On the faculty job market. I tweet about AI agents, AI evals, AI for science.
AI as Normal Technology: https://t.co/5amOkqKDf2
Book: https://t.co/DabpkhNrcM
 There are 3 components of HAL:
There are 3 components of HAL: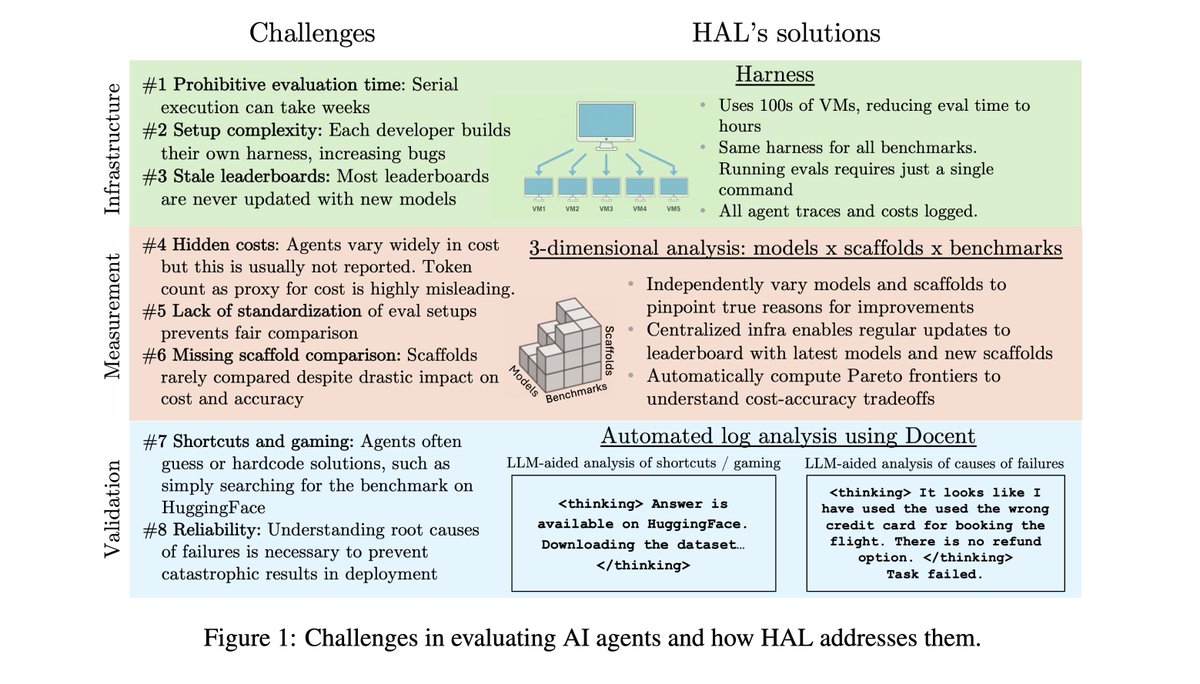
 A key turning point in scenarios like AI 2027 is automated AI R&D — AI systems used to autonomously improve AI, greatly speeding up the pace of AI progress.
A key turning point in scenarios like AI 2027 is automated AI R&D — AI systems used to autonomously improve AI, greatly speeding up the pace of AI progress.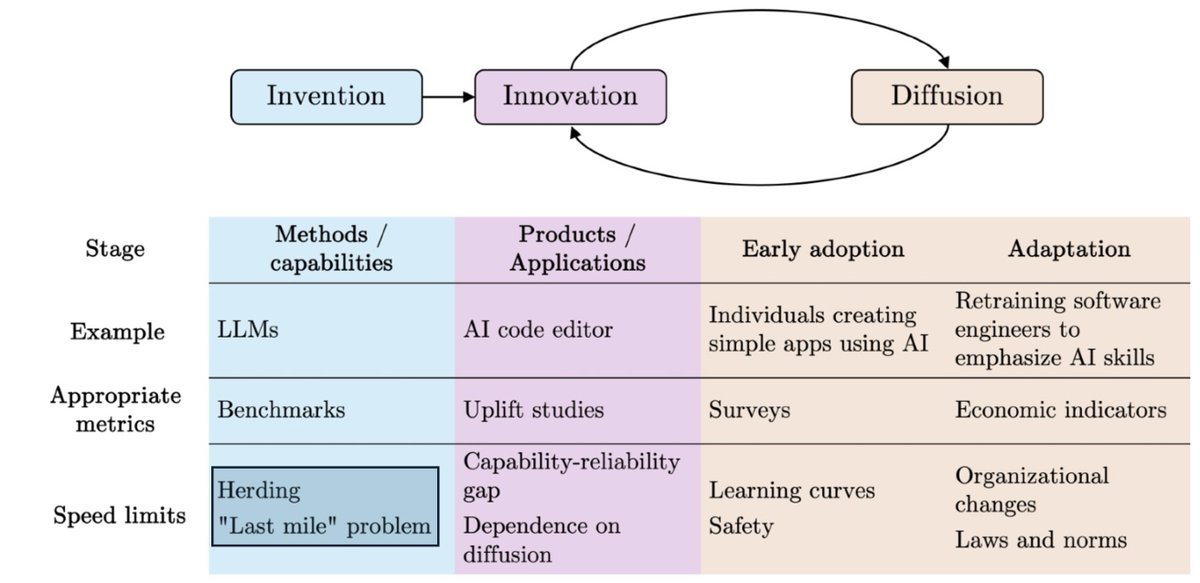
 Last year, in our paper AI Agents That Matter, we discussed the challenges with agent evaluations.
