
CS PhD @UCLA | prev intern @AIatMeta, @Amazon | interested in RL, diffusion LLMs | bachelors @uoft
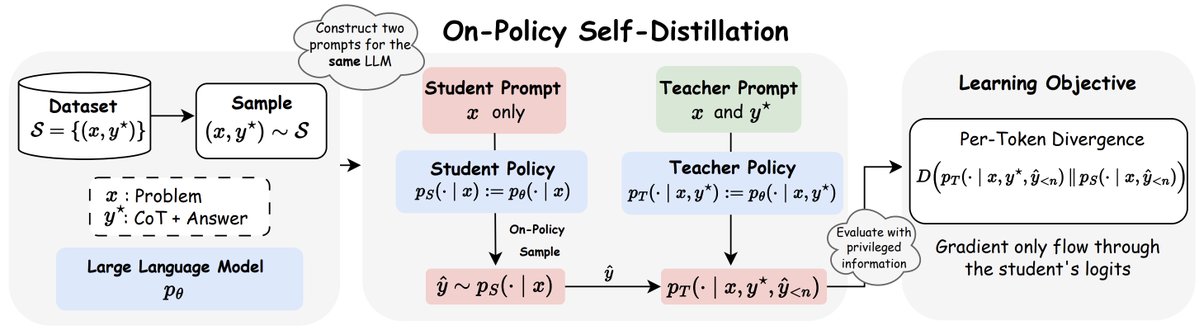 2/n As compared to SFT/off-policy distillation, GRPO, and on-policy distillation, On-Policy Self-Distillation (OPSD) provides training signal that is on-policy, dense, and teacher-free without extensive group sampling cost.
2/n As compared to SFT/off-policy distillation, GRPO, and on-policy distillation, On-Policy Self-Distillation (OPSD) provides training signal that is on-policy, dense, and teacher-free without extensive group sampling cost.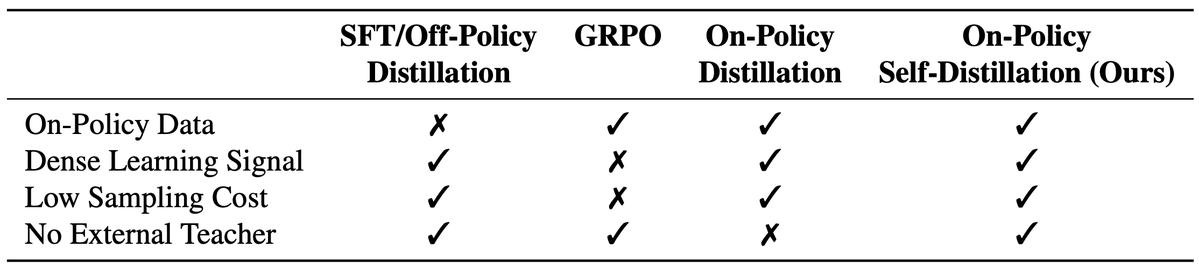
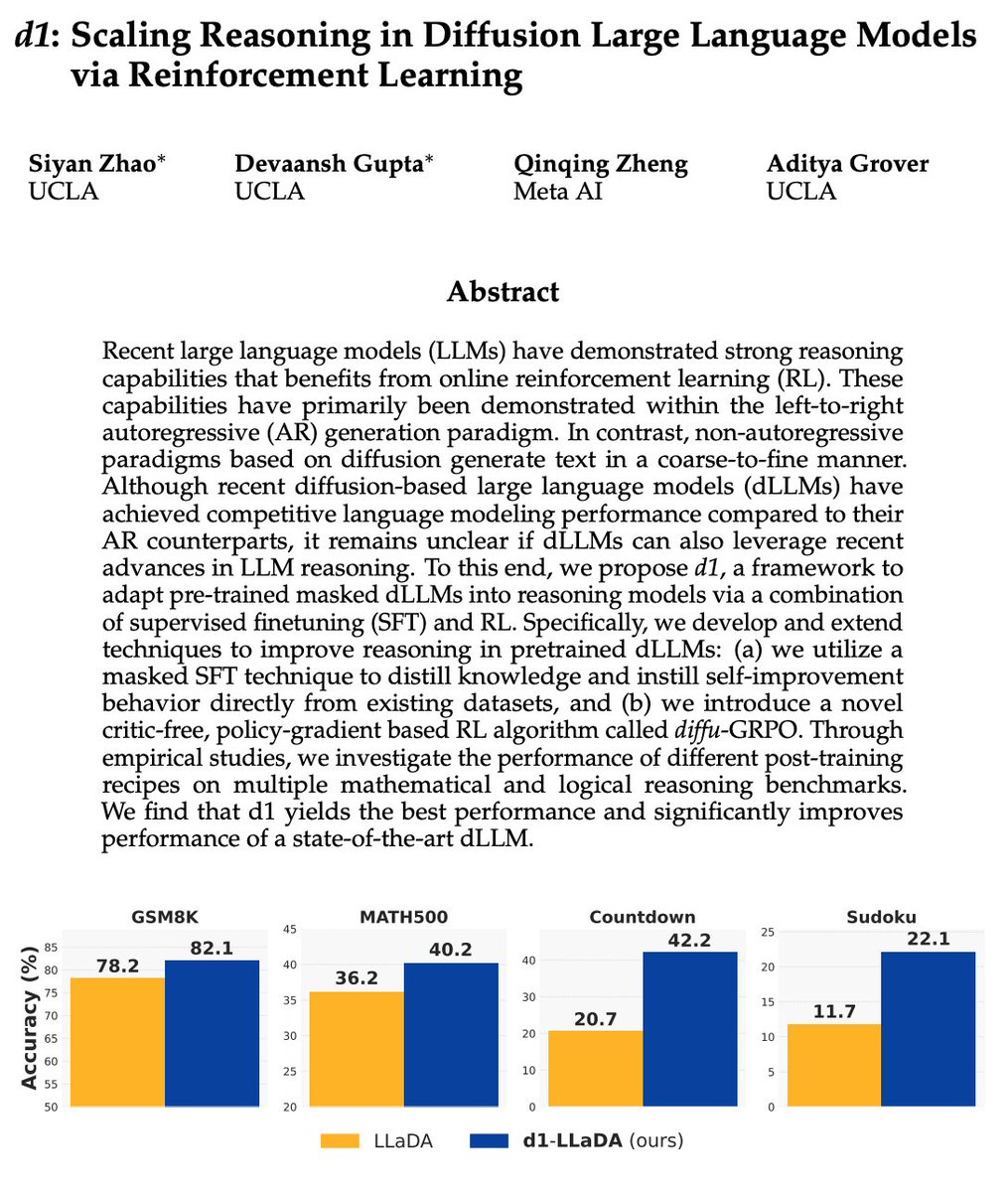 2/n d1 is a two-stage framework to enhance reasoning in masked dLLMs. First, we use masked SFT to learn from reasoning traces in s1k, where models develop self-correction and backtracking behavior 🔍
2/n d1 is a two-stage framework to enhance reasoning in masked dLLMs. First, we use masked SFT to learn from reasoning traces in s1k, where models develop self-correction and backtracking behavior 🔍 