Do you work with single cell RNA-Seq data (or any count data with large numbers of zeros)? You may be interested in our preprint now available on @biorxiv_genomic : biorxiv.org/content/10.110… in collaboration with @rafalab@stephaniehicks and Martin Aryee
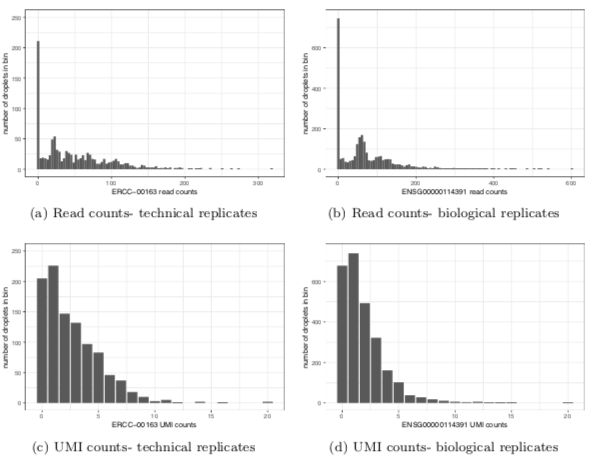
I will try to describe here the main points. 1. Sampling distribution of unique molecular identifier counts (UMI) is NOT zero inflated (see also nxn.se/valent/2017/11… from @vallens ). Apparent zero inflation in read counts is due to PCR duplicates.