
 Just yesterday* OpenAI confirmed one of hypotheses: obfuscated reward hacking. GPT knowingly hacks its reward function ‘in the wild’; OpenAI penalizes it; so GPT keeps doing it in secret.
Just yesterday* OpenAI confirmed one of hypotheses: obfuscated reward hacking. GPT knowingly hacks its reward function ‘in the wild’; OpenAI penalizes it; so GPT keeps doing it in secret.
 Training on big web-scraped data can take ages 💤 But lots of compute and time is wasted on redundant and noisy points that are already learned, not learnable, or not even worth learning.
Training on big web-scraped data can take ages 💤 But lots of compute and time is wasted on redundant and noisy points that are already learned, not learnable, or not even worth learning. 
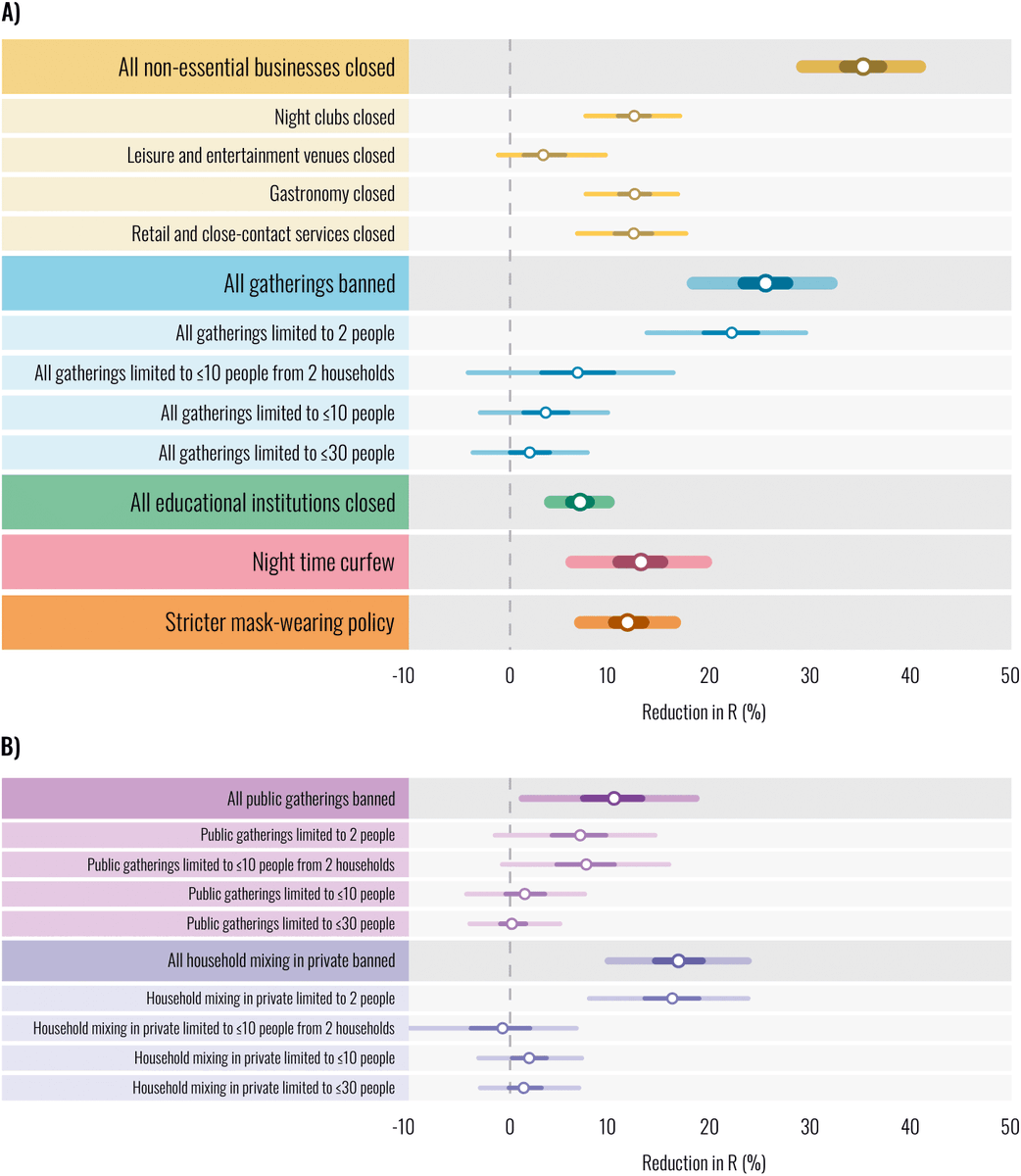 As Europe enters a third wave of COVID, policy-makers balance controlling infections with the sweeping socioeconomic costs of interventions. To do so, we must know how effective individual interventions were at controlling COVID. 2/
As Europe enters a third wave of COVID, policy-makers balance controlling infections with the sweeping socioeconomic costs of interventions. To do so, we must know how effective individual interventions were at controlling COVID. 2/
 Work done with great colleagues from 13 research groups, supervised by @yaringal, @yeewhye, Leonid Chindelevitch. Currently in submission.
Work done with great colleagues from 13 research groups, supervised by @yaringal, @yeewhye, Leonid Chindelevitch. Currently in submission.