
Research scientist @OpenAI. Ex postdoc at Stanford working on systematic generalization and algorithmic reasoning. Ex IDSIA PhD, Ex @DeepMind intern.
 For inputs involving many steps, the operands for each step remain important until an identical depth. This indicates that the model is *not* breaking down the computation, solving subproblems, and composing their results together. 2/6
For inputs involving many steps, the operands for each step remain important until an identical depth. This indicates that the model is *not* breaking down the computation, solving subproblems, and composing their results together. 2/6 
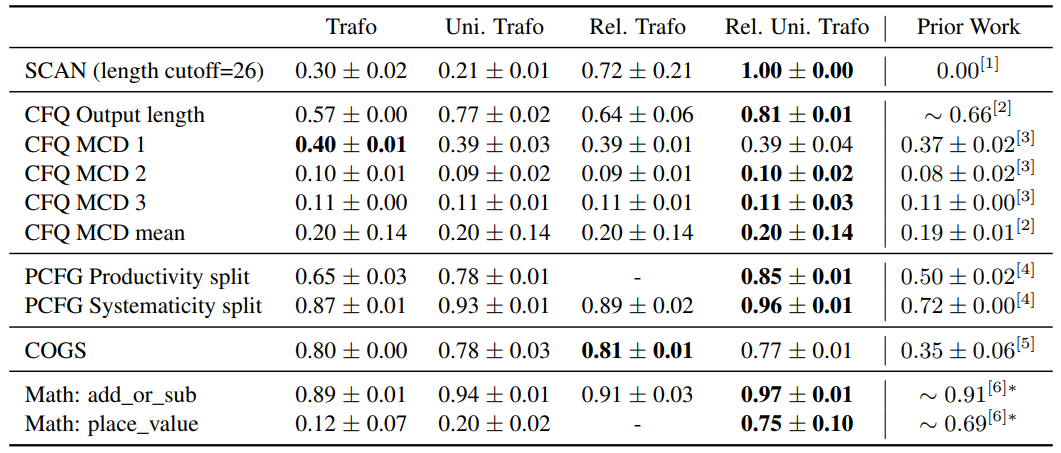 We improve the systematic generalization of Transformers on SCAN (0 -> 100% with length cutoff=26), CFQ (66 -> 81% on output length split), PCFG (50 -> 85% on productivity split, 72 -> 96% on systematicity split), COGS (35 -> 81%), and Mathematics dataset.
We improve the systematic generalization of Transformers on SCAN (0 -> 100% with length cutoff=26), CFQ (66 -> 81% on output length split), PCFG (50 -> 85% on productivity split, 72 -> 96% on systematicity split), COGS (35 -> 81%), and Mathematics dataset.