
Patent Analyst 🧐 | Future Strategist | Tech Story Teller | Youtube channel : https://t.co/6hW7CCkxa9
 1. Core Innovations
1. Core Innovations


 만약 이번에 GPT-5.2가 실망스럽고, 크리스마스쯤 나오기로 한 Grok 4.20이 기대 이상의 성능을 보여준다면, 막타는 Grok이 치는 꼴이 될 수도 있겠네요. 🤣🤣🤣
만약 이번에 GPT-5.2가 실망스럽고, 크리스마스쯤 나오기로 한 Grok 4.20이 기대 이상의 성능을 보여준다면, 막타는 Grok이 치는 꼴이 될 수도 있겠네요. 🤣🤣🤣
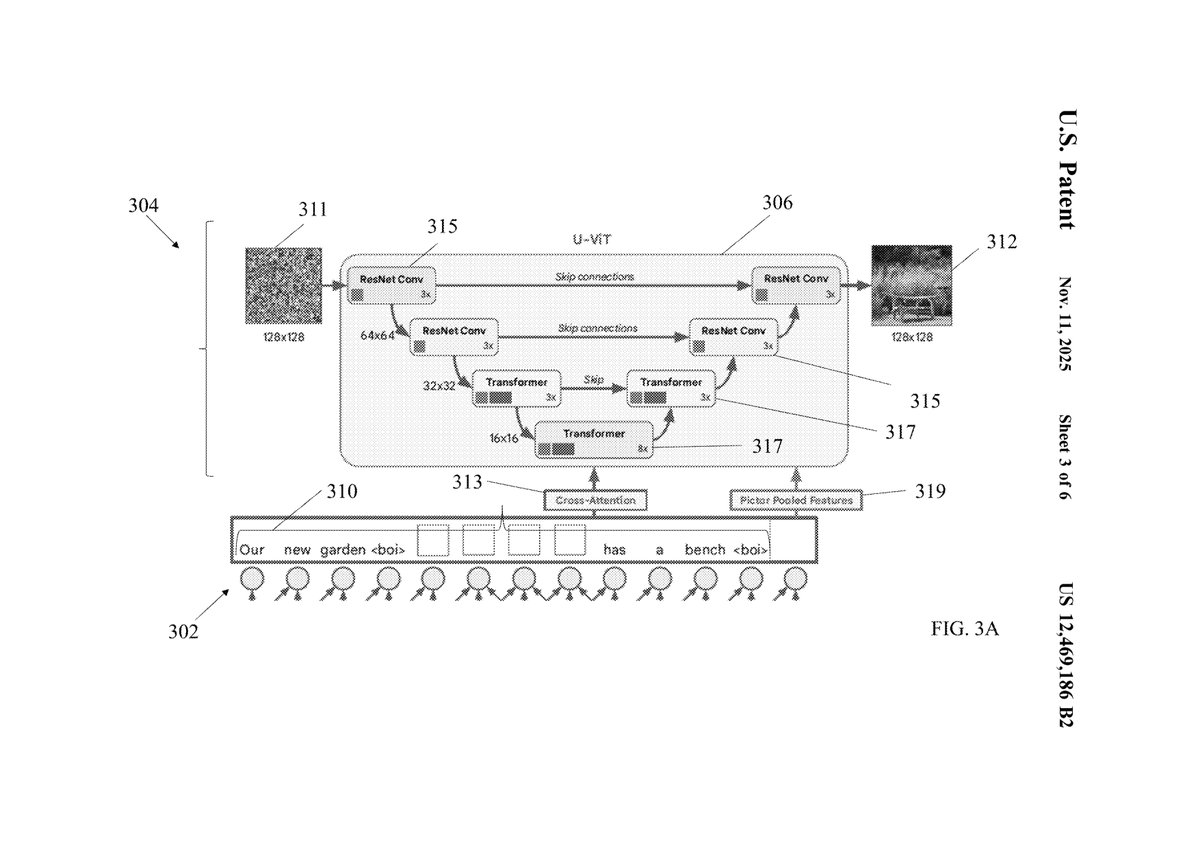 1. Core Innovations
1. Core Innovations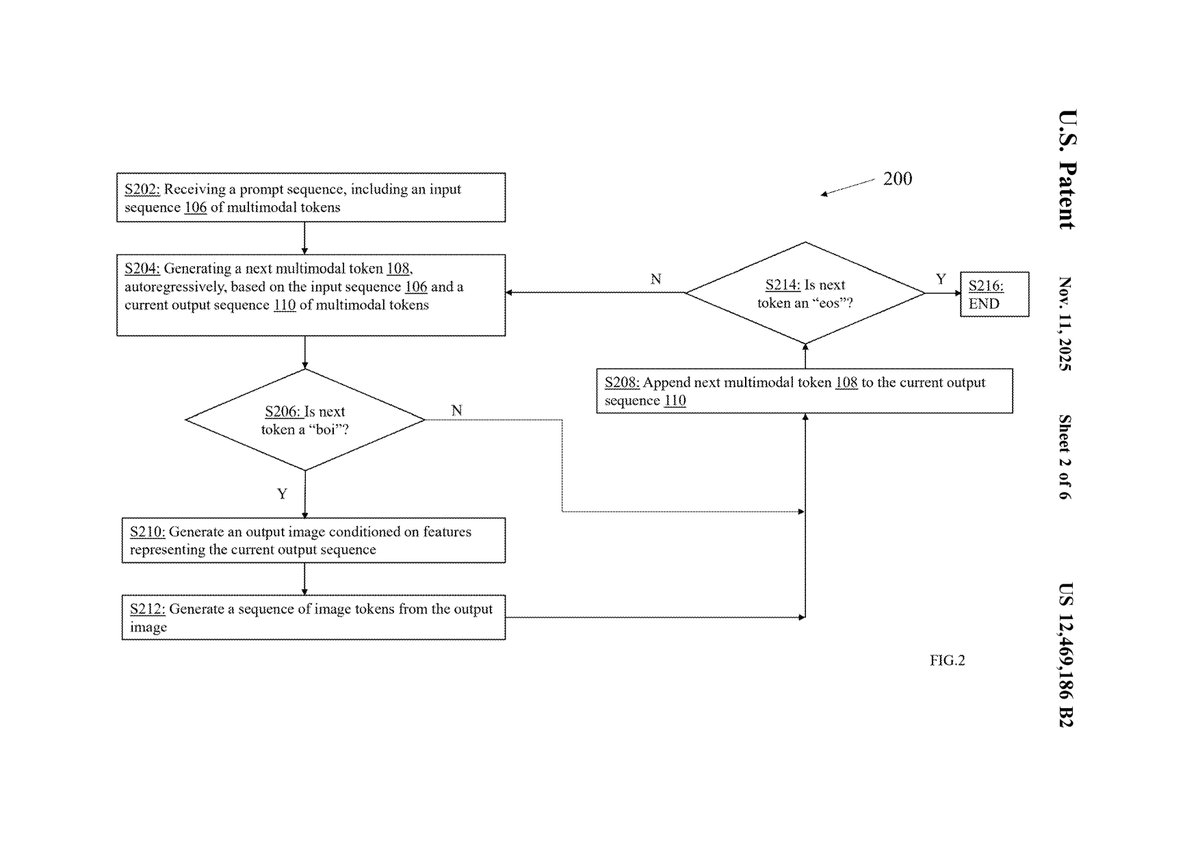
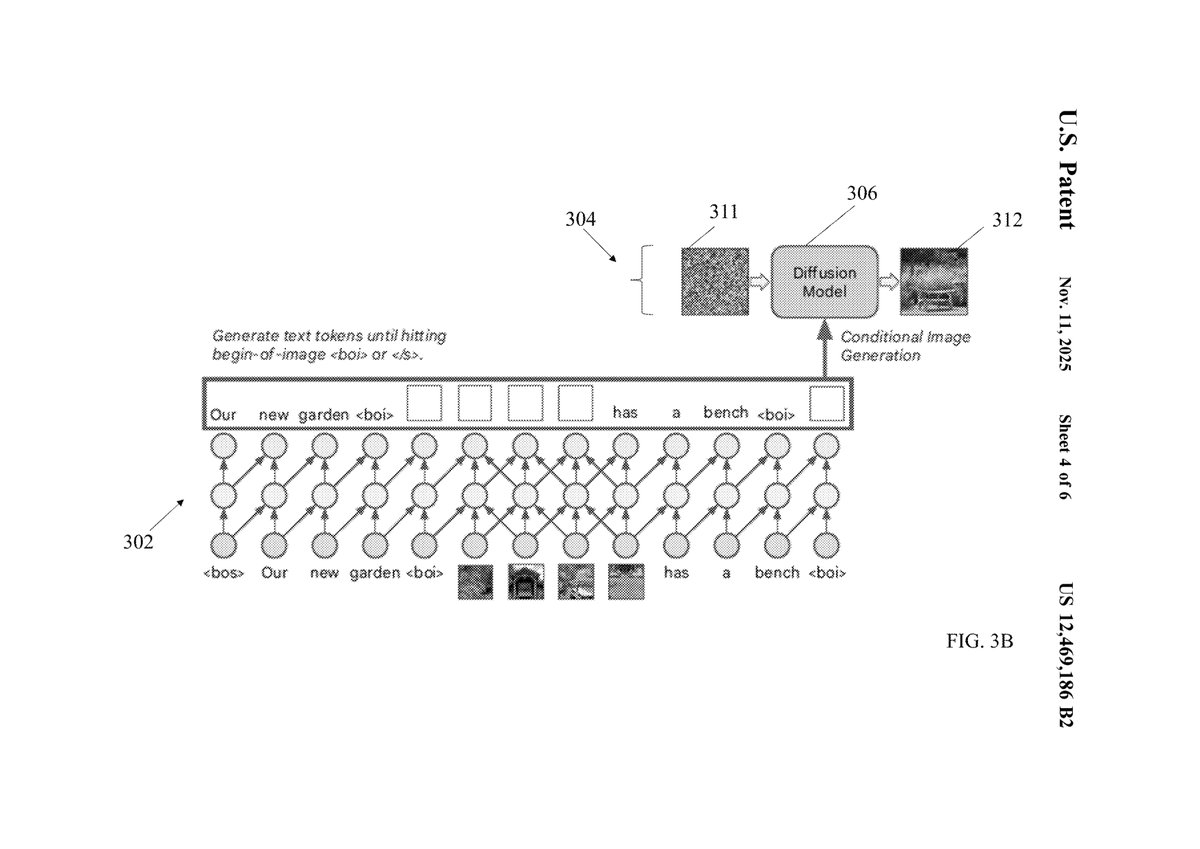
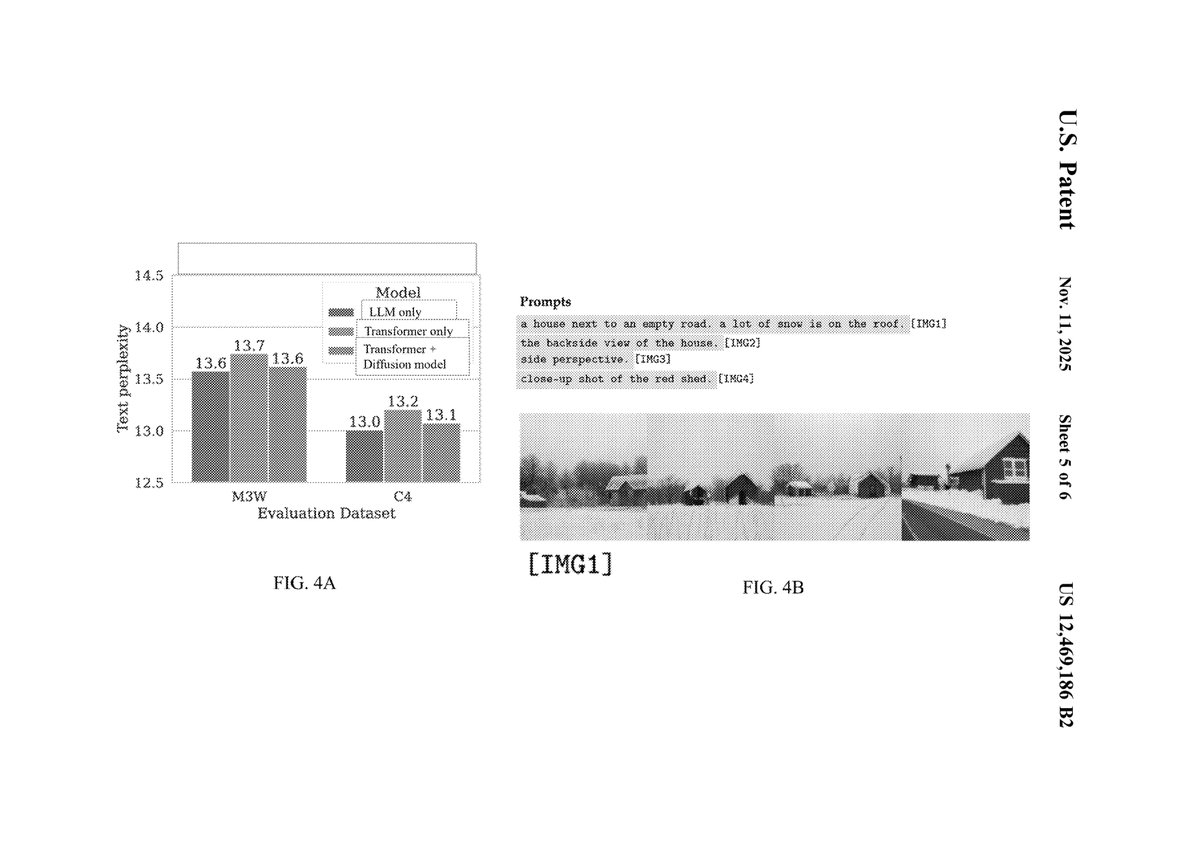
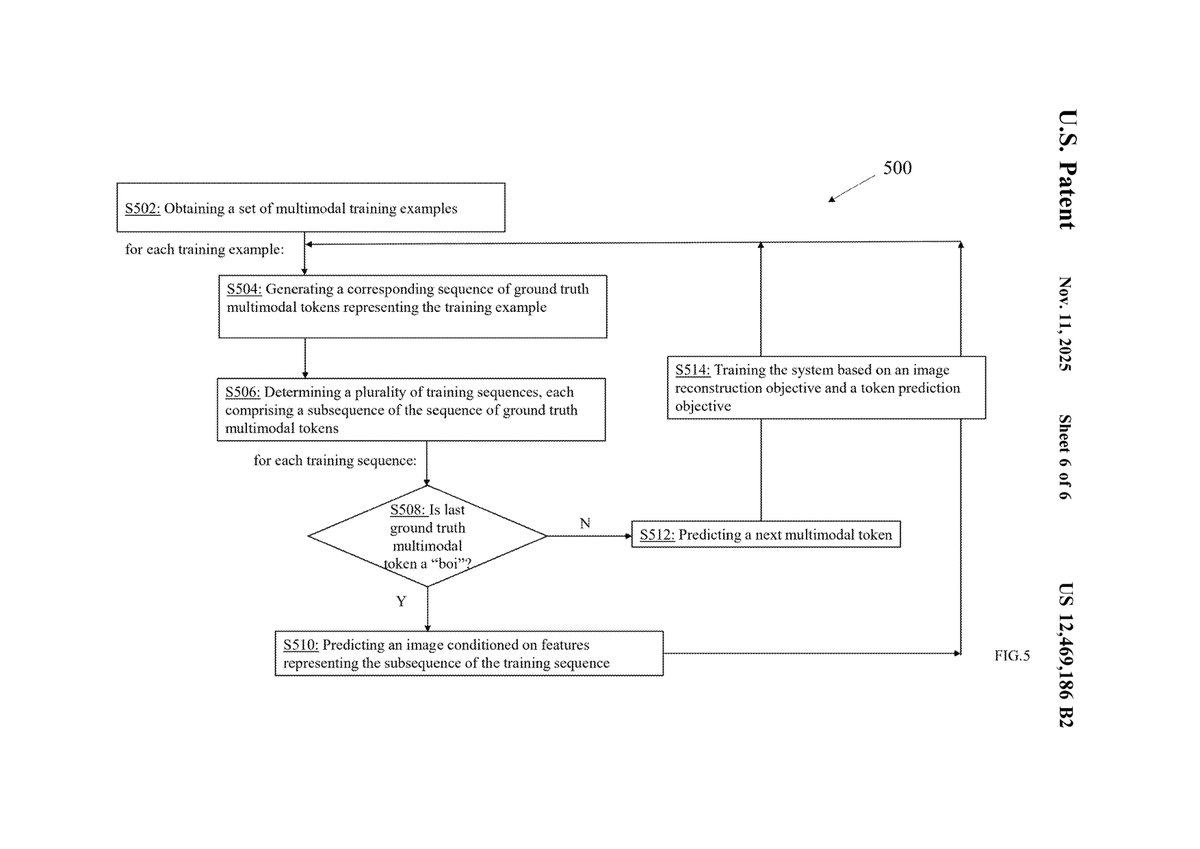




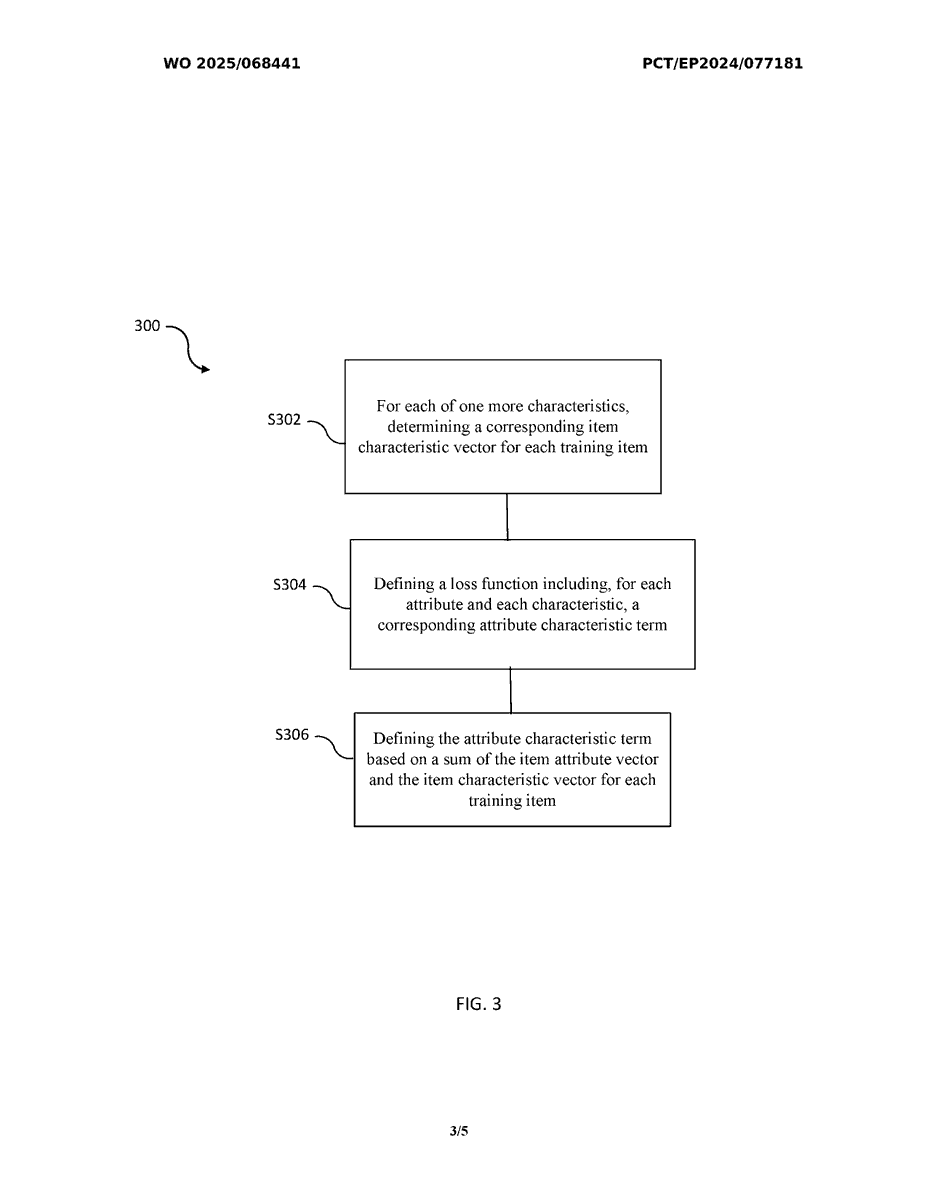
 1. Core Innovations
1. Core Innovations








 어? 👀❗️
어? 👀❗️ 
 1. Core Innovations
1. Core Innovations




 1. Core Innovations
1. Core Innovations

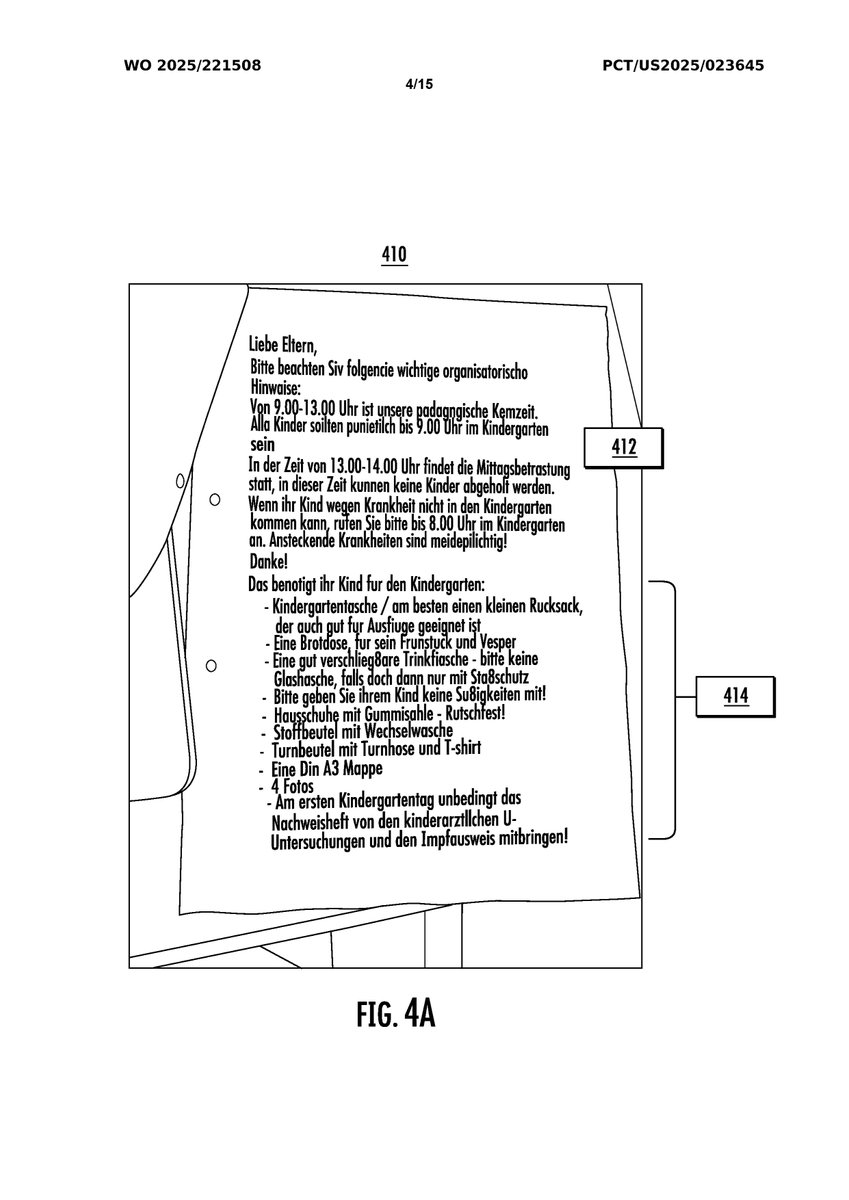
 1. Core Innovations:
1. Core Innovations:



 Free-Standing Lithium Metal Electrode Fabrication Using Direct Elemental Lithium
Free-Standing Lithium Metal Electrode Fabrication Using Direct Elemental Lithium


 1. Core Innovations:
1. Core Innovations:


 Modular Vehicle Architecture for Assembling Vehicles
Modular Vehicle Architecture for Assembling Vehicles
 Tesla and Argonne's High-Voltage Battery Electrolyte Additives
Tesla and Argonne's High-Voltage Battery Electrolyte Additives

 Patent US 2024/0164089 A1 is about a system and method of providing access to compute resources distributed across a group of satellites. This technology aims to provide cloud-services similar to AWS or Azure by utilizing a large-scale satellite constellation like Starlink.
Patent US 2024/0164089 A1 is about a system and method of providing access to compute resources distributed across a group of satellites. This technology aims to provide cloud-services similar to AWS or Azure by utilizing a large-scale satellite constellation like Starlink. 

