
 The idea is very simple: train an actor and critic over action chunks (short sequences of actions). The setup is "offline to online": pretrain with offline RL on offline data, then run online exploration. It helps a lot (compare red line for QC vs blue lines for prior methods).
The idea is very simple: train an actor and critic over action chunks (short sequences of actions). The setup is "offline to online": pretrain with offline RL on offline data, then run online exploration. It helps a lot (compare red line for QC vs blue lines for prior methods). 




 Basic question: if I learn a model (e.g., dynamics model for MPC, value function, BC policy) on data, will that model be accurate when I run it (e.g., to control my robot)? It might be wrong if I go out of distribution, LDMs aim to provide a constraint so they don't do this.
Basic question: if I learn a model (e.g., dynamics model for MPC, value function, BC policy) on data, will that model be accurate when I run it (e.g., to control my robot)? It might be wrong if I go out of distribution, LDMs aim to provide a constraint so they don't do this. 



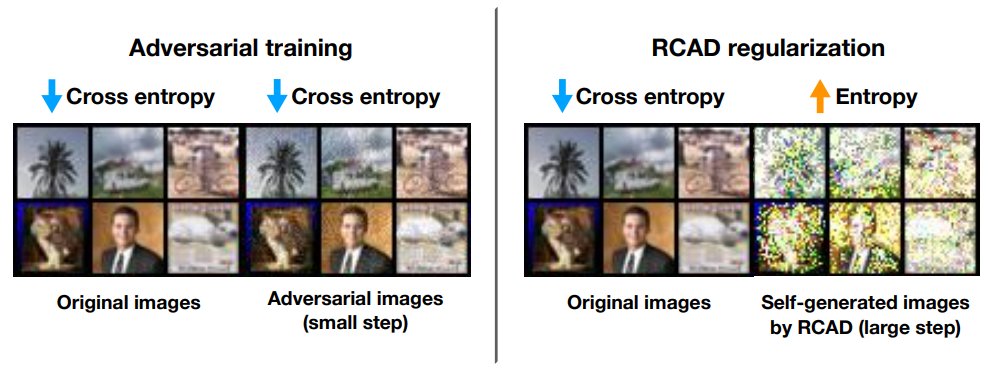 The idea is to use *very* aggressive adversarial training, generating junk images for which model predicts wrong label, then train the model to minimize its confidence on them. Since we don't need "true" labels for these images, we make *much* bigger steps than std adv training.
The idea is to use *very* aggressive adversarial training, generating junk images for which model predicts wrong label, then train the model to minimize its confidence on them. Since we don't need "true" labels for these images, we make *much* bigger steps than std adv training. 



 Let's consider "success/failure" tasks where there is a reward at the end (+1 or 0) if you succeed. In general, both BC and offline RL get O(H) regret (i.e., linear in the horizon) if provided with optimal demonstration data. But there are some important special cases!
Let's consider "success/failure" tasks where there is a reward at the end (+1 or 0) if you succeed. In general, both BC and offline RL get O(H) regret (i.e., linear in the horizon) if provided with optimal demonstration data. But there are some important special cases! 





 Straight from the annals of "I can't believe it's not broken": if all unlabeled data gets a reward of 0, we get more samples (lower sampling error) but also reward bias. We can analyze theoretically what this does to the performance of RL, with a perf bound that has 3 terms:
Straight from the annals of "I can't believe it's not broken": if all unlabeled data gets a reward of 0, we get more samples (lower sampling error) but also reward bias. We can analyze theoretically what this does to the performance of RL, with a perf bound that has 3 terms: 
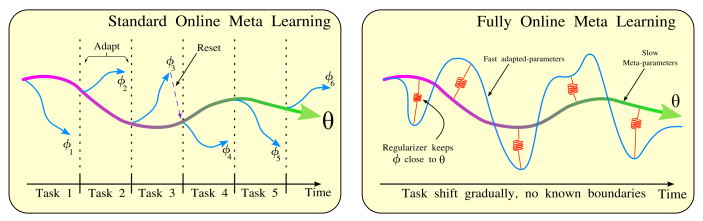 Standard MAML is batch mode, but in reality we might observe training samples in sequence, and the task might shift, suddenly or gradually. We want to use each datapoint *both* to improve our model *and* to learn how to learn more quickly for when the task changes.
Standard MAML is batch mode, but in reality we might observe training samples in sequence, and the task might shift, suddenly or gradually. We want to use each datapoint *both* to improve our model *and* to learn how to learn more quickly for when the task changes.
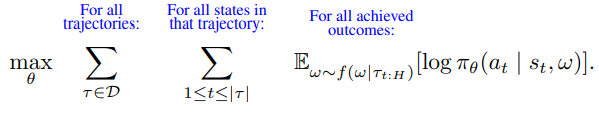


 The "Maxwell's demon" thought exercise describes how information translates into energy. In one version, the "demon" opens a gate when a particle approaches from one side, but not the other, sorting them into one chamber (against the diffusion gradient). This lowers entropy.
The "Maxwell's demon" thought exercise describes how information translates into energy. In one version, the "demon" opens a gate when a particle approaches from one side, but not the other, sorting them into one chamber (against the diffusion gradient). This lowers entropy. 
