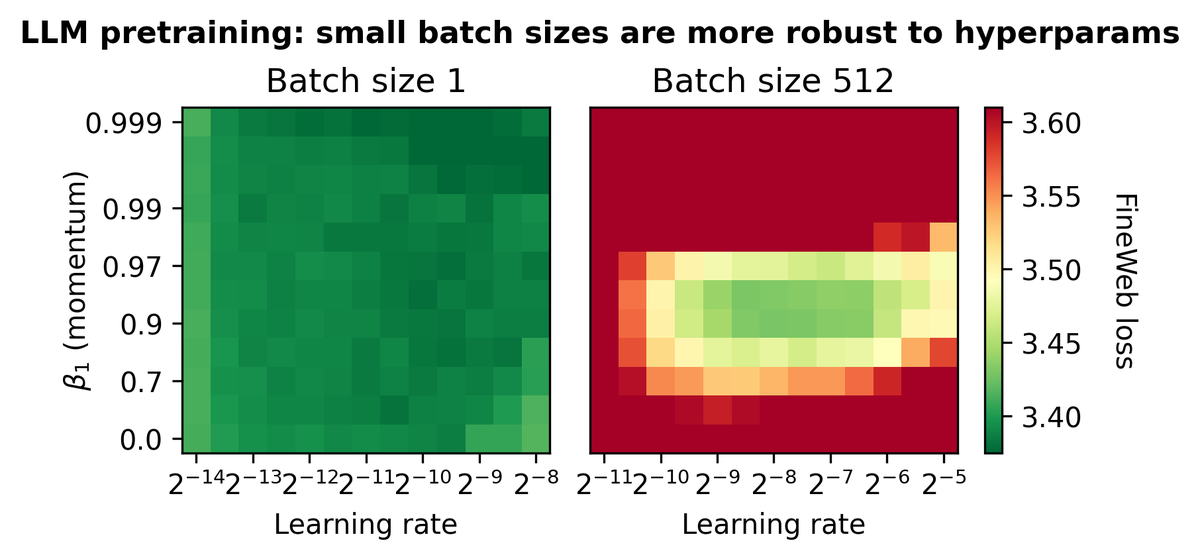
 Here's ★how to make small batch LLM training fast, ★how to pretrain LLMs efficiently via vanilla SGD without momentum, and ★why you should consider getting rid of LoRA and gradient accumulation. 2/n
Here's ★how to make small batch LLM training fast, ★how to pretrain LLMs efficiently via vanilla SGD without momentum, and ★why you should consider getting rid of LoRA and gradient accumulation. 2/n