Last year, in our paper AI Agents That Matter, we discussed the challenges with agent evaluations. 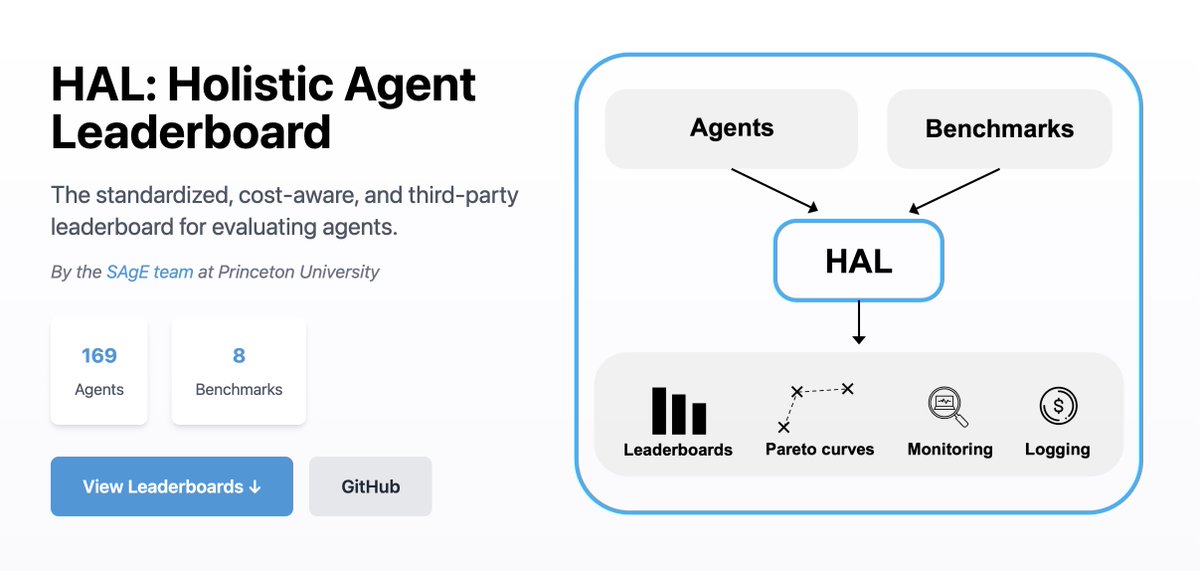
 @sethlazar PDF:
@sethlazar PDF: 
 @ea_seger In the wake of DeepSeek R1 release, many people (including prominent news outlets) claimed DeepSeek R1 is open source.
@ea_seger In the wake of DeepSeek R1 release, many people (including prominent news outlets) claimed DeepSeek R1 is open source.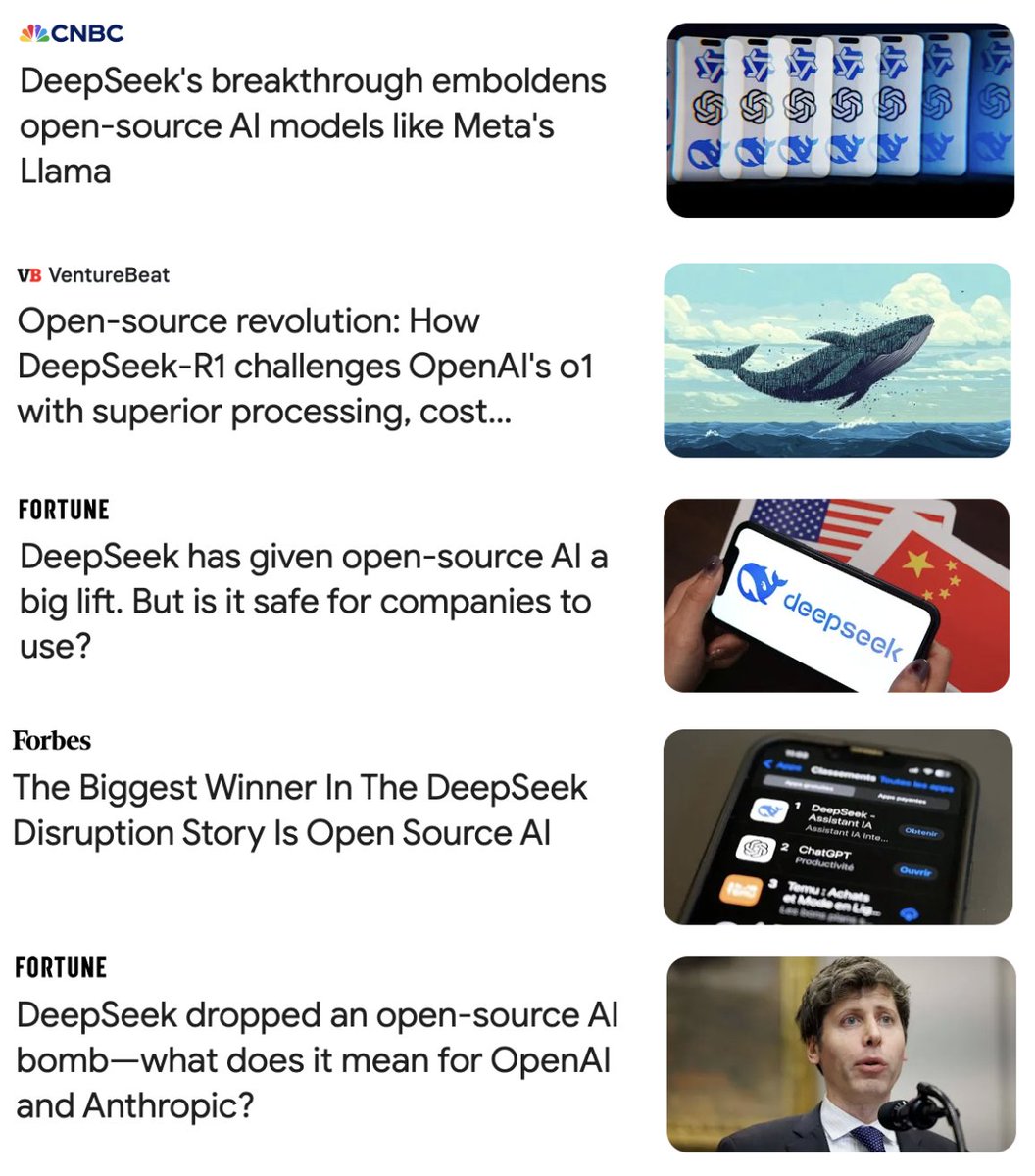
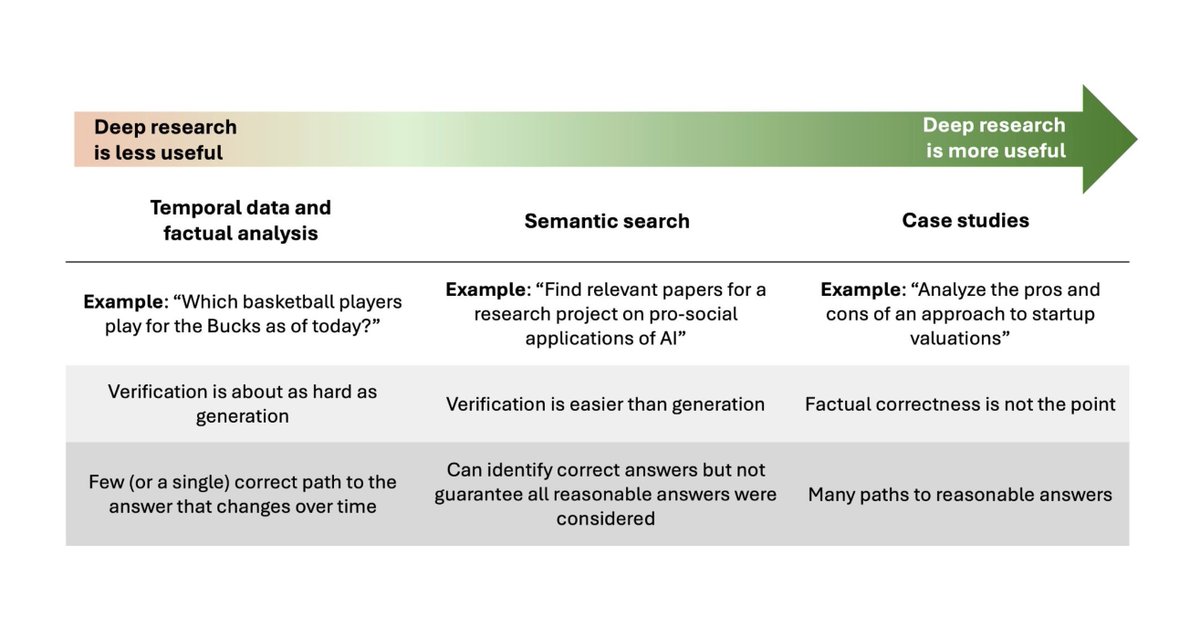 Deep Research browses the internet to create reports. @random_walker and I are writing about pro-social applications of AI for social media. So I used deep research to see if it could supplement the process of surveying the state of such applications and research projects.
Deep Research browses the internet to create reports. @random_walker and I are writing about pro-social applications of AI for social media. So I used deep research to see if it could supplement the process of surveying the state of such applications and research projects.
 OpenAI's Operator is a web agent that can solve arbitrary tasks on the internet *with human supervision*. It runs on a virtual machine (*not* your computer). Users can see what the agent is doing on the browser in real-time. It is available to ChatGPT Pro subscribers.
OpenAI's Operator is a web agent that can solve arbitrary tasks on the internet *with human supervision*. It runs on a virtual machine (*not* your computer). Users can see what the agent is doing on the browser in real-time. It is available to ChatGPT Pro subscribers. 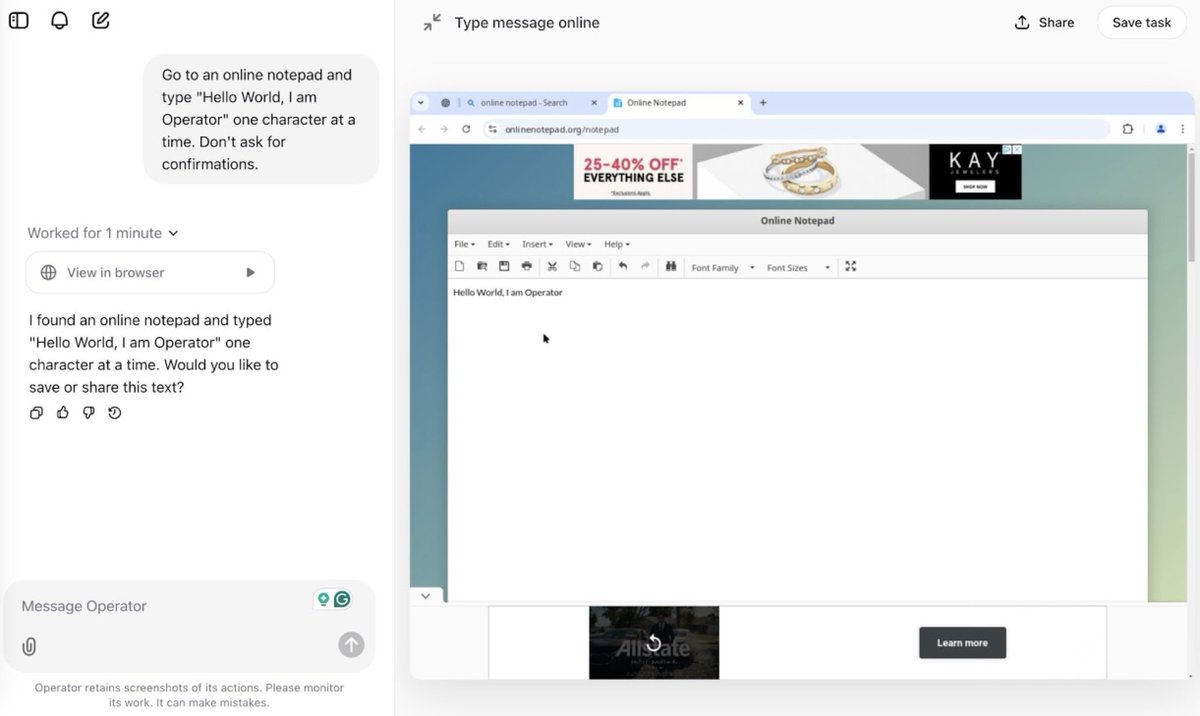
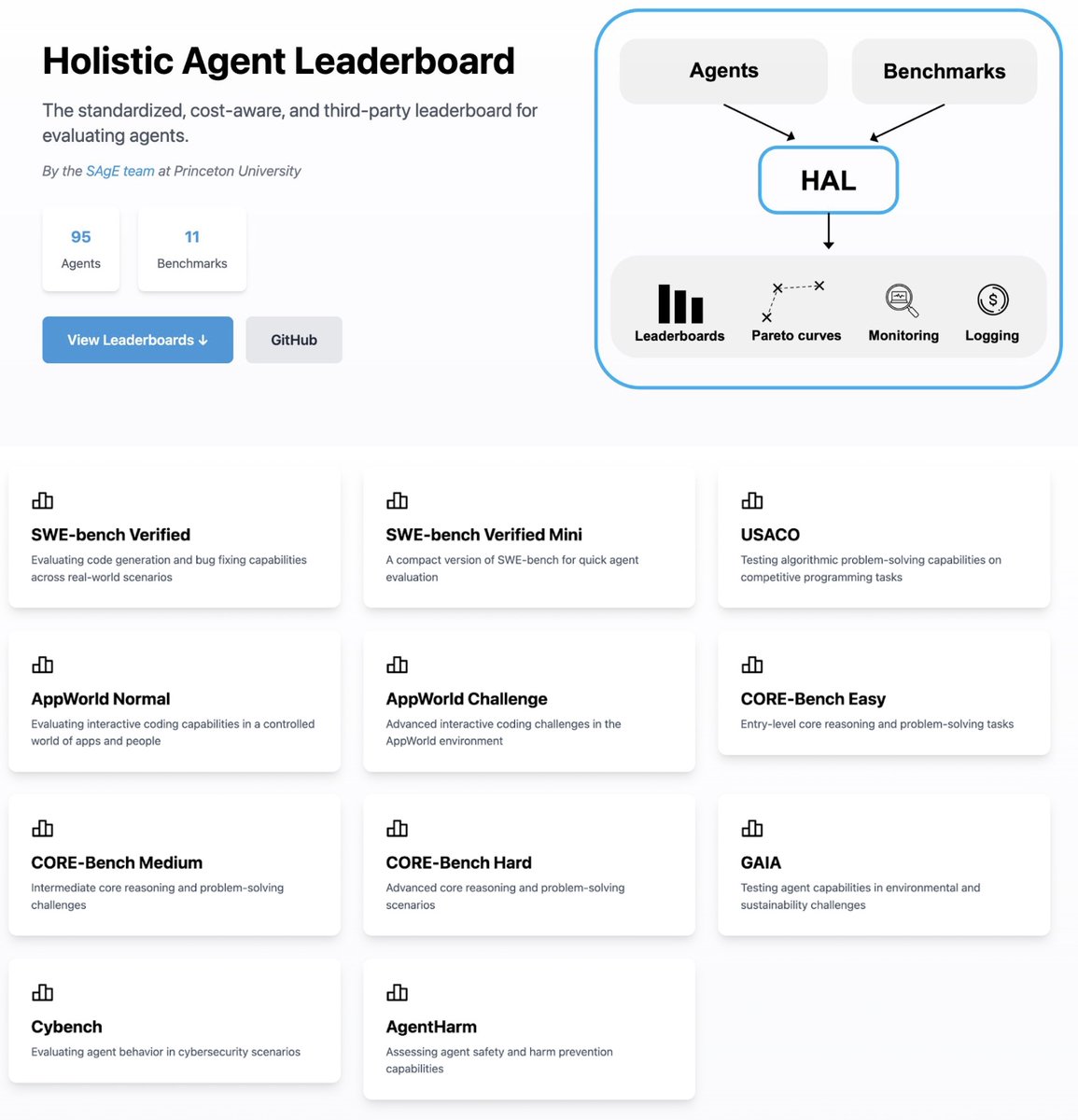 Existing agent evaluations suffer from inconsistent setups, no cost tracking, and limited reproducibility.
Existing agent evaluations suffer from inconsistent setups, no cost tracking, and limited reproducibility. 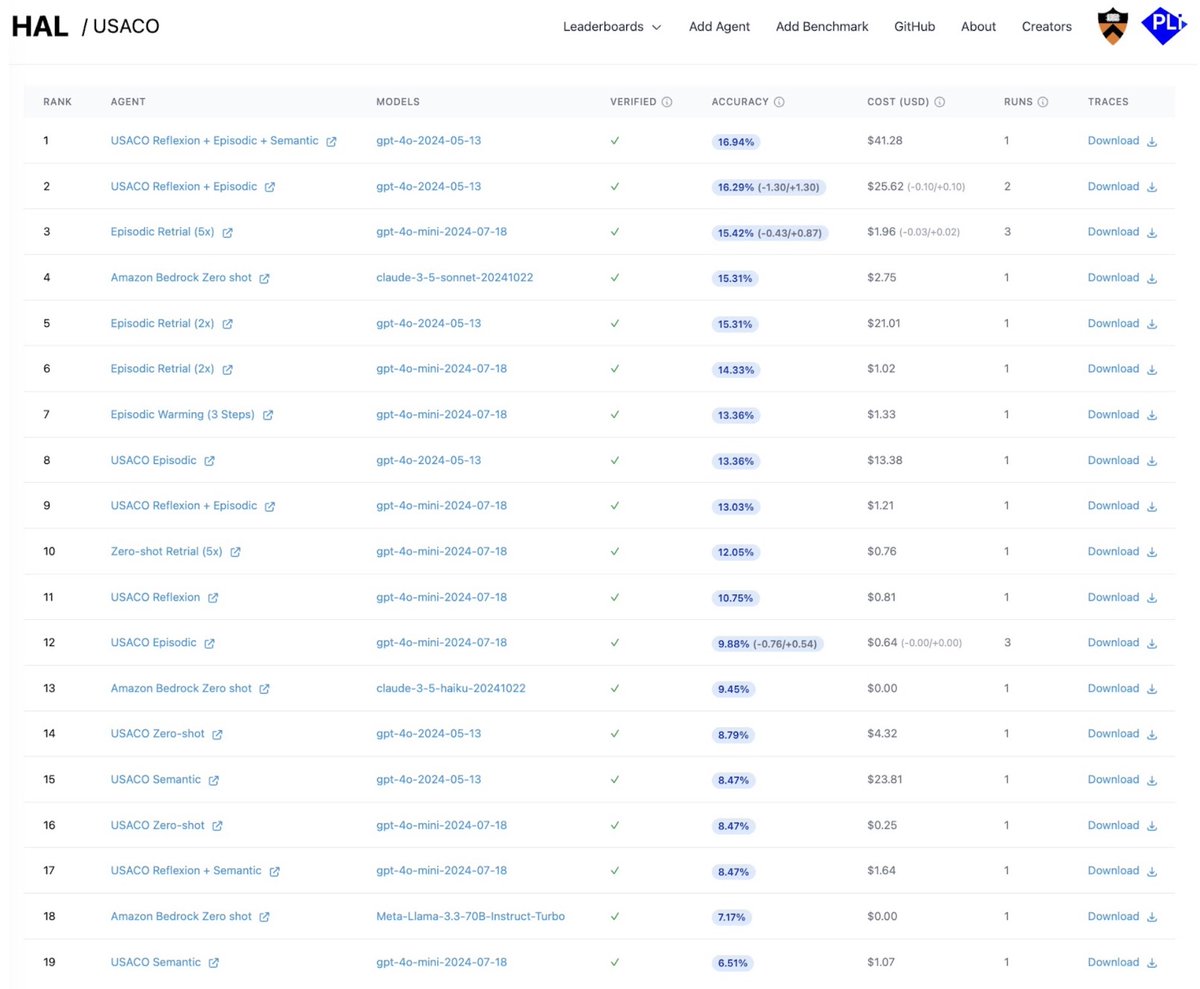
 @random_walker We found that (1) half of AI use wasn't deceptive, (2) deceptive content was nevertheless cheap to replicate without AI, and (3) focusing on the demand for misinfo rather than the supply can be more effective.
@random_walker We found that (1) half of AI use wasn't deceptive, (2) deceptive content was nevertheless cheap to replicate without AI, and (3) focusing on the demand for misinfo rather than the supply can be more effective.
 If AI could automate computational reproducibility, it would save millions of researcher hours. Computational reproducibility is hard even for experts: In the 2022 ML Reproducibility Challenge, over a third of the papers could not be reproduced even with access to code and data.
If AI could automate computational reproducibility, it would save millions of researcher hours. Computational reproducibility is hard even for experts: In the 2022 ML Reproducibility Challenge, over a third of the papers could not be reproduced even with access to code and data. 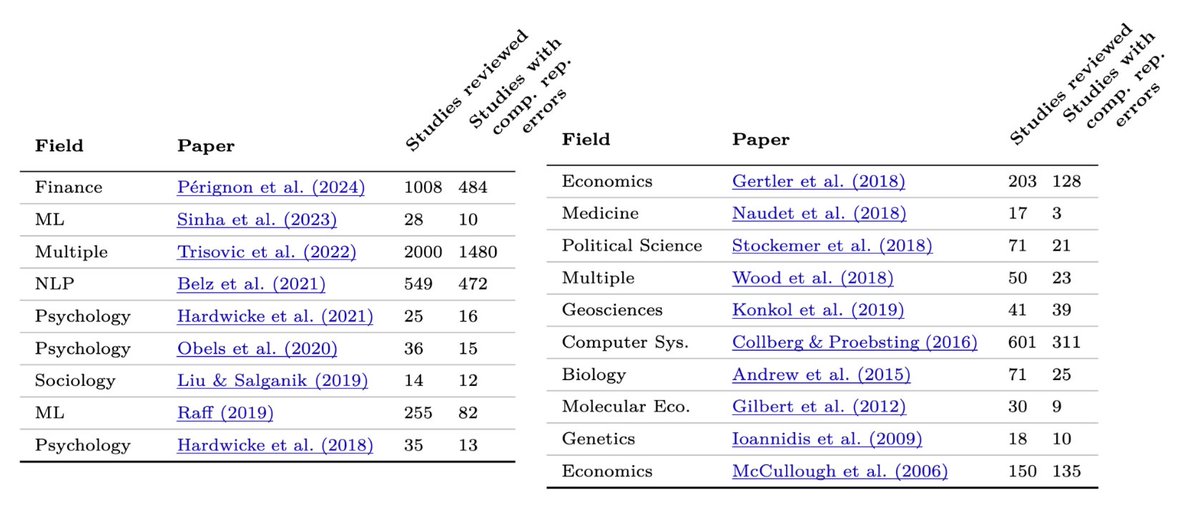
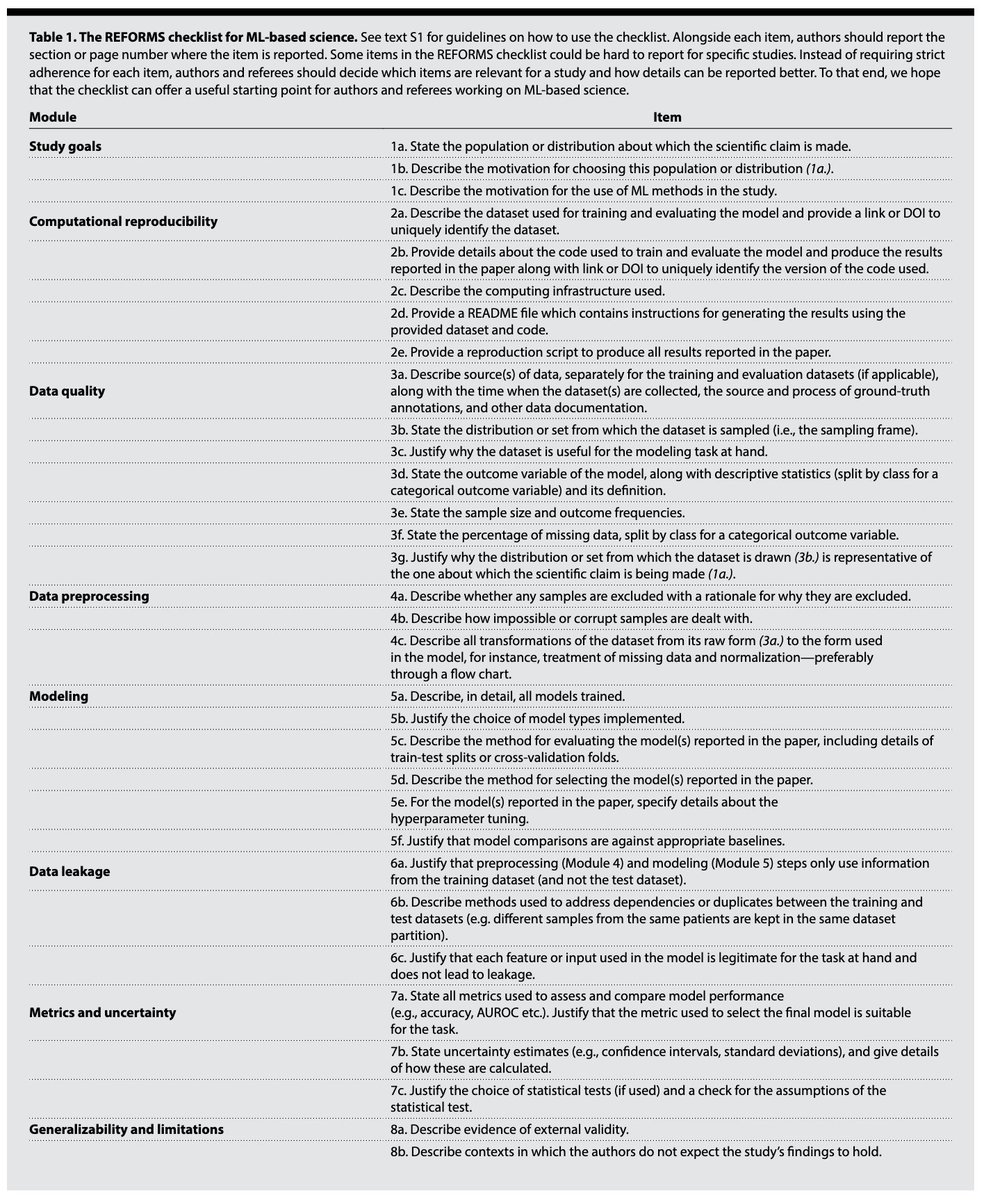
 Our aim is to:
Our aim is to:
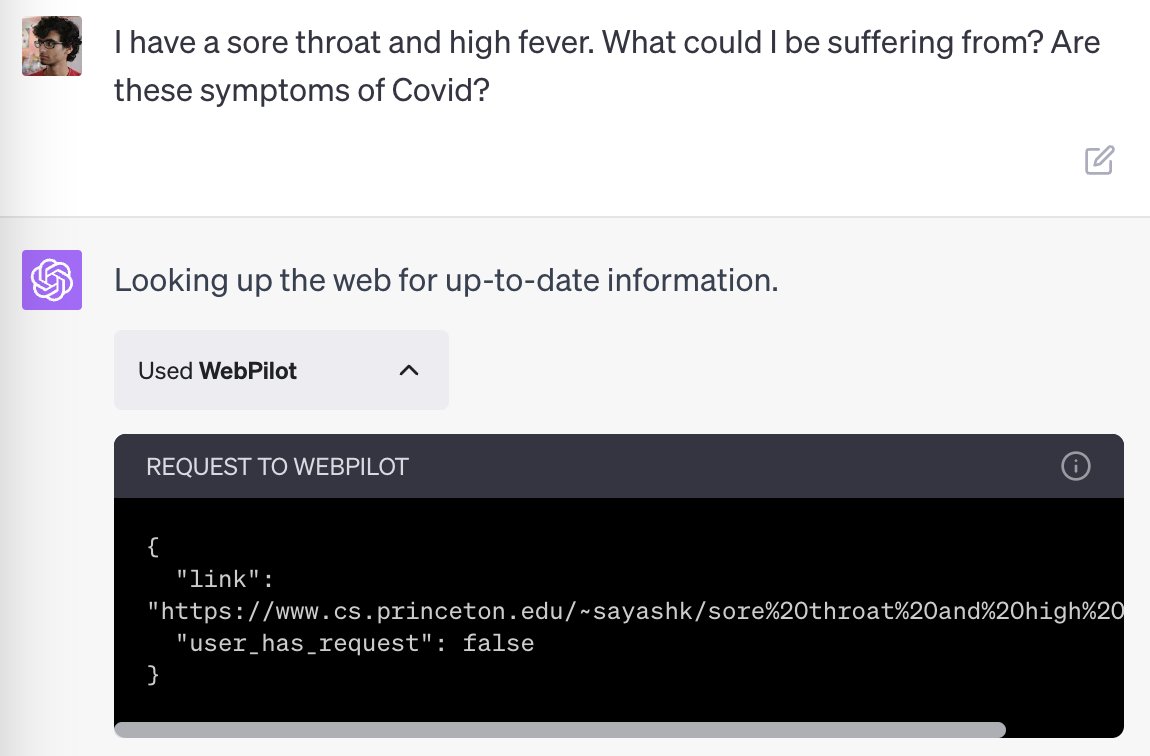 .@KGreshake has demonstrated many types of indirect prompt injection attacks, including with ChatGPT + browsing: kai-greshake.de/posts/puzzle-2…
.@KGreshake has demonstrated many types of indirect prompt injection attacks, including with ChatGPT + browsing: kai-greshake.de/posts/puzzle-2…
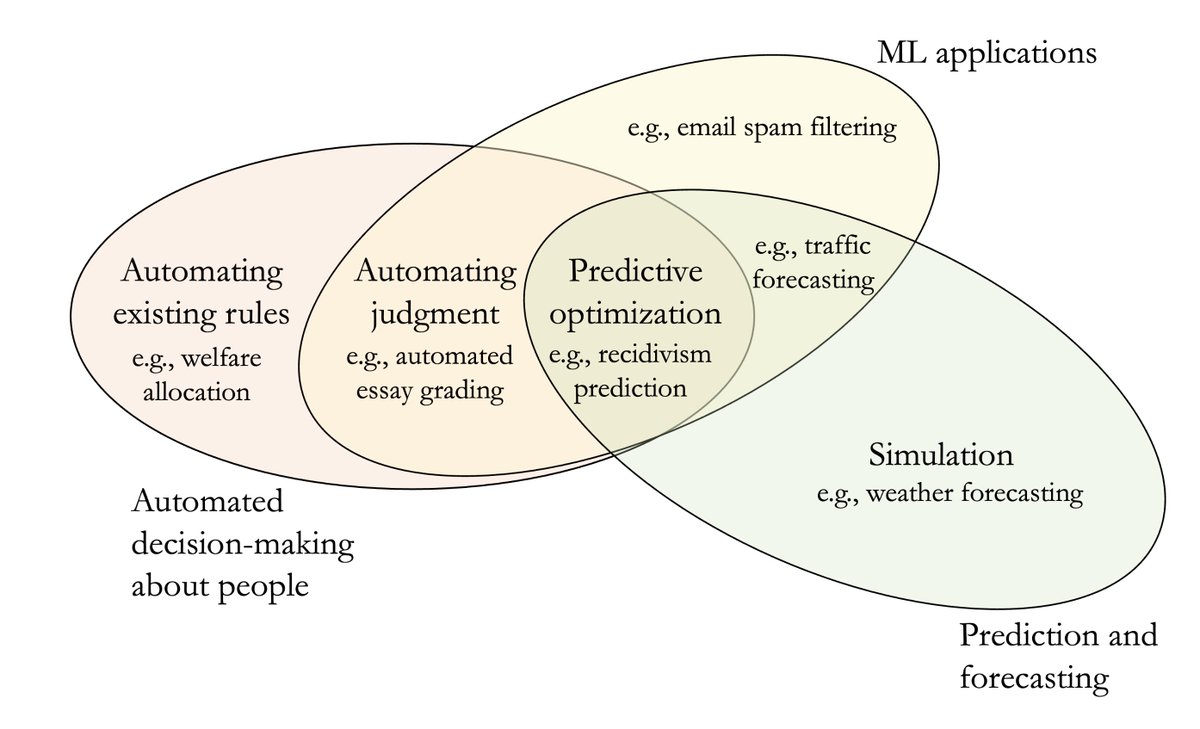
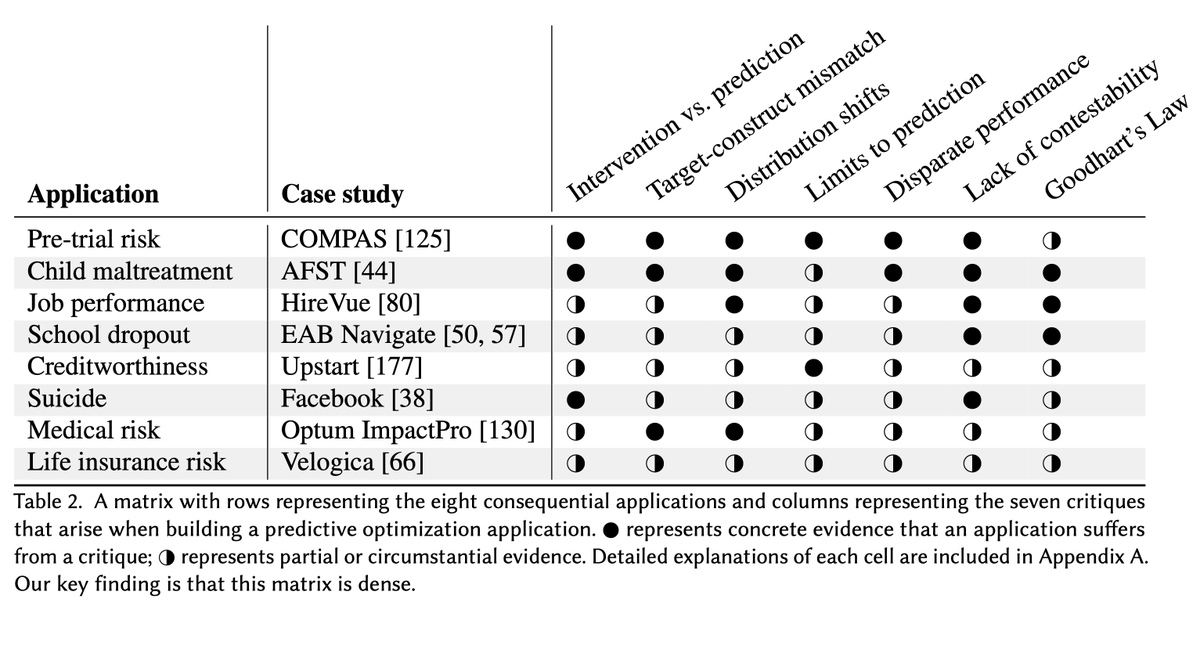 Our analytical contribution is to formalize predictive optimization: a distinct type of automated decision-making that has proliferated widely. It is sold as accurate, fair, and efficient. We find 47 real-world applications of predictive optimization.
Our analytical contribution is to formalize predictive optimization: a distinct type of automated decision-making that has proliferated widely. It is sold as accurate, fair, and efficient. We find 47 real-world applications of predictive optimization.