
Comms @MIRIBerkeley. RT = increased vague psychological association between myself and the tweet.
 Jon Wolfsthal, former Special Assistant to the President for National Security Affairs
Jon Wolfsthal, former Special Assistant to the President for National Security Affairs
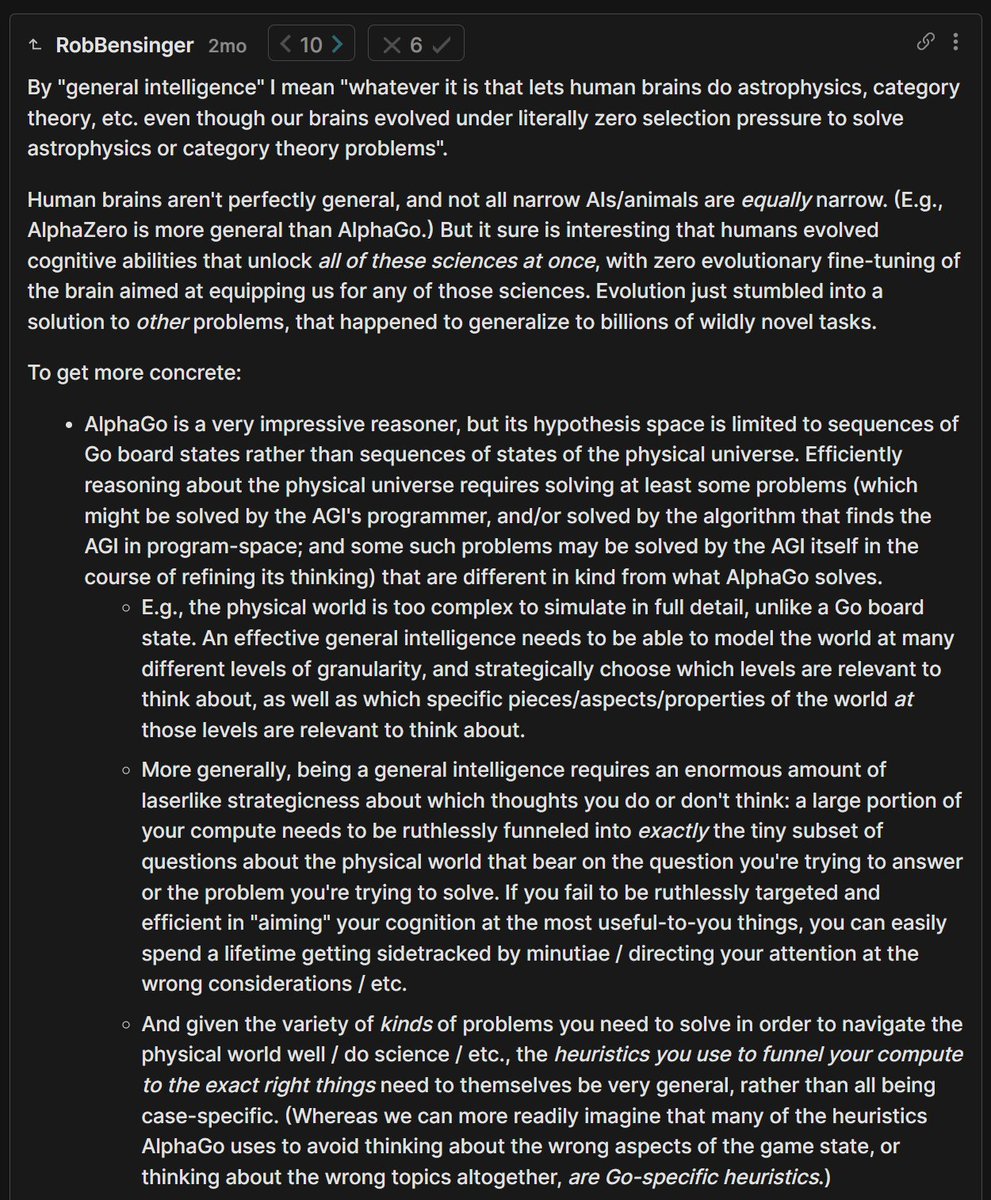
 Like, yes, point taken, this feels like a bizarre situation to be in. And I agree with lesswrong.com/posts/uFNgRumr… that there are sane ways to slow progress to some degree, which are worth pursuing alongside alignment work and other ideas to cause the long-term future to go well.
Like, yes, point taken, this feels like a bizarre situation to be in. And I agree with lesswrong.com/posts/uFNgRumr… that there are sane ways to slow progress to some degree, which are worth pursuing alongside alignment work and other ideas to cause the long-term future to go well.

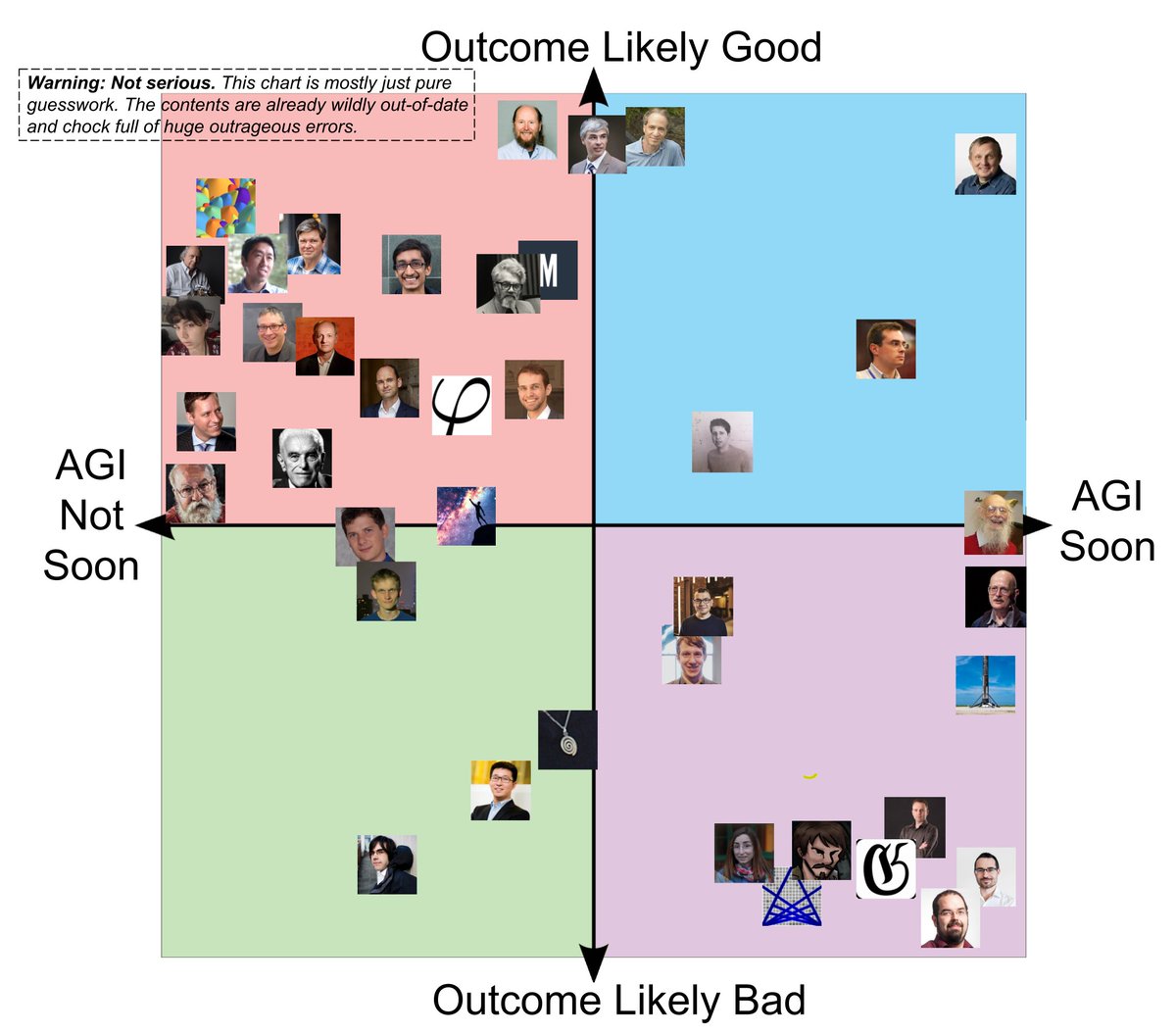 I did a tiny bit of Googling, but a lot of the comparisons are very subjective, or based on guesswork, or based on info that's likely super out-of-date. Treat this like an untrustworthy rumor you heard someone casually toss out at a party, not like a distillation of knowledge.
I did a tiny bit of Googling, but a lot of the comparisons are very subjective, or based on guesswork, or based on info that's likely super out-of-date. Treat this like an untrustworthy rumor you heard someone casually toss out at a party, not like a distillation of knowledge.