AI security @Aisle_Inc | Stanford PhD in AI & Cambridge physics | ex-Anthropic and DeepMind | scientific progress + economic growth

 The key insight:
The key insight: 
 I tried MLP on MNIST and ResNet on CIFAR-10 using the authors' own training & permutation code as discussed in
I tried MLP on MNIST and ResNet on CIFAR-10 using the authors' own training & permutation code as discussed in 

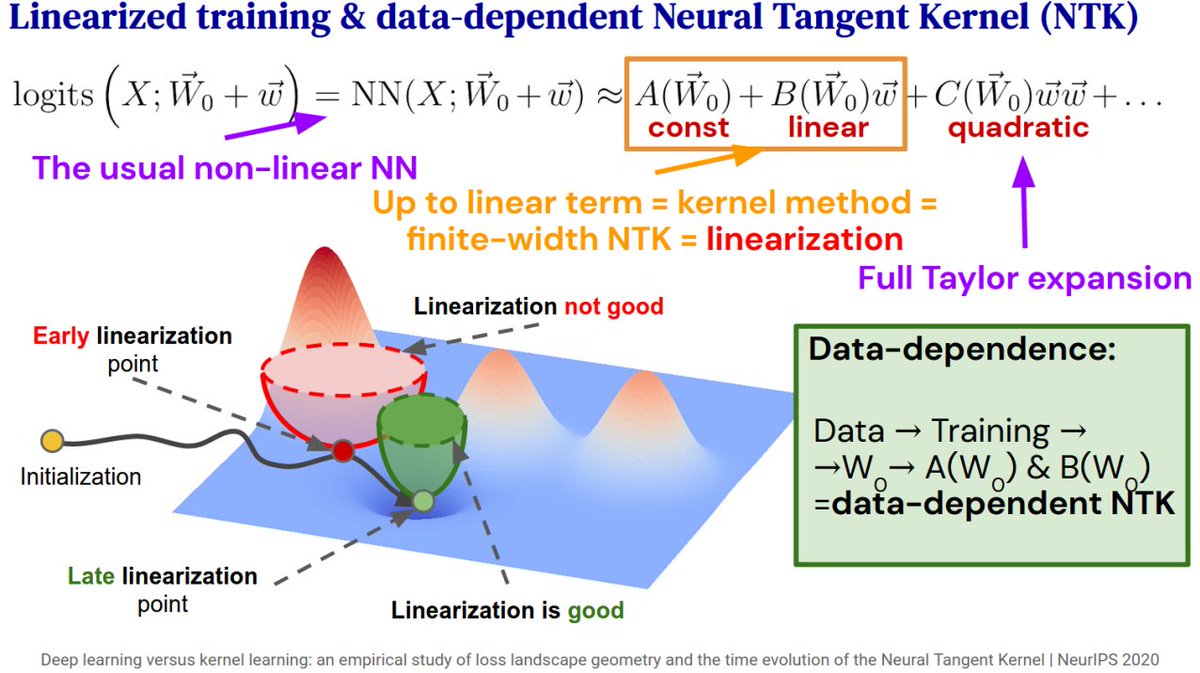
 We Taylor-expand Deep Neural Network logits with respect to their weights at different stages of training & study how well a linearized network trains based on at which epoch it was expanded. Early expansions train poorly, but even slightly into training they do very well! 2/6
We Taylor-expand Deep Neural Network logits with respect to their weights at different stages of training & study how well a linearized network trains based on at which epoch it was expanded. Early expansions train poorly, but even slightly into training they do very well! 2/6