cofounder/cto @boldmetrics, early @ sonos, incredibly curious about what makes rockets go brrrrr.
 The first thing I do after the initial build is evaluate the codebase, and you don't have to leave Perplexity Computer, you can do this right in there with a prompt like this.
The first thing I do after the initial build is evaluate the codebase, and you don't have to leave Perplexity Computer, you can do this right in there with a prompt like this. 
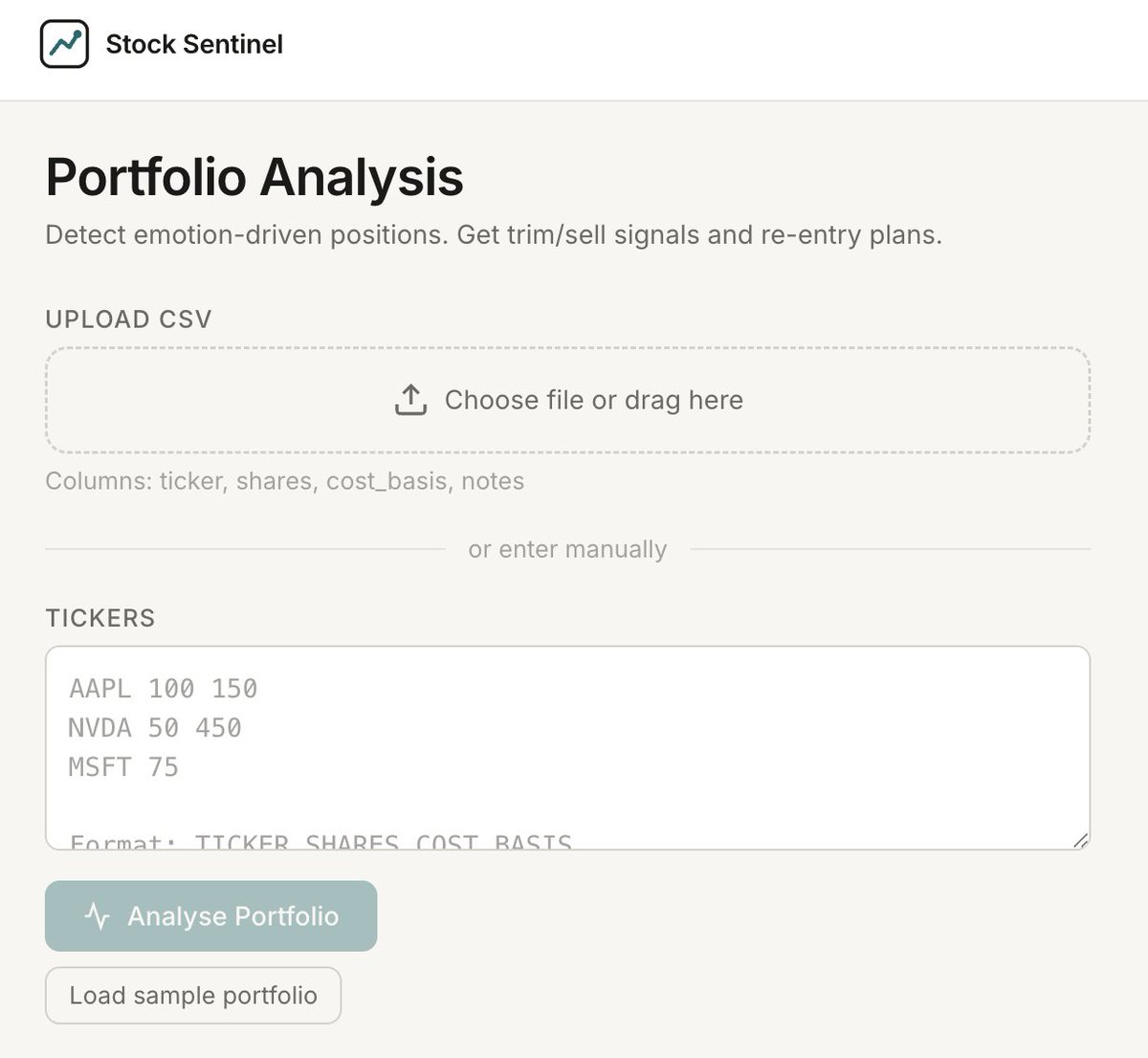
 First, here's the idea I worked on with Perplexity.
First, here's the idea I worked on with Perplexity. 
 First, there’s a Sandbox Mode - enable it.
First, there’s a Sandbox Mode - enable it. 
 While there's a lot of awesome stuff in Dia, the key feature I use daily, constantly, is the ability to chat with tabs.
While there's a lot of awesome stuff in Dia, the key feature I use daily, constantly, is the ability to chat with tabs.