@nusingapore '24 | databases → RL infra → financial world models | 12++ solo hack wins (CalHacks,HTN etc.) | angel investor | i like making fast things
 Benchmarked on rtk-ai/rtk (329 files):
Benchmarked on rtk-ai/rtk (329 files):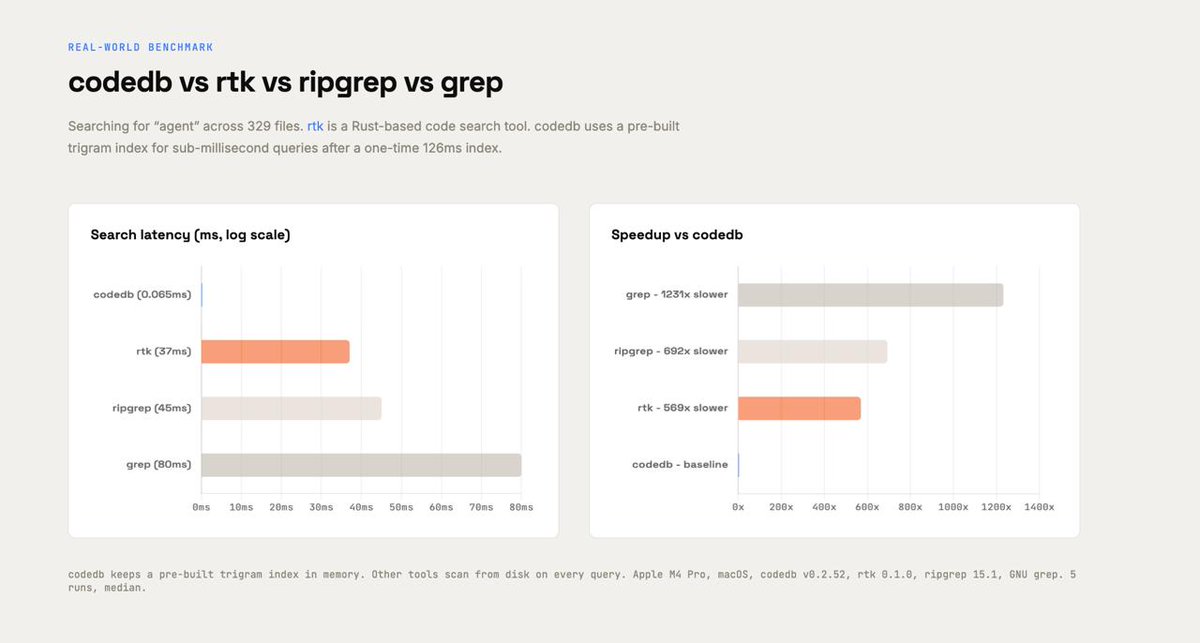
 Every time an AI agent runs grep or find on your codebase, it pays the full cost.
Every time an AI agent runs grep or find on your codebase, it pays the full cost.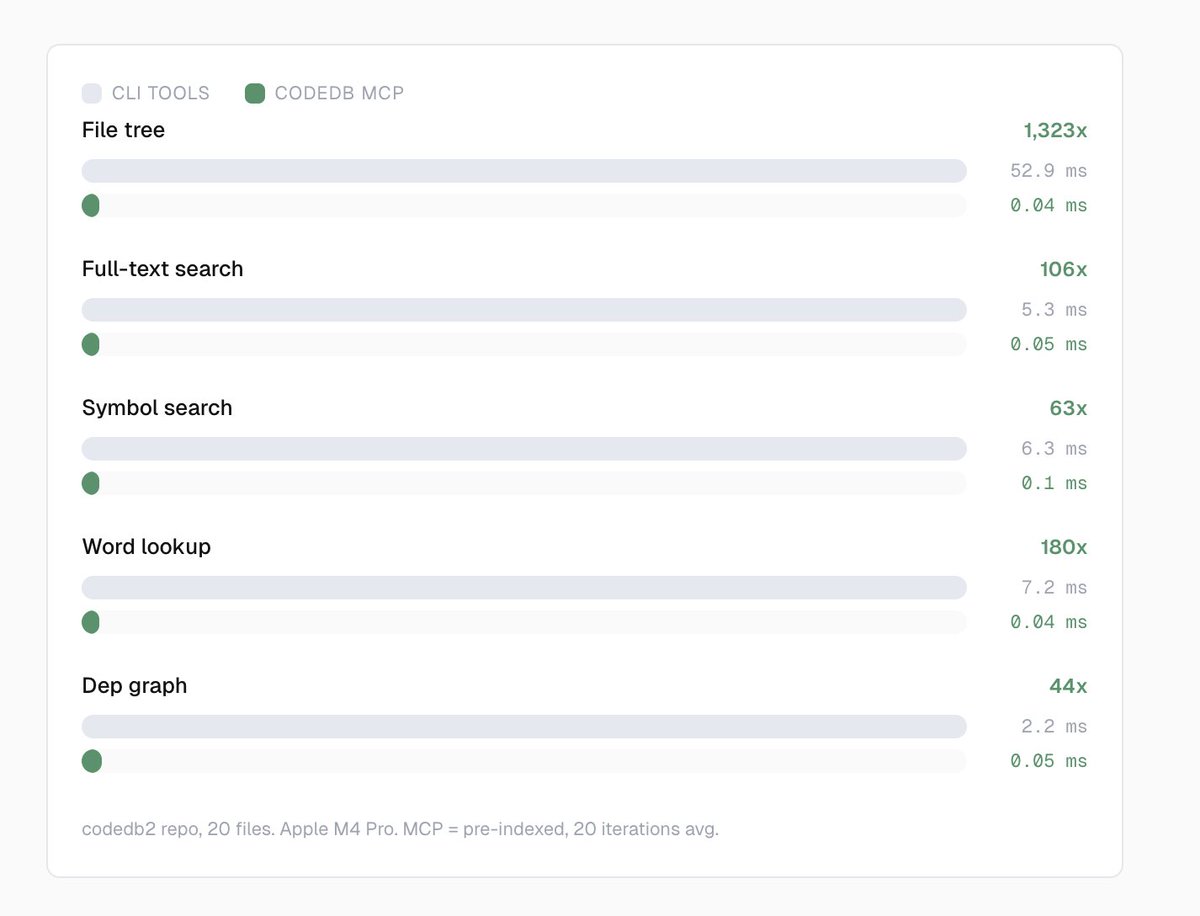
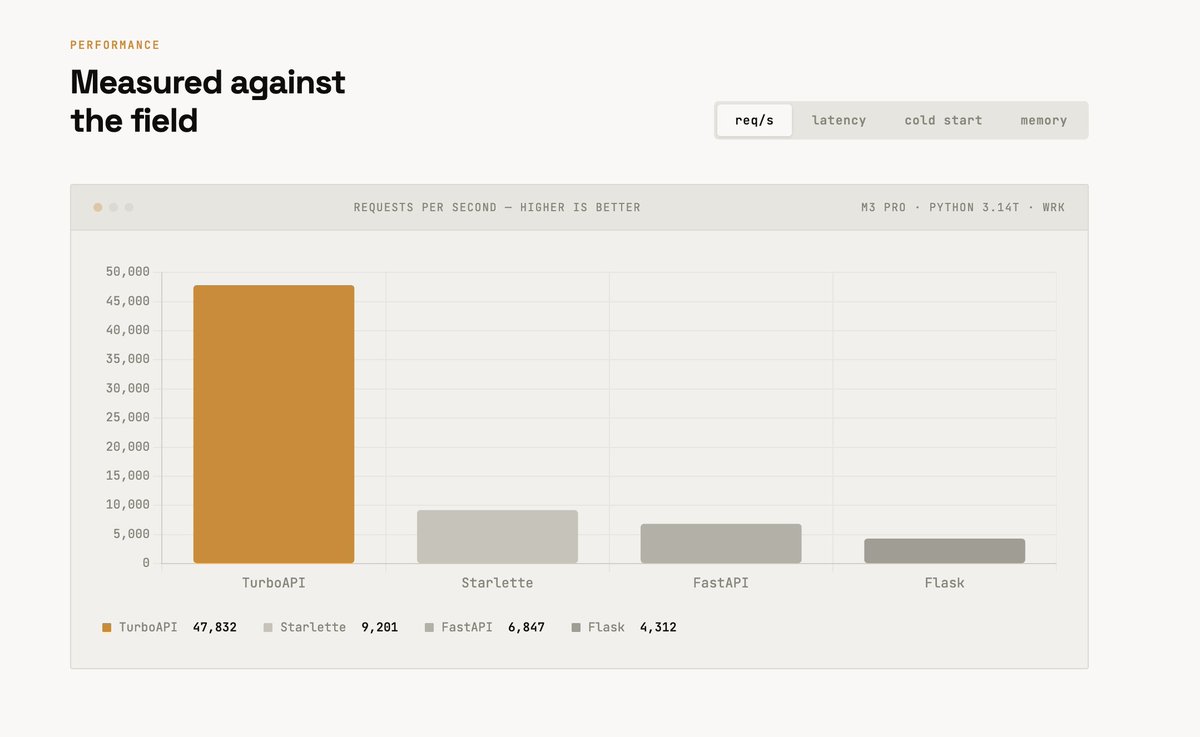
 FastAPI is beautiful to write. But every single request goes:
FastAPI is beautiful to write. But every single request goes: