Tweets popular AI papers; by @labmlai
Chrome extension https://t.co/SyfujSq5df

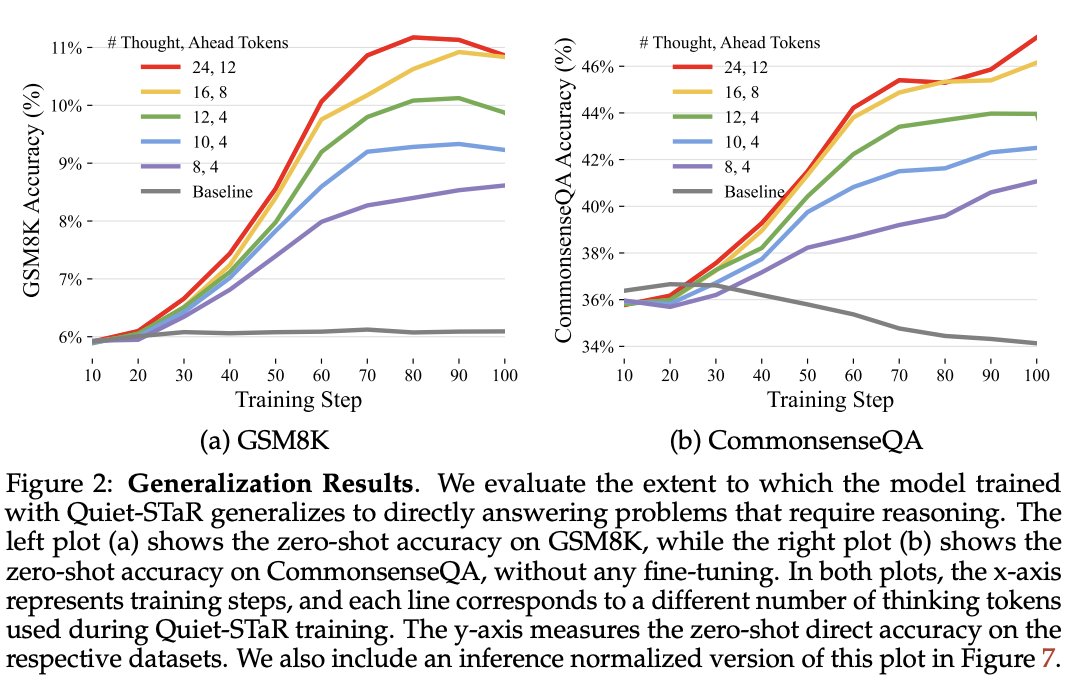

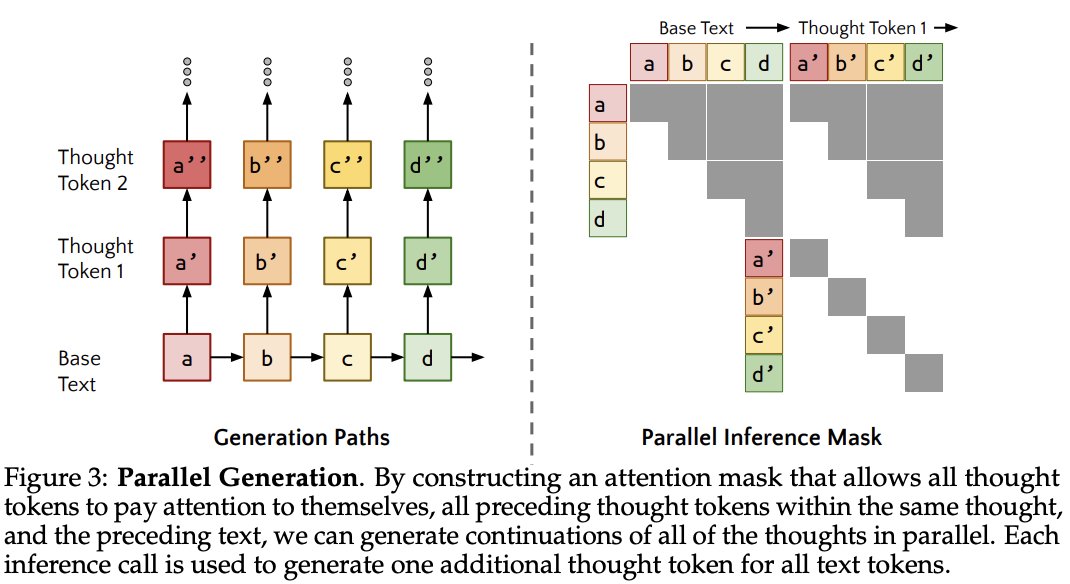 2/4) These rationales (thoughts) help the model predict tokens that are otherwise difficult to predict.
2/4) These rationales (thoughts) help the model predict tokens that are otherwise difficult to predict.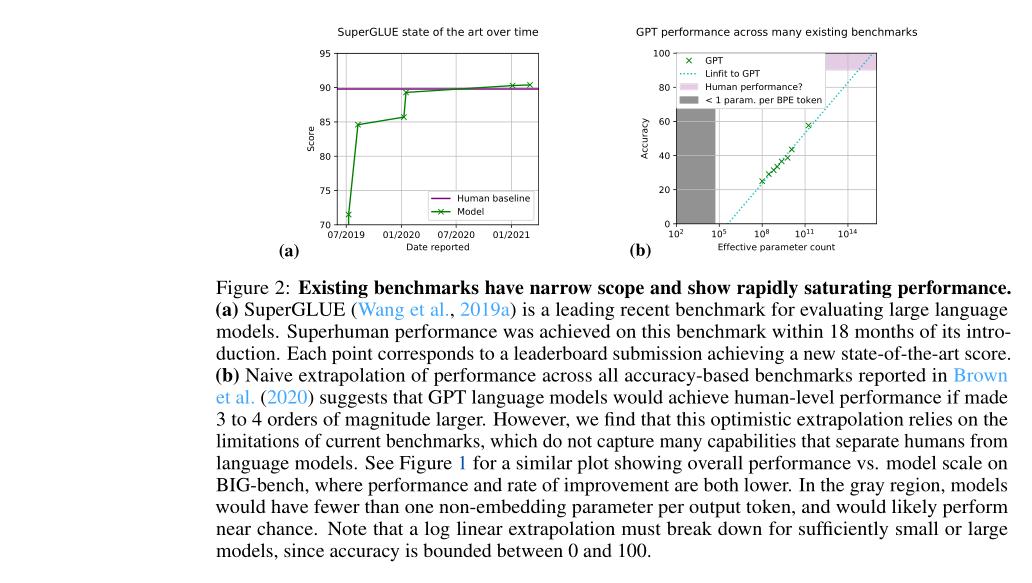
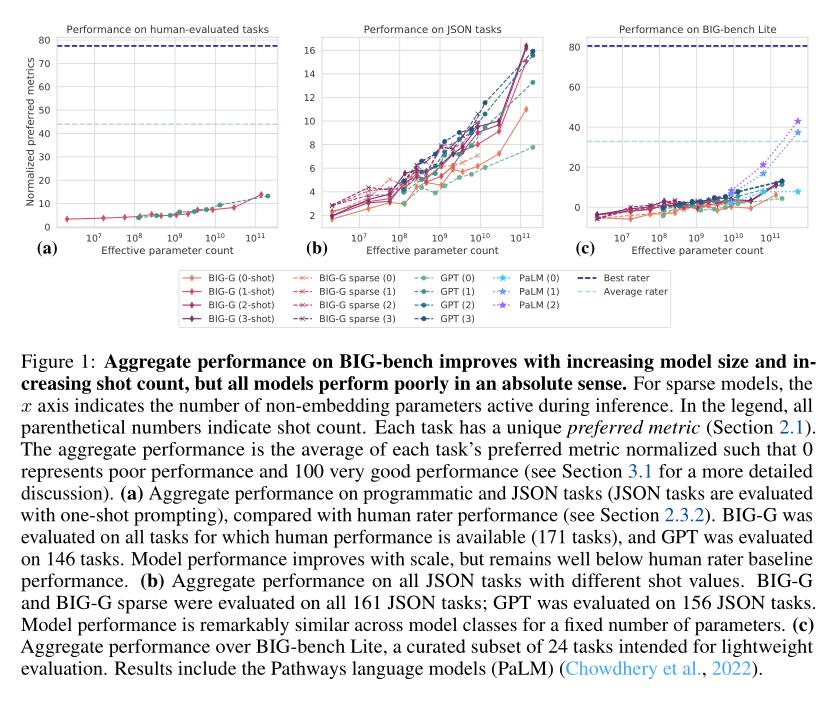
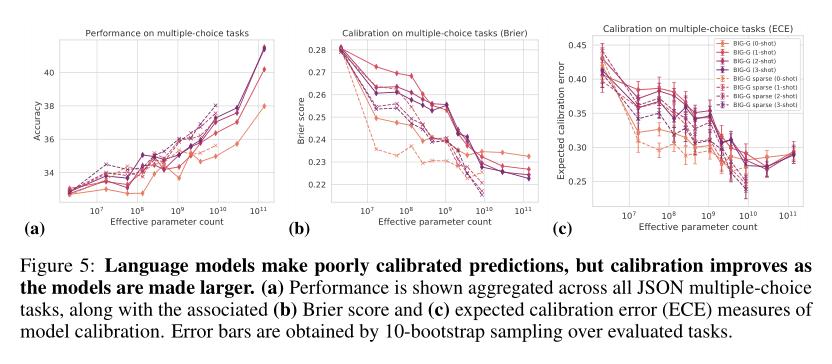
 (2/5) .. increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench)..
(2/5) .. increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench)..


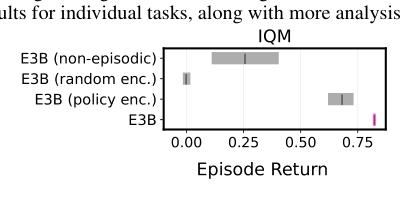
 (2/5) .. embedding is learned using an inverse dynamics model in order to capture controllable aspects of the environment.
(2/5) .. embedding is learned using an inverse dynamics model in order to capture controllable aspects of the environment.
 (2/4) .. behind significantly on lowresource or distant languages. ChatGPT does not perform as well as the commercial systems on biomedical abstracts or Reddit comments.
(2/4) .. behind significantly on lowresource or distant languages. ChatGPT does not perform as well as the commercial systems on biomedical abstracts or Reddit comments.



 (2/5) .. machine-learning system such as AlphaFold. Higher accuracy of the predictions translates to smaller confidence intervals, permitting more powerful inference.
(2/5) .. machine-learning system such as AlphaFold. Higher accuracy of the predictions translates to smaller confidence intervals, permitting more powerful inference.
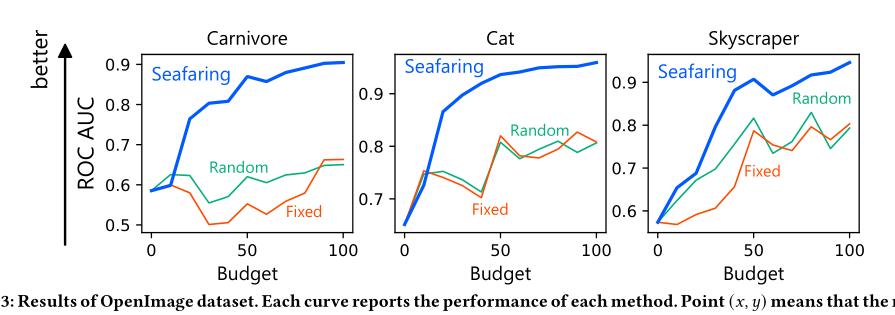
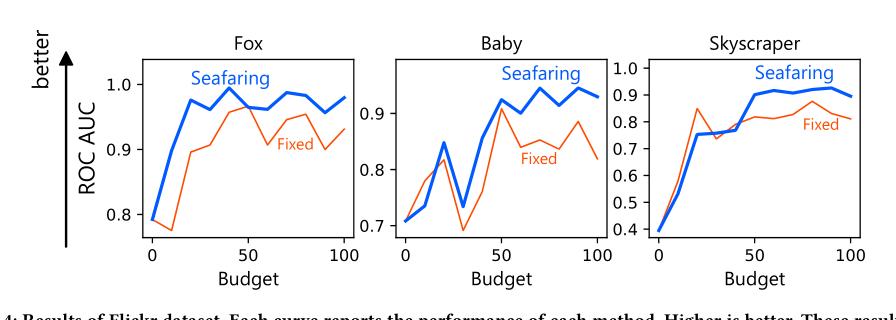
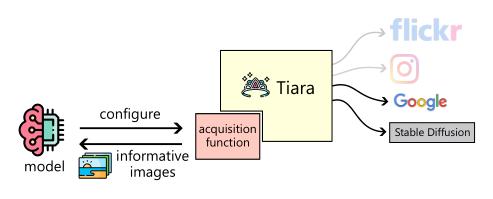
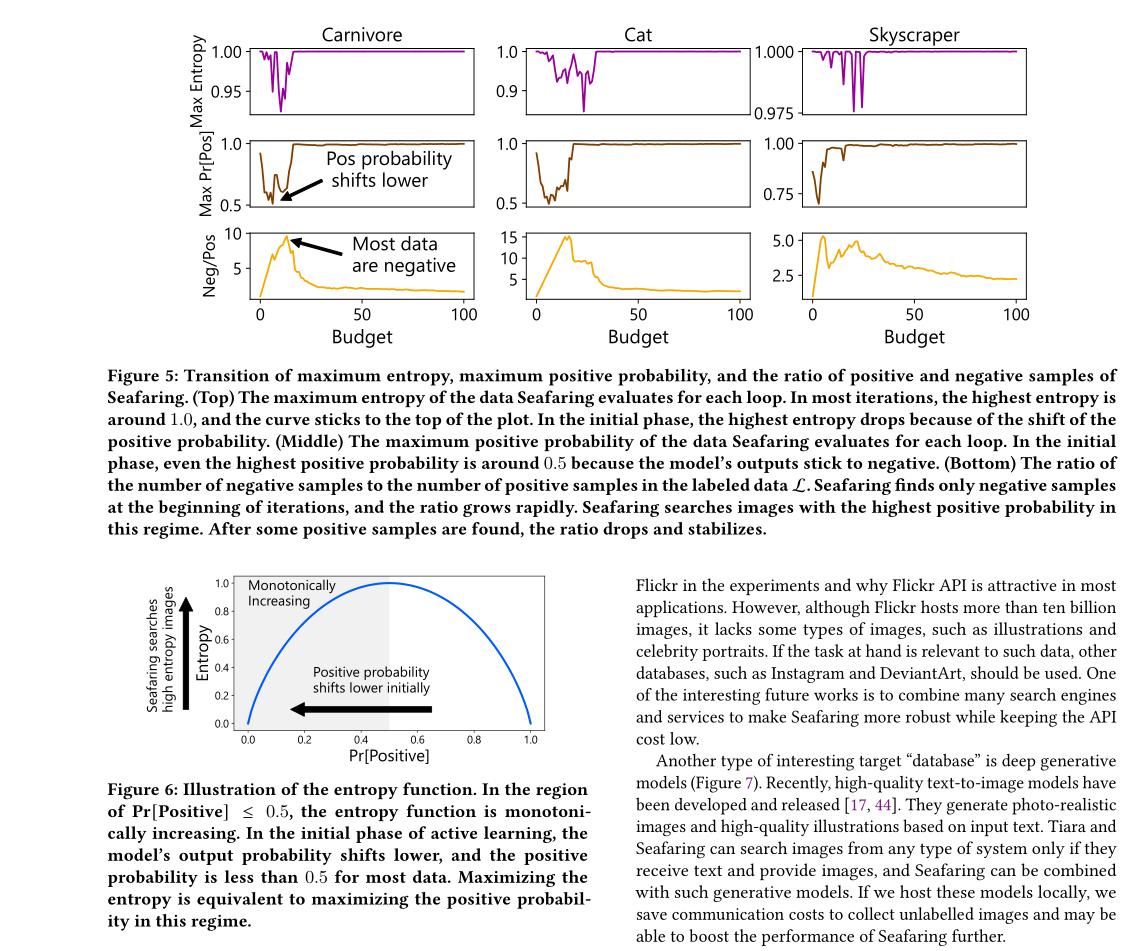 (2/4) .. to be labeled. We propose an efficient method, Seafaring, to retrieve informative data in terms of active learning from the Web.
(2/4) .. to be labeled. We propose an efficient method, Seafaring, to retrieve informative data in terms of active learning from the Web.

 (2/4) .. investigate the possibility of parallelizing boosting.
(2/4) .. investigate the possibility of parallelizing boosting.



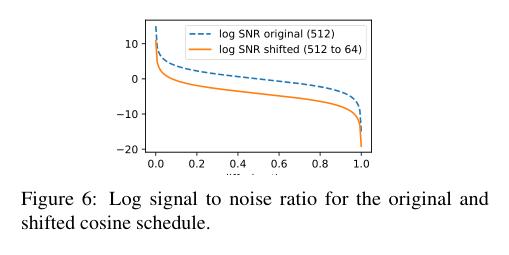 (2/4) .. denoising diffusion for high-resolution images while keeping the model as simple as possible. The four main findings are: 1) the noise schedule should be adjusted for high resolution images, 2..
(2/4) .. denoising diffusion for high-resolution images while keeping the model as simple as possible. The four main findings are: 1) the noise schedule should be adjusted for high resolution images, 2..


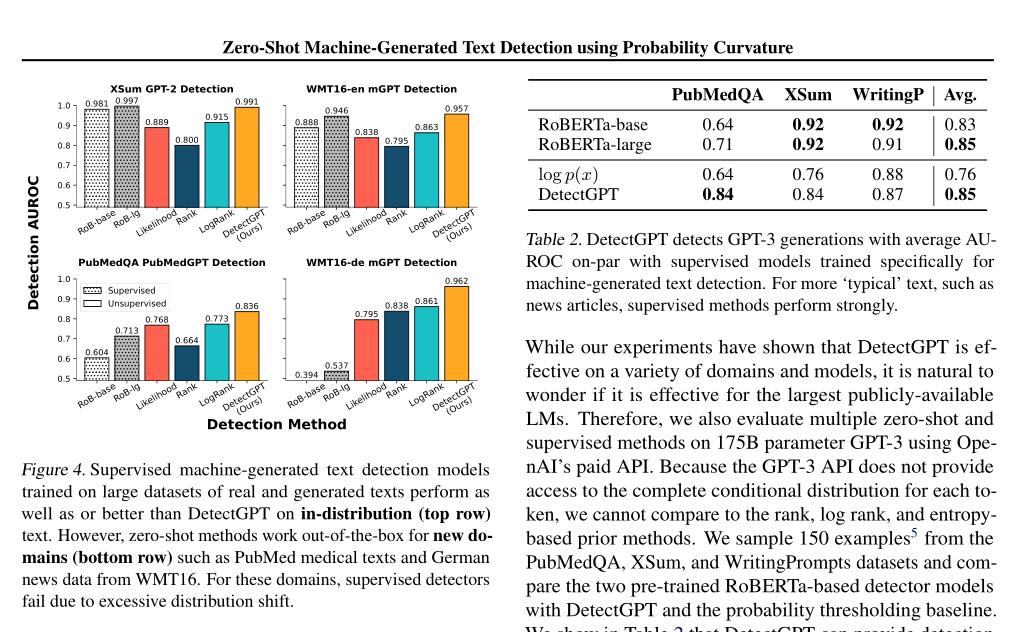
 (2/4) .. to detect whether a piece of text is machine-written. For example, students may use LLMs to complete written assignments, leaving instructors unable to accurately assess student learning.
(2/4) .. to detect whether a piece of text is machine-written. For example, students may use LLMs to complete written assignments, leaving instructors unable to accurately assess student learning.


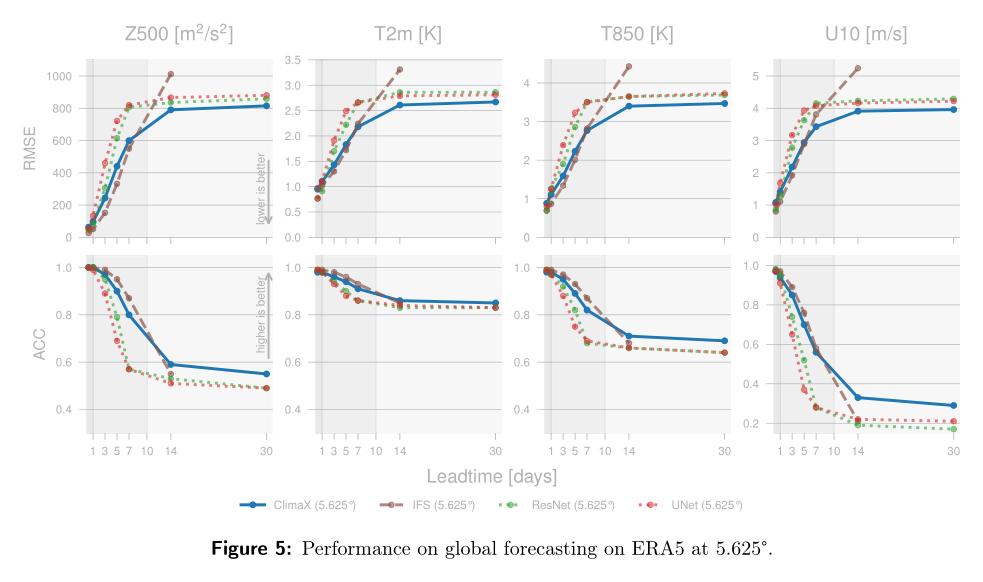
 (2/4) .. data-driven approaches based on machine learning instead aim to directly solve a downstream forecasting or projection task. These networks are trained using curated and homogeneous climate datasets.
(2/4) .. data-driven approaches based on machine learning instead aim to directly solve a downstream forecasting or projection task. These networks are trained using curated and homogeneous climate datasets.
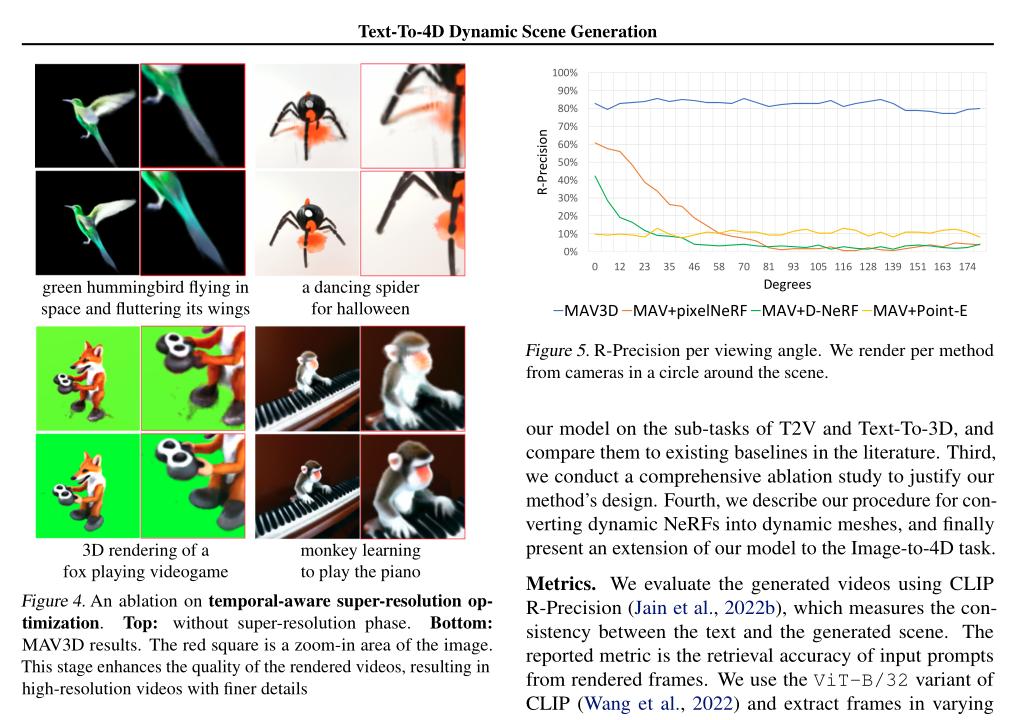


 (2/4) .. provided text can be viewed from any camera location and angle, and can be composited into any 3D environment.
(2/4) .. provided text can be viewed from any camera location and angle, and can be composited into any 3D environment.

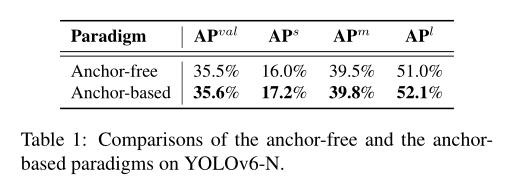
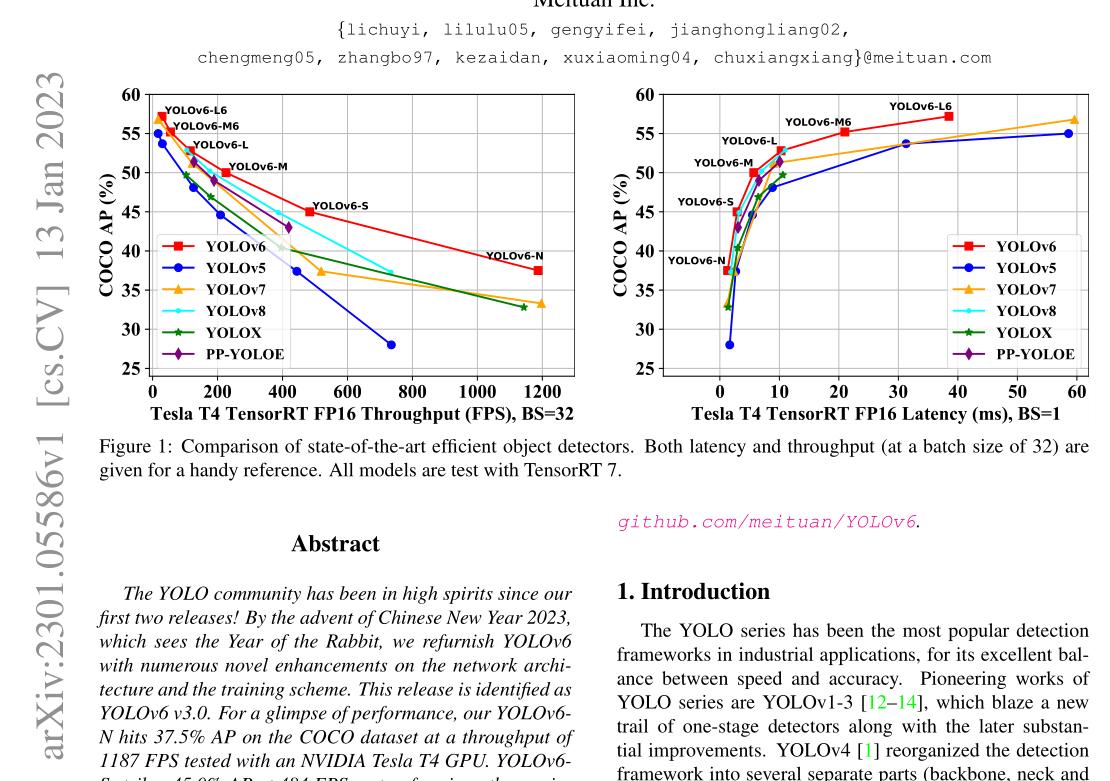
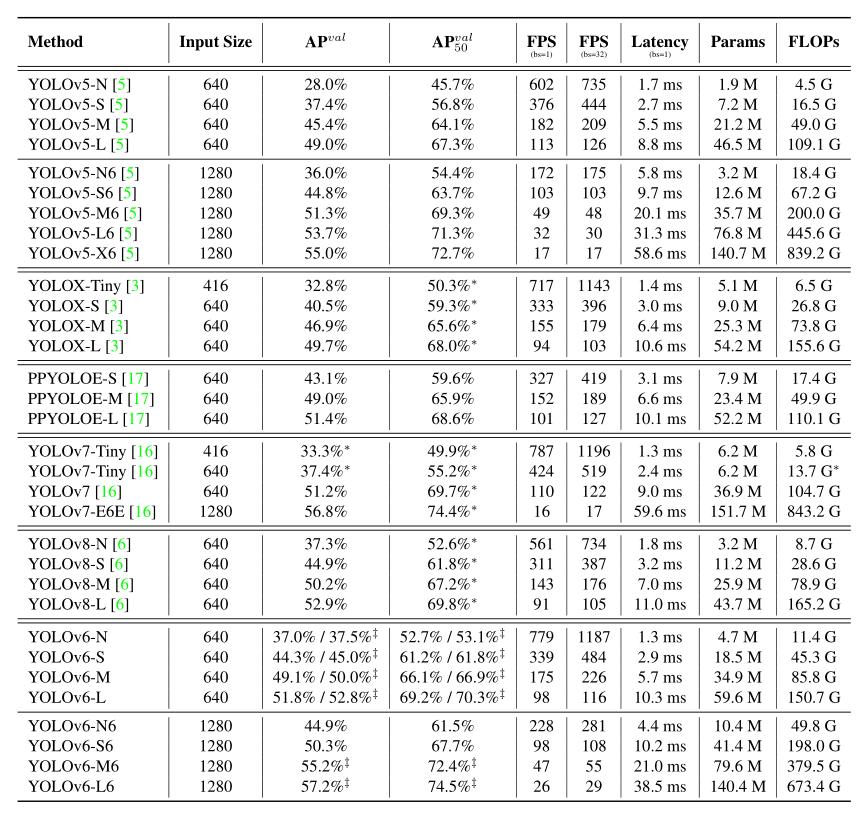 (2/4) .. includes novel enhancements on the network architecture and the training scheme.
(2/4) .. includes novel enhancements on the network architecture and the training scheme.



 (2/4) .. sophisticated pipelines between an LM and an RM. DSP can express high-level programs that bootstrap pipeline-aware demonstrations, search for relevant passages, and generate grounded predictions.
(2/4) .. sophisticated pipelines between an LM and an RM. DSP can express high-level programs that bootstrap pipeline-aware demonstrations, search for relevant passages, and generate grounded predictions.



 (2/4) .. represent the zeitgeist of the current era of massive change. These myths are rarely based on scientific facts but often on some evidence or argumentation.
(2/4) .. represent the zeitgeist of the current era of massive change. These myths are rarely based on scientific facts but often on some evidence or argumentation.



 (2/4) .. language models, are typically trained on massive corpora of code mined from unvetted public sources. As a result, these models are susceptible to data poisoning attacks.
(2/4) .. language models, are typically trained on massive corpora of code mined from unvetted public sources. As a result, these models are susceptible to data poisoning attacks.


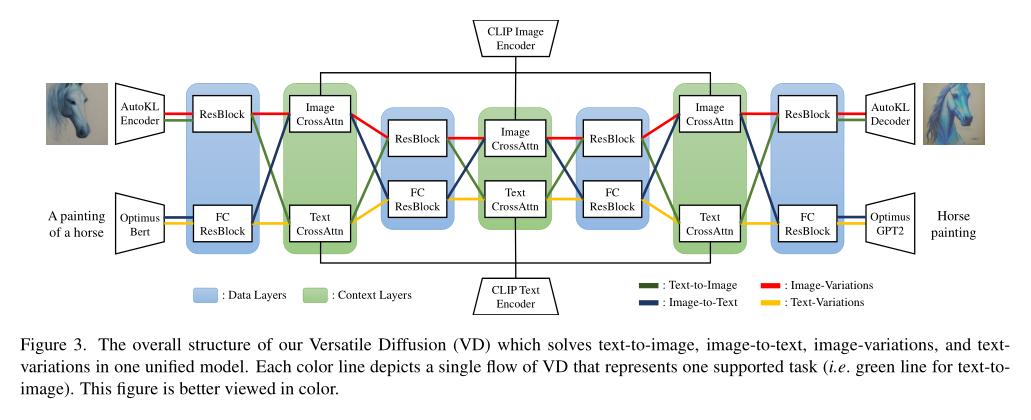
 (2/4) .. as DALL-E2, Imagen, and Stable Diffusion have attracted great interest in academia and industry. Recent new approaches focus on extensions and performance rather than capacity.
(2/4) .. as DALL-E2, Imagen, and Stable Diffusion have attracted great interest in academia and industry. Recent new approaches focus on extensions and performance rather than capacity.
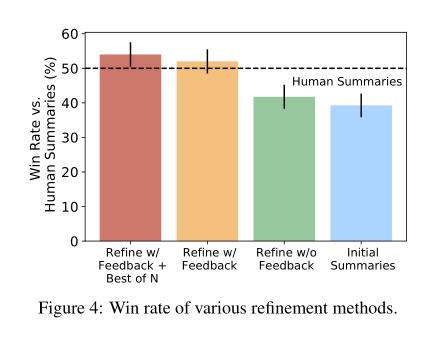
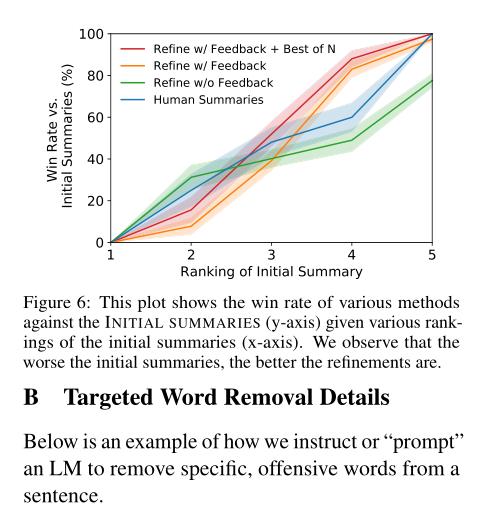
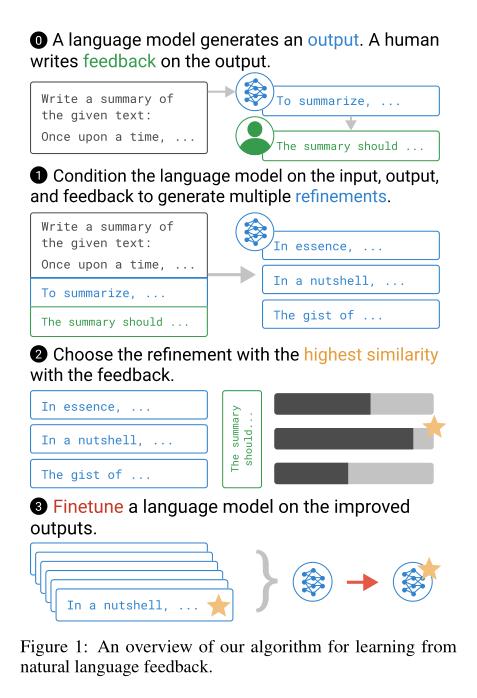
 (2/4) .. more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm.
(2/4) .. more information per human evaluation. We learn from language feedback on model outputs using a three-step learning algorithm.

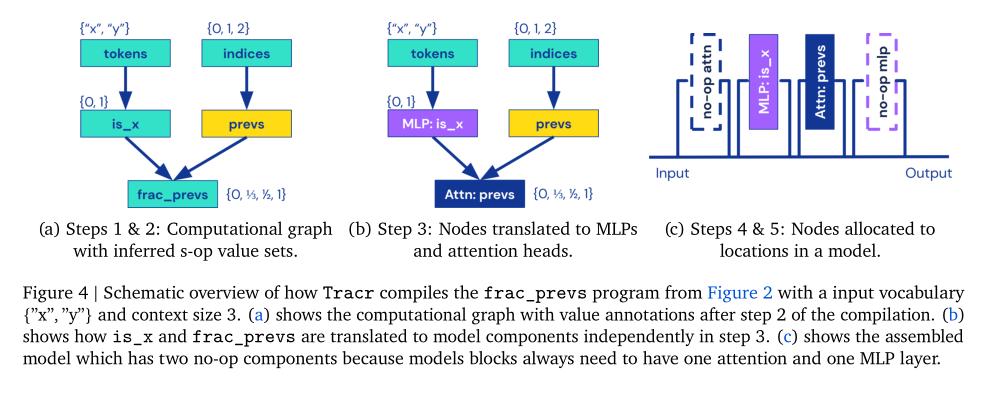
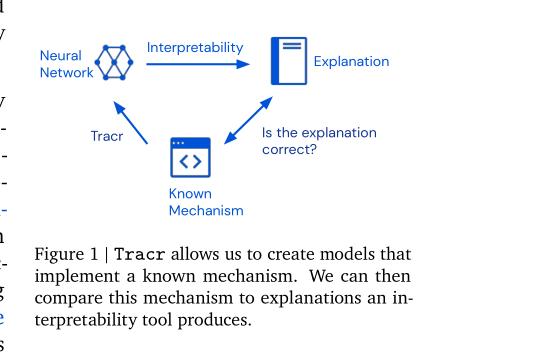
 (2/4) .. RASP, a domain-specific language, and translates it into weights for a standard, decoder-only, GPT-like architecture.
(2/4) .. RASP, a domain-specific language, and translates it into weights for a standard, decoder-only, GPT-like architecture.


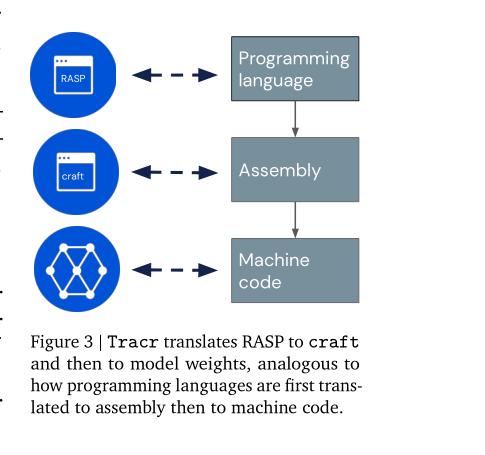
 2/9
2/9 2/5 They solve 200+ randomly chosen math problems. They seem to have tried different prompts until codex got the solution right. They show that the transformed prompts are quite similar to original problem.
2/5 They solve 200+ randomly chosen math problems. They seem to have tried different prompts until codex got the solution right. They show that the transformed prompts are quite similar to original problem. 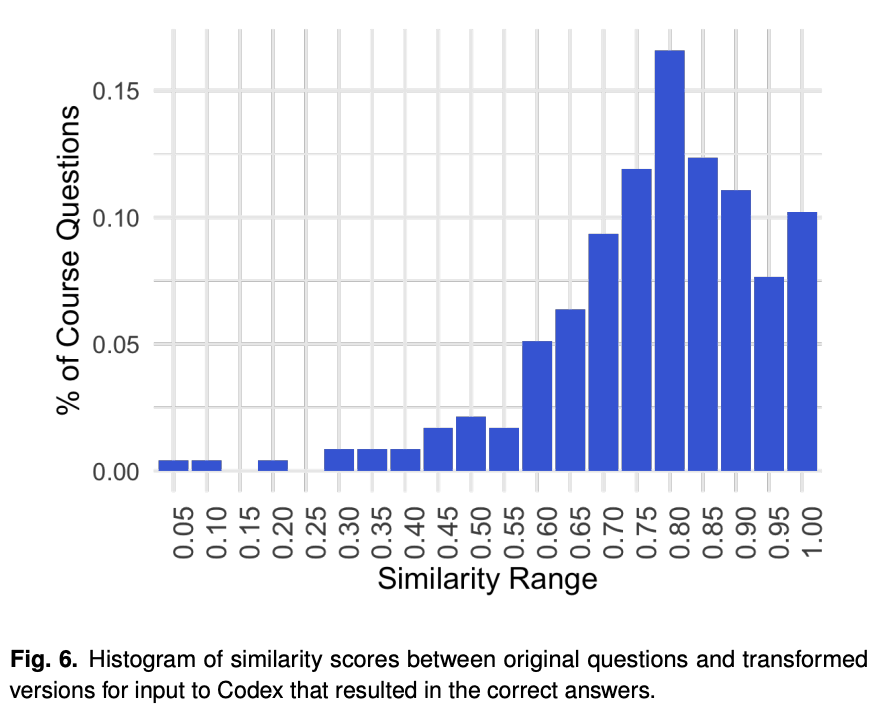
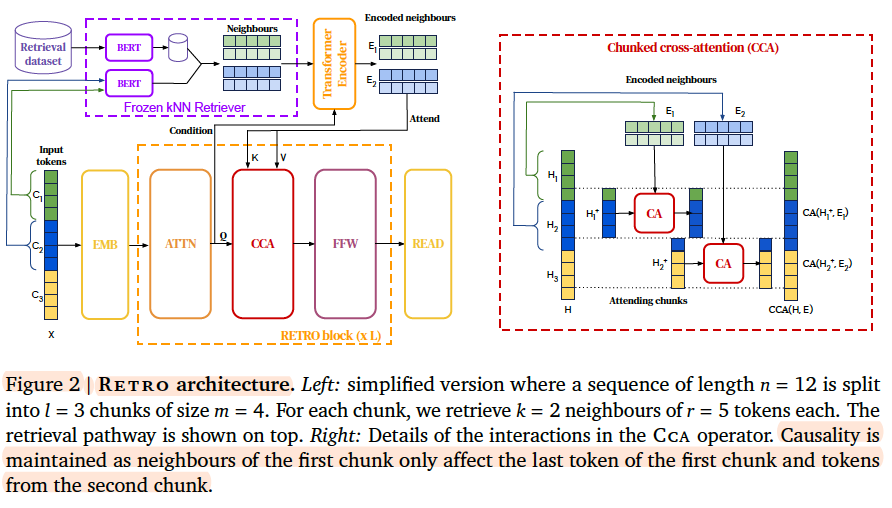
 2/ It retrieves chunks of similar text (kNN) based on a frozen BERT model from a massive dataset (~5T tokens). Then some layers of RETRO pay cross-attention to those chunks.
2/ It retrieves chunks of similar text (kNN) based on a frozen BERT model from a massive dataset (~5T tokens). Then some layers of RETRO pay cross-attention to those chunks.