
Assistant Professor MIT @medialab @MITEECS @nlp_mit || Foundations of multisensory AI to enhance the human experience.
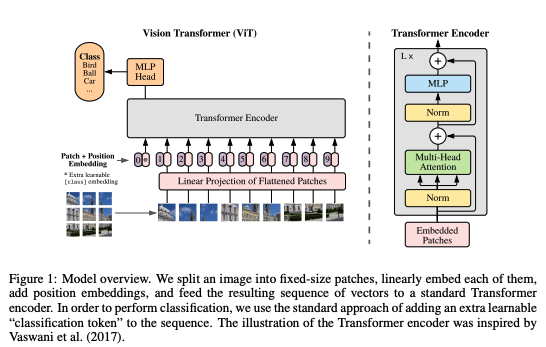
 @vickyqu0 @yuyinzhou_cs @mldcmu @StanfordDBDS @StanfordAILab We find that ViTs are more robust to distribution shift, reduce catastrophic forgetting over devices, accelerate convergence, and reach better models.
@vickyqu0 @yuyinzhou_cs @mldcmu @StanfordDBDS @StanfordAILab We find that ViTs are more robust to distribution shift, reduce catastrophic forgetting over devices, accelerate convergence, and reach better models.



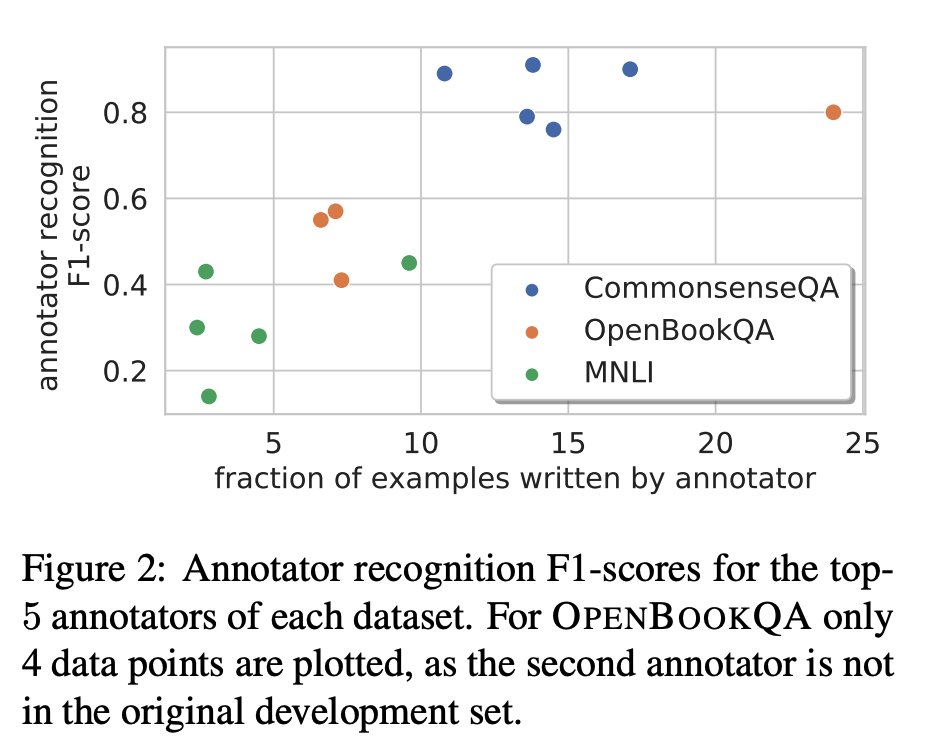
 @lpmorency @LTIatCMU @mldcmu Some suggested papers:
@lpmorency @LTIatCMU @mldcmu Some suggested papers:


 @mldcmu @LTIatCMU @lpmorency Some suggested papers:
@mldcmu @LTIatCMU @lpmorency Some suggested papers: