model measurement @OpenAI. Formerly @MotifAnalytics @Lyft and @Facebook. Keywords: Experiments, Causal Inference, Statistics, Machine Learning, Economics.

 There's a market solution for this.
There's a market solution for this. 



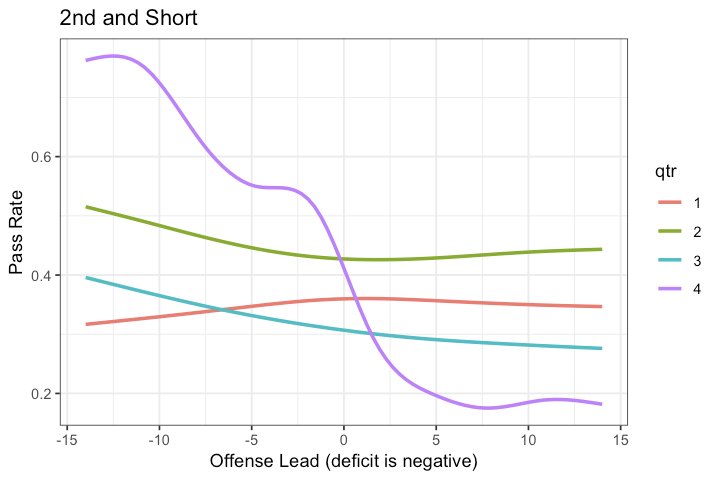
 A coach's tendency in this game situation tells us a lot about what they're optimizing for. (Credit to @bburkeESPN for this idea!) The goal of football isn't to produce 1st downs but to score, may expect >50% pass rate. Most don't unless they are losing and it's late in the game.
A coach's tendency in this game situation tells us a lot about what they're optimizing for. (Credit to @bburkeESPN for this idea!) The goal of football isn't to produce 1st downs but to score, may expect >50% pass rate. Most don't unless they are losing and it's late in the game.