
I like tokens! I lead the Olmo data team at @allen_ai w/ @kylelostat. Open source is fun 🤖☕️🍕🏳️🌈 Opinions sampled from my own stochastic parrot.
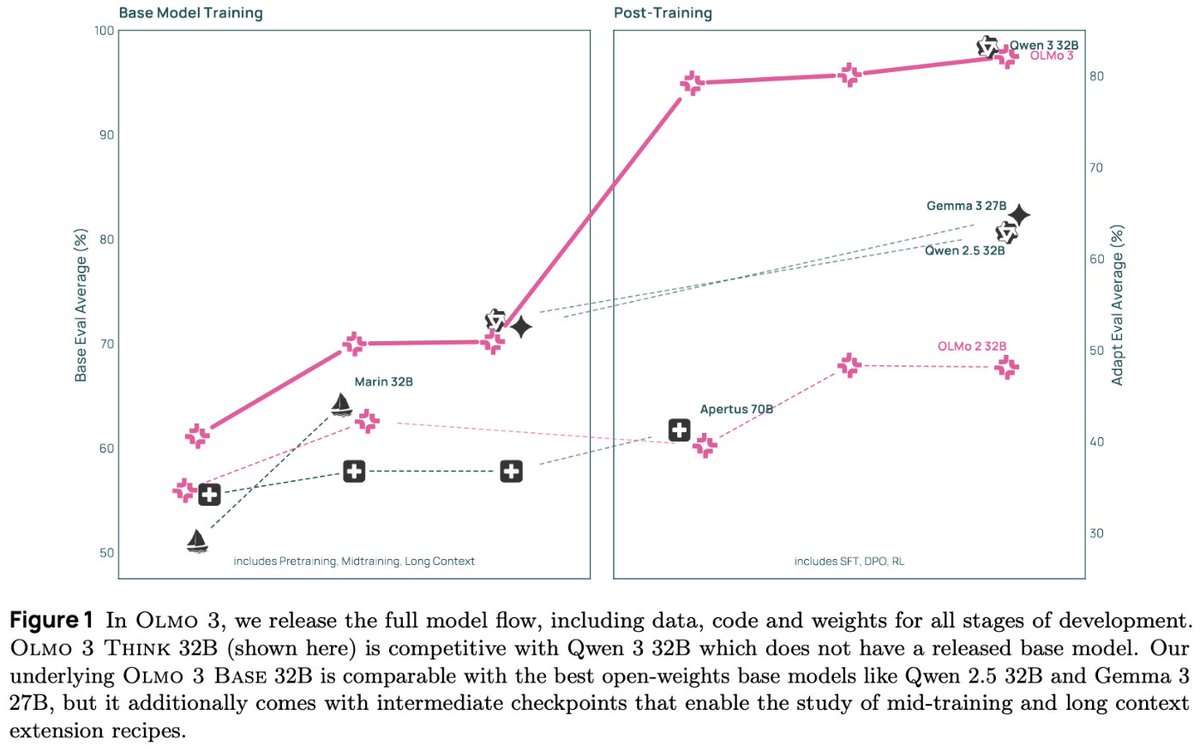 A few highlights from pretraining:
A few highlights from pretraining: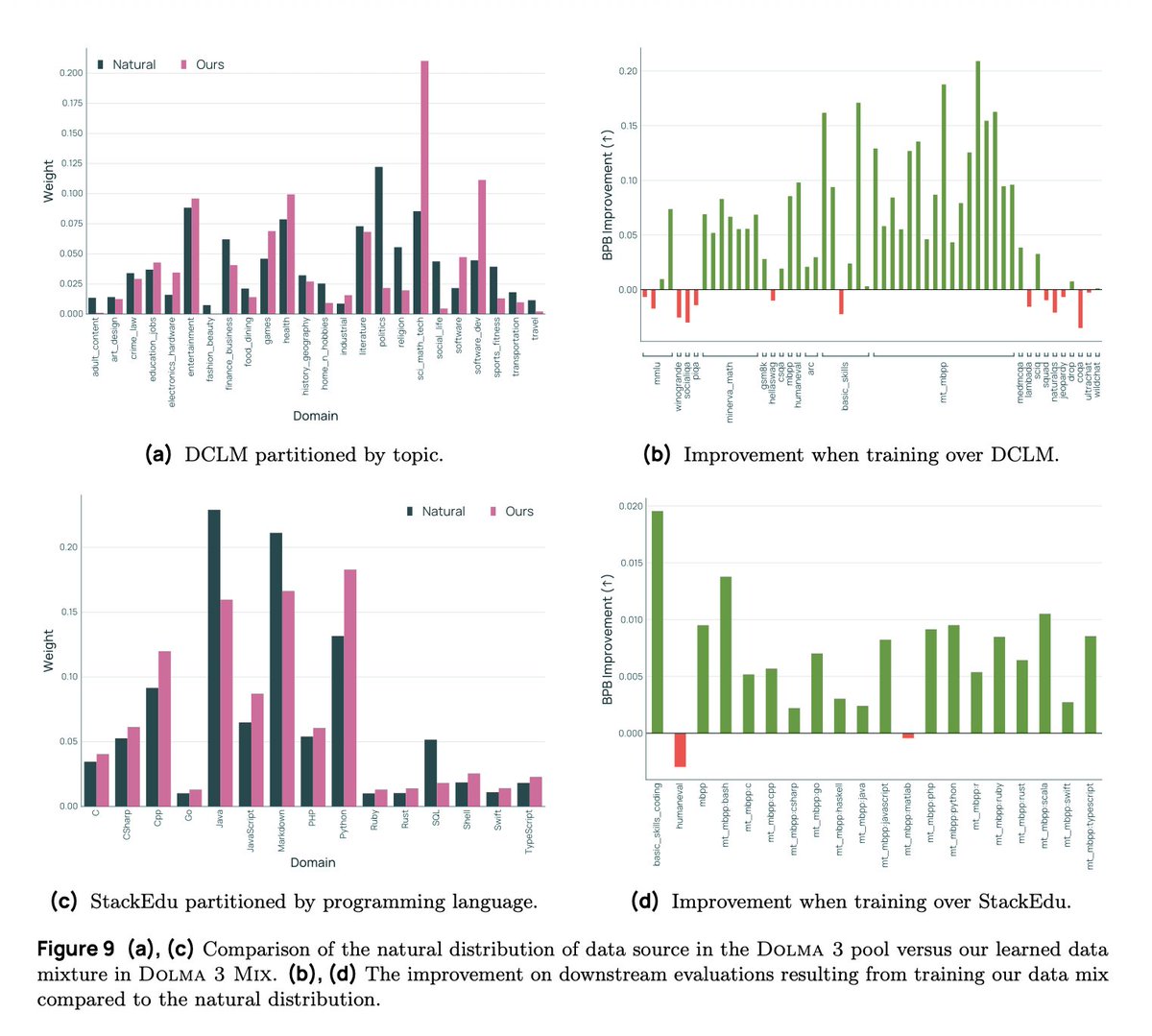
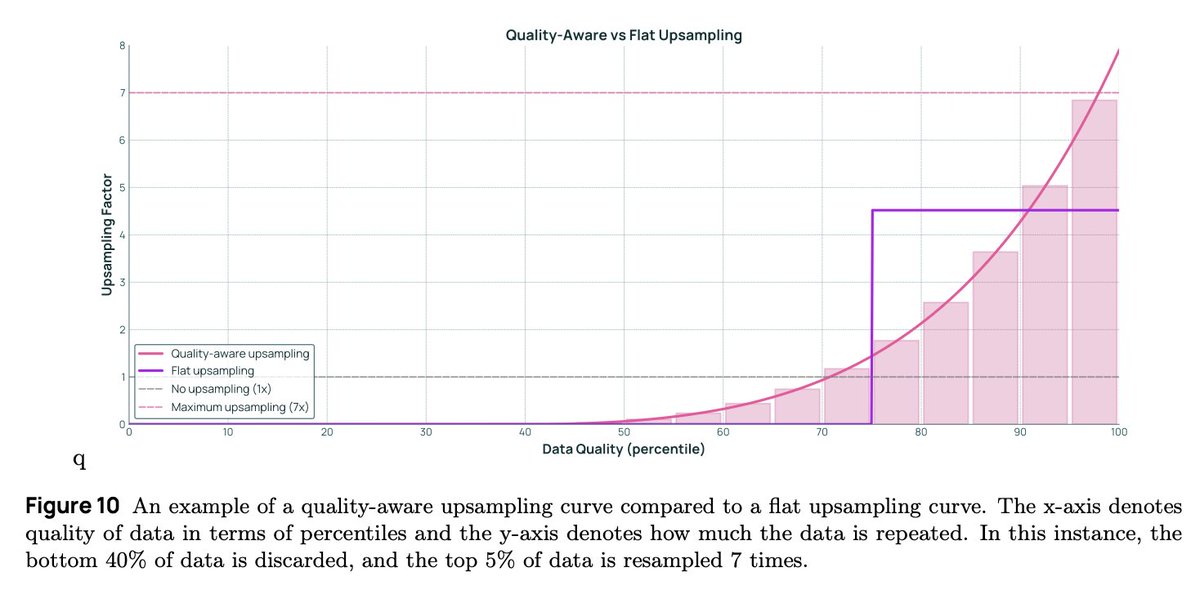
 💪 Stability
💪 Stability



