
PhD @Berkeley_AI, visiting researcher @AIatMeta. Interactive language agents 🤖 💬
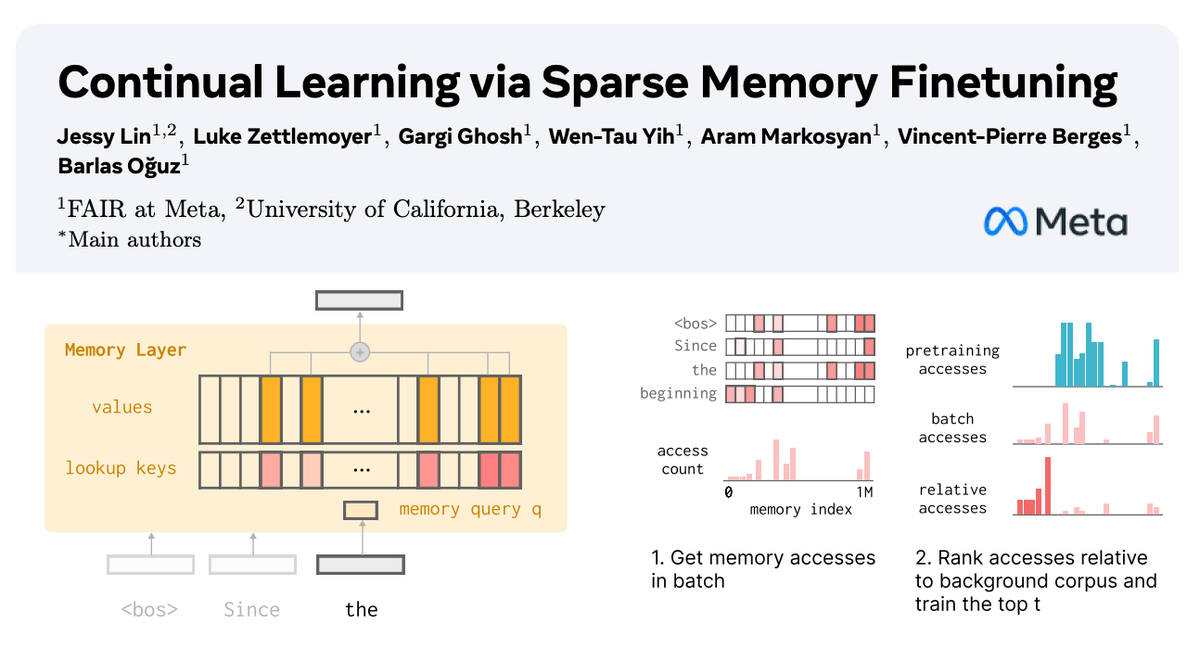 To learn something new, we shouldn’t need to finetune all the parameters of a large model.
To learn something new, we shouldn’t need to finetune all the parameters of a large model. Currently, we train models by doing a single pass over the data.
Currently, we train models by doing a single pass over the data.
 @dan_fried @ancadianadragan We’d like AI agents that not only follow our instructions (“book this flight”), but learn to generalize to what to do in new contexts (know what flights I prefer from our past interactions and book on my behalf) — i.e., learn *rewards* from language. [2/n]
@dan_fried @ancadianadragan We’d like AI agents that not only follow our instructions (“book this flight”), but learn to generalize to what to do in new contexts (know what flights I prefer from our past interactions and book on my behalf) — i.e., learn *rewards* from language. [2/n]