
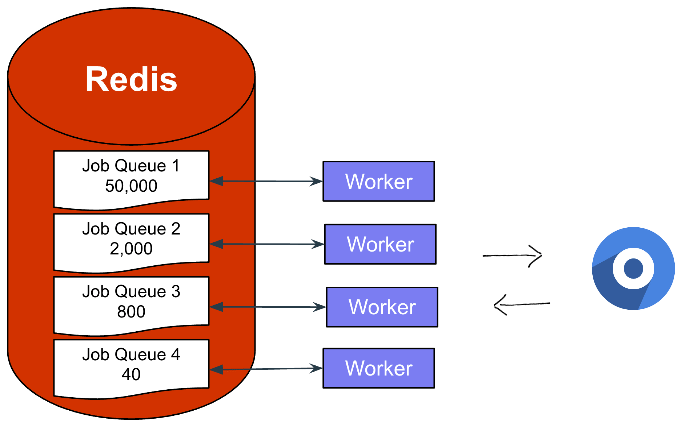
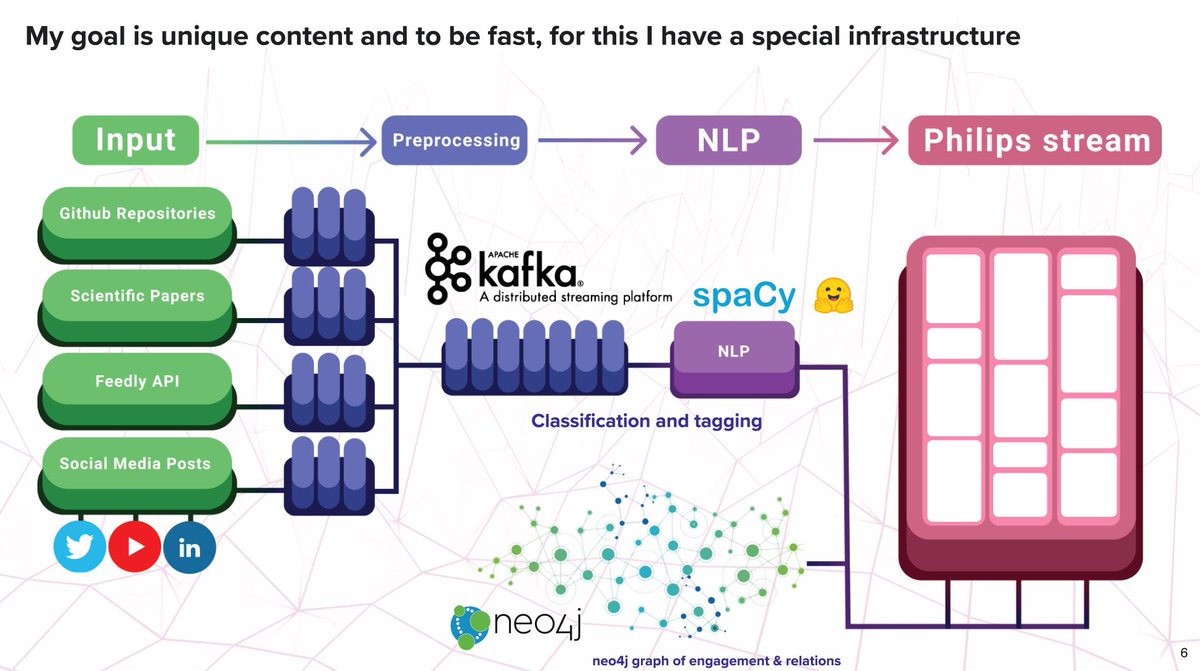
 I use Feedly for most content inputs because I can access the content through a single API endpoint and scraping is often pure pain.
I use Feedly for most content inputs because I can access the content through a single API endpoint and scraping is often pure pain.  They make use of pre-trained language models which they refine by fine-tuning them on specifically prepared corpora that we enriched with implicit information and by constraining them with relevant concepts and connecting commonsense knowledge paths.
They make use of pre-trained language models which they refine by fine-tuning them on specifically prepared corpora that we enriched with implicit information and by constraining them with relevant concepts and connecting commonsense knowledge paths.
 It is a hybrid face recognition framework wrapping state-of-the-art models: VGG-Face, Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace and Dlib
It is a hybrid face recognition framework wrapping state-of-the-art models: VGG-Face, Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace and Dlib github.com/KlausSchaefers…
github.com/KlausSchaefers…
 arxiv.org/abs/2106.02584
arxiv.org/abs/2106.02584
 Don't forget to spend some star love for the repository!
Don't forget to spend some star love for the repository!
 The model reaches state-of-the-art results for similarity with new speakers and speech quality with only 11 speakers in training.
The model reaches state-of-the-art results for similarity with new speakers and speech quality with only 11 speakers in training.


 The full MLOps life cycle
The full MLOps life cycle Where the big ones like OneNote, Google Keep and Evernote fail is that the brain does not work like an index, thoughts are linked and associatively this is where the next generation of note taking apps show their strength.
Where the big ones like OneNote, Google Keep and Evernote fail is that the brain does not work like an index, thoughts are linked and associatively this is where the next generation of note taking apps show their strength.

 github.com/elehman16/expo…
github.com/elehman16/expo… Almost all conditioned text generation models are validated on 2 factors:
Almost all conditioned text generation models are validated on 2 factors: