

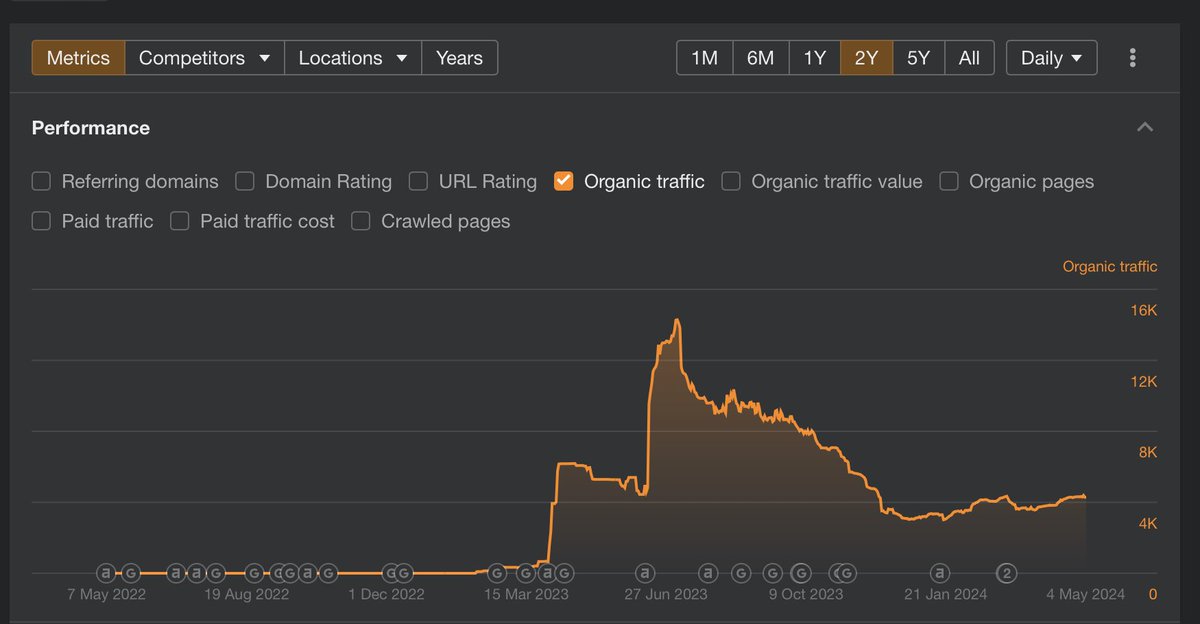
 Character AI has fallen from #2 to #40 in the App Store, mentions of Character AI and similar apps have all fall 30% this year compared to last, and 50%+ of Perplexity traffic comes from SEA and South Africa. Artifact(self funded) shutdown in a year after also blowing up for the first month and tailing off, failing to get “PMF”. Many other gpt wrappers have also had quick spikes before either trying to pivot or the founders move on while handling growth to contractors.
Character AI has fallen from #2 to #40 in the App Store, mentions of Character AI and similar apps have all fall 30% this year compared to last, and 50%+ of Perplexity traffic comes from SEA and South Africa. Artifact(self funded) shutdown in a year after also blowing up for the first month and tailing off, failing to get “PMF”. Many other gpt wrappers have also had quick spikes before either trying to pivot or the founders move on while handling growth to contractors.


 This is going to be a longer thread, but a few initial impressions:
This is going to be a longer thread, but a few initial impressions:
