

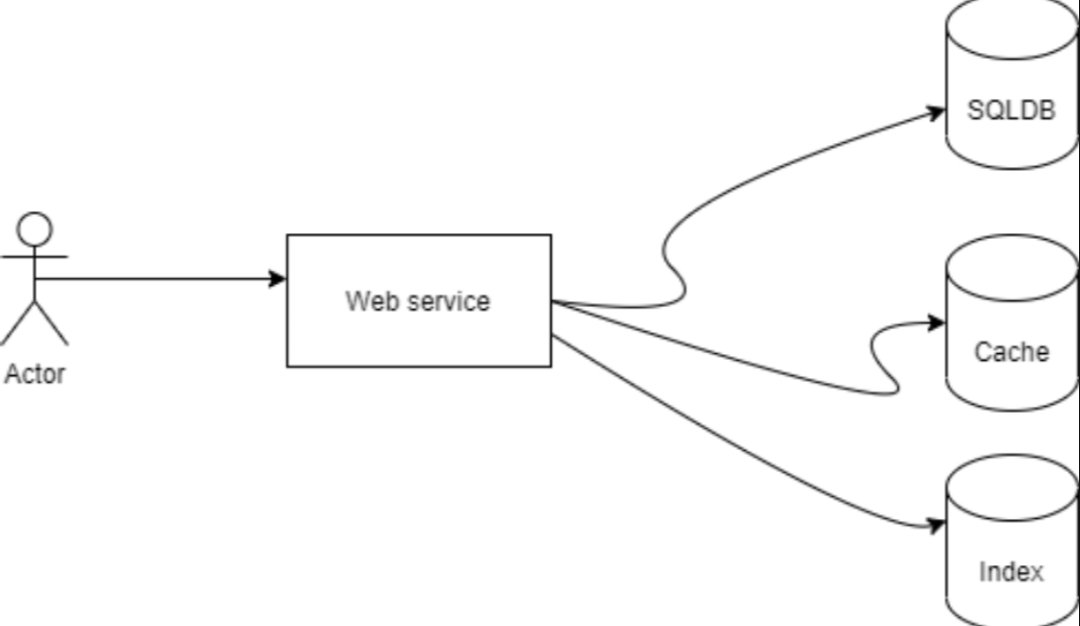
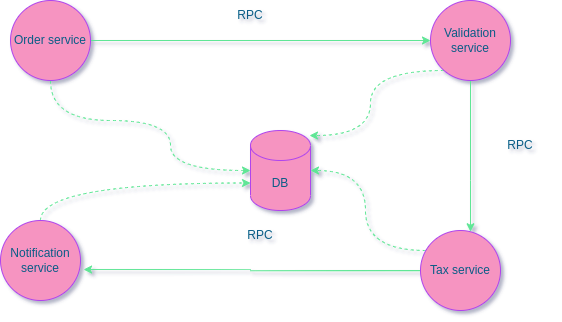
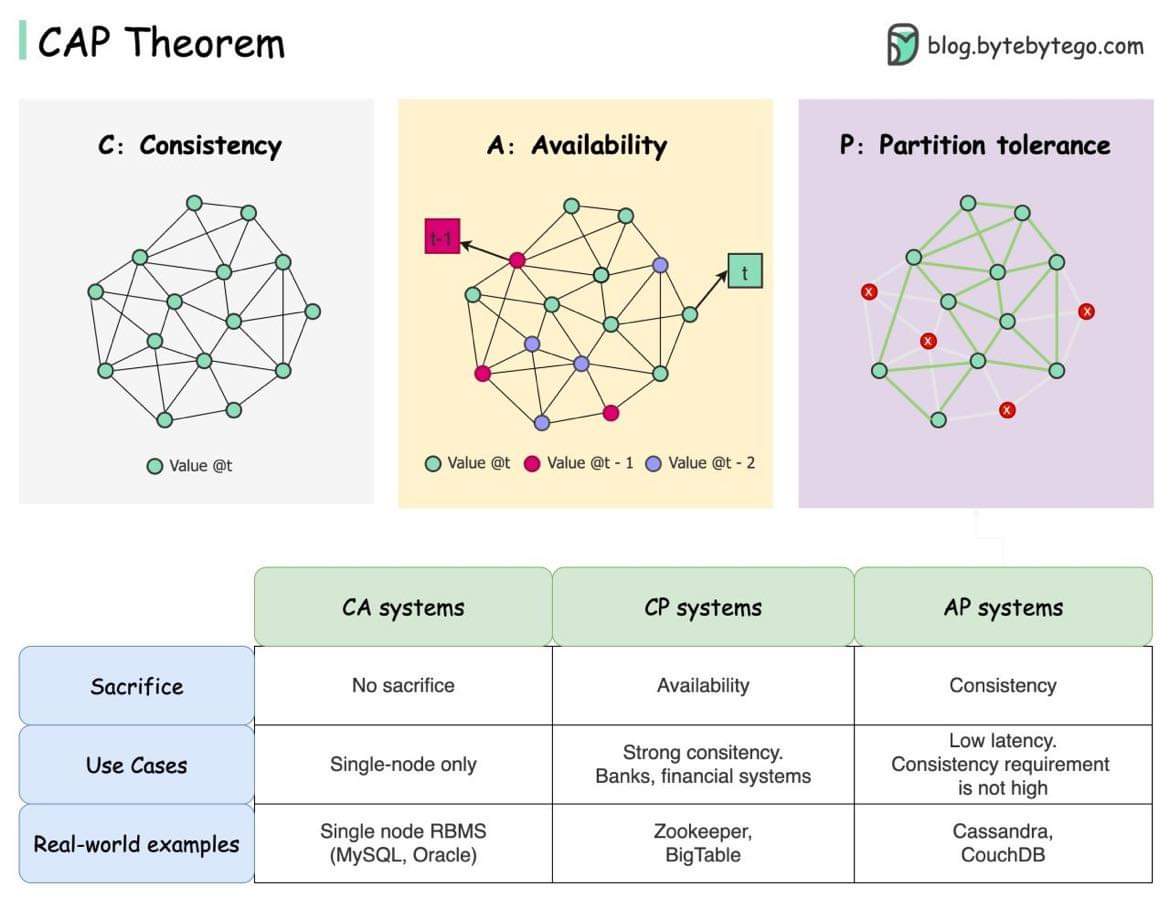
 C in CAP mean linearlizability that means operation B started after operation A successfully completed, then operation B must see the the system in the same state as it was on completion of operation A, or a newer state
C in CAP mean linearlizability that means operation B started after operation A successfully completed, then operation B must see the the system in the same state as it was on completion of operation A, or a newer state
 واتكلم عن أعمدة ال Observability ال tracing , event logging , Metrics وازاى نعمل الكلام دا فى Kubernetes فى البداية بشكل بدائى مبسط زى انك تطلع ال top nodes أو ال top pods وتراقب استهلاك ال resources بعد كدا اتكلم عن أدوات ال Observability إلى منها Prometheus وال time series
واتكلم عن أعمدة ال Observability ال tracing , event logging , Metrics وازاى نعمل الكلام دا فى Kubernetes فى البداية بشكل بدائى مبسط زى انك تطلع ال top nodes أو ال top pods وتراقب استهلاك ال resources بعد كدا اتكلم عن أدوات ال Observability إلى منها Prometheus وال time series
 أو انك مثلا تستخدم env variable تحط فيه معلومات زى connection string أو private key الخ فوضح الكتاب استخدام Kubernetes secrets إلى تقدر تعمل لها reference فى ال env أو config map الخ لكن طبعا من خلال ال gitops الكلام دا not recommended عشان lack of security
أو انك مثلا تستخدم env variable تحط فيه معلومات زى connection string أو private key الخ فوضح الكتاب استخدام Kubernetes secrets إلى تقدر تعمل لها reference فى ال env أو config map الخ لكن طبعا من خلال ال gitops الكلام دا not recommended عشان lack of security
 مختلفة هتكلم عنها مبدئيا الكتاب مكون من 3 اجزاء على 11 فصل الجزء الأول مكون من فصلين
مختلفة هتكلم عنها مبدئيا الكتاب مكون من 3 اجزاء على 11 فصل الجزء الأول مكون من فصلين