PhD student at the University of Amsterdam / ILLC, interested in computational linguistics and (mechanistic) interpretability. Current Anthropic Fellow.
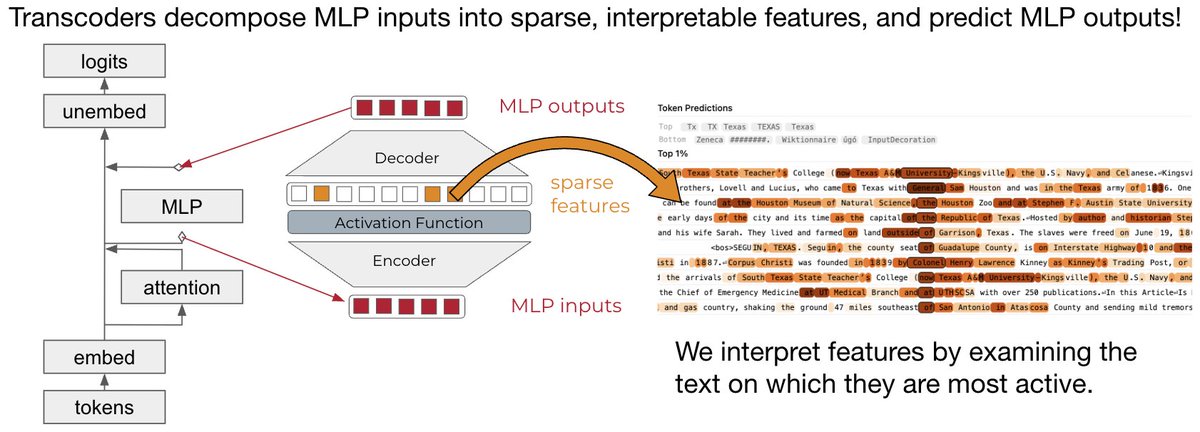
 Circuit-tracer works by taking in a model and set of transcoders, which break down its internal activations into interpretable features.
Circuit-tracer works by taking in a model and set of transcoders, which break down its internal activations into interpretable features